給Java同仁單點的AI"開胃菜"—搭建一個自己的本地問答系統
本文主要是目標是講解如何在本地搭建一個簡易的AI問答系統,主要用Java來實現,也有一些簡單的Python知識;網上很多例子都是以 ChatGPT來講解的,但因為它對國內訪問有限制,OpenAI連接太麻煩,又要虛擬賬號注冊賬號啥的,第一步就勸退了,所以選擇了 llama 和 qwen 替代,但是原理都是一樣的。
相關概念了解:
(一)大語言模型 LLM
大型語言模型(LLM,Large Language Models),是近年來自然語言處理(NLP)領域的重要進展。這些模型由于其龐大的規模和復雜性,在處理和生成自然語言方面展現了前所未有的能力。
關于LLM的一些關鍵點:
1.定義
?大模型通常指的是擁有大量參數的深度學習模型,這些模型可能包含數十億至數萬億的參數。
?LLM是大模型的一個子類,專門設計用于處理和理解自然語言,它們能夠模仿人類語言的生成和理解過程。
2.架構
?LLM通常基于Transformer架構,這是一種使用自注意力機制(self-attention mechanism)的序列模型,它由多個編碼器和解碼器層組成,每個層包含多頭自注意力機制和前饋神經網絡。
3.訓練
?這些模型在大規模文本數據集上進行訓練,這使得它們能夠學習到語言的復雜結構,包括語法、語義、上下文關系等。
?訓練過程通常涉及大量的計算資源,包括GPU集群和海量的數據存儲。
4.應用
?LLM可以應用于各種自然語言處理任務,包括但不限于文本生成、問答、翻譯、摘要、對話系統等。
?它們還展示了在few-shot和zero-shot學習場景下的能力,即在少量或沒有額外訓練數據的情況下,模型能夠理解和執行新任務。
5.發展趨勢
?學術研究和工業界都在探索LLM的邊界,包括如何更有效地訓練這些模型,以及如何使它們在不同領域和任務中更具適應性。
?開源和閉源模型的競爭也在加劇,推動了模型的持續創新和改進。
6.學習路徑
?對于那些希望深入了解LLM的人來說,可以從學習基本的Transformer模型開始,然后逐漸深入到更復雜的模型,如GPT系列、BERT、LLaMA、Alpaca等,國內的有qwen(通義千問)、文心一言、訊飛星火、華為盤古、言犀大模型(ChatJd)等 。
7.社區資源
?Hugging Face等平臺提供了大量的開源模型和工具,可以幫助研究人員和開發者快速上手和應用LLM。
LLM的出現標志著NLP領域的一個新時代,它們不僅在學術研究中產生了深遠的影響,也在商業應用中展現出了巨大的潛力。
(二)Embedding
在自然語言處理(NLP)和機器學習領域中,"embedding" 是一種將文本數據轉換成數值向量的技術。這種技術將單詞、短語、句子甚至文檔映射到多維空間中的點,使得這些點在數學上能夠表示它們在語義上的相似性或差異。
Embeddings 可以由預訓練模型生成,也可以在特定任務中訓練得到。常見的 embedding 方法包括:
1.Word2Vec:由 Google 提出,通過上下文預測目標詞(CBOW)或通過目標詞預測上下文(Skip-gram)來訓練詞向量。
2.GloVe:全球向量(Global Vectors for Word Representation),通過統計詞共現矩陣來優化詞向量。
3.FastText:Facebook 研究院提出的一種方法,它基于詞 n-gram 來構建詞向量,適用于稀少詞和未見過的詞。
4.BERT:基于 Transformer 架構的預訓練模型,可以生成上下文相關的詞嵌入,即“動態”詞嵌入。
5.ELMo:利用雙向 LSTM 語言模型生成的詞嵌入,同樣考慮了上下文信息。
6.Sentence Transformers:這是 BERT 的一種變體,專門設計用于生成句子級別的嵌入。
Embeddings的主要優點在于它們能夠捕捉詞匯之間的復雜關系,如同義詞、反義詞以及詞義的細微差別。此外,它們還能夠處理多義詞問題,即一個詞在不同上下文中可能有不同的含義。
在實際應用中,embeddings 被廣泛用于多種 NLP 任務,如文本分類、情感分析、命名實體識別、機器翻譯、問答系統等。通過使用 embeddings,機器學習模型能夠理解和處理自然語言數據,從而做出更加準確和有意義的預測或決策。
(三)向量數據庫
向量數據庫是一種專門設計用于存儲和查詢高維向量數據的數據庫系統。這種類型的數據庫在處理非結構化數據,如圖像、文本、音頻和視頻的高效查詢和相似性搜索方面表現出色。與傳統的數據庫管理系統(DBMS)不同,向量數據庫優化了對高維空間中向量的存儲、索引和檢索操作。
以下是向量數據庫的一些關鍵特點和功能:
1.高維向量存儲:向量數據庫能夠高效地存儲和管理大量的高維向量數據,這些向量通常是由深度學習模型(如BERT、ResNet等)從原始數據中提取的特征。
2.相似性搜索:它們提供了快速的近似最近鄰(ApproximateNearest Neighbor, ANN)搜索,能夠在高維空間中找到與查詢向量最相似的向量集合。
3.向量索引:使用特殊的數據結構,如樹形結構(如KD樹)、哈希表、圖結構或量化方法,以加速向量的檢索過程。
4.混合查詢能力:許多向量數據庫還支持結合向量查詢和結構化數據查詢,這意味著除了向量相似性搜索之外,還可以進行SQL風格的查詢來篩選結構化屬性。
5.擴展性和容錯性:高效的數據分布和復制策略,使得向量數據庫可以水平擴展,以處理海量數據,并且具備數據冗余和故障恢復能力。
6.實時更新:允許動態添加和刪除向量數據,支持實時更新,這對于不斷變化的數據集尤其重要。
7.云原生設計:許多現代向量數據庫采用云原生架構,可以輕松部署在云端,利用云服務的彈性計算資源。
向量數據庫在多個領域得到應用,包括推薦系統、圖像和視頻檢索、自然語言處理(NLP)以及生物信息學。一些知名的向量數據庫項目包括FAISS(由Facebook AI Research開發)、Pinecone、Weaviate、Qdrant、Milvus等。
(四)RAG
文章題目中的 "智能問答" 其實專業術語 叫 RAG;
在大模型(尤其是大型語言模型,LLMs)中,RAG指的是“Retrieval-Augmented Generation”,即檢索增強生成。這是一種結合了檢索(Retrieval)和生成(Generation)技術的人工智能方法,主要用于增強語言模型在處理需要外部知識或實時信息的任務時的表現;
RAG即檢索增強生成。這是一種結合了檢索(Retrieval)和生成(Generation)兩種技術的人工智能模型架構。RAG 最初由 Facebook AI 在 2020 年提出,其核心思想是在生成式模型中加入一個檢索組件,以便在生成過程中利用外部知識庫中的相關文檔或片段。
在傳統的生成模型中,如基于Transformer的模型,輸出完全依賴于模型的內部知識,這通常是在大規模語料庫上進行預訓練得到的。然而,這些模型可能無法包含所有特定領域或最新更新的信息,尤其是在處理專業性較強或時效性較高的問題時。
RAG 架構通過從外部知識源檢索相關信息來增強生成過程。當模型需要生成響應時,它會首先查詢一個文檔集合或知識圖譜,找到與輸入相關的上下文信息,然后將這些信息與原始輸入一起送入生成模型,從而產生更加準確和豐富的內容。
工作原理
1.檢索(Retrieval)
?當模型接收到一個輸入或查詢時,RAG 首先從外部知識庫或數據源中檢索相關信息。這通常涉及到使用向量數據庫和近似最近鄰搜索算法來找到與輸入最相關的文檔片段或知識條目。
2.生成(Generation)
?一旦檢索到相關的信息,這些信息會被整合到生成模型的輸入中,作為上下文或提示(prompt)。這樣,當模型生成輸出時,它就能利用這些額外的信息來提供更準確、更詳細和更相關的響應。
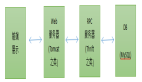
基本流程:
 圖片
圖片
RAG的優勢:
1.減少知識局限性:LLMs 通常受限于其訓練數據,而 RAG 可以讓模型訪問實時或最新的信息,從而克服這一限制。
2.減少幻覺:幻覺是指模型生成不存在于其訓練數據中的不真實信息。RAG 通過提供事實依據,可以減少這種現象。
3.提高安全性:RAG可以通過控制檢索的范圍和類型,避免模型生成潛在的有害或敏感信息。
4.增強領域專業性:對于特定領域的查詢,RAG可以從專業的知識庫中檢索信息,從而使模型的回答更具專業性
RAG 可以應用于多種場景,包括但不限于:
?問答系統:RAG 能夠檢索到與問題最相關的答案片段,然后基于這些片段生成最終的回答。
?對話系統:在對話中,RAG 可以幫助模型引用歷史對話或外部知識來生成更自然、更有信息量的回復。
?文檔摘要:RAG 能夠從大量文檔中提取關鍵信息,生成總結或概述。
?文本補全:在文本補全任務中,RAG 可以參考相關文檔來提供更準確的建議。
RAG架構的一個重要組成部分是檢索組件,它通常使用向量相似度搜索技術,如倒排索引或基于神經網絡的嵌入空間搜索。這使得模型能夠在大規模文檔集合中快速找到最相關的部分。
AI 應用開發框架
(一)Langchain
官網:https://www.langchain.com/langchain
LangChain不是一個大數據模型,而是一款可以用于開發類似AutoGPT的AI應用的開發工具,LangChain簡化了LLM應用程序生命周期的各個階段,且提供了 開發協議、開發范式,并 擁有相應的平臺和生態;
LangChain 是一個由 Harrison Chase 創立的框架,專注于幫助開發者使用語言模型構建端到端的應用程序。它特別設計來簡化與大型語言模型(LLMs)的集成,使得創建由這些模型支持的應用程序變得更加容易。LangChain 提供了一系列工具、組件和接口,可以用于構建聊天機器人、生成式問答系統、摘要工具以及其他基于語言的AI應用。
LangChain 的核心特性包括:
1.鏈式思維(Chains):LangChain 引入了“鏈”(Chain)的概念,這是一系列可組合的操作,可以按順序執行,比如從獲取輸入、處理數據到生成輸出。鏈條可以嵌套和組合,形成復雜的邏輯流。
2.代理(Agents):代理是更高級別的抽象,它們可以自主地決定如何使用不同的鏈條來完成任務。代理可以根據輸入動態選擇最佳行動方案。
3.記憶(Memory):LangChain 支持不同類型的內存,允許模型保留歷史對話或操作的上下文,這對于構建有狀態的對話系統至關重要。
4.加載器和拆分器(Loaders and Splitters):這些工具幫助讀取和處理各種格式的文檔,如PDF、網頁、文本文件等,為模型提供輸入數據。
5.提示工程(Prompt Engineering):LangChain 提供了創建和管理提示模板的工具,幫助引導模型生成特定類型的內容。
6.Hub:LangChain Hub 是一個社區驅動的資源庫,其中包含了許多預構建的鏈條、代理和提示,可以作為構建塊來加速開發過程。
7.與外部系統的集成:LangChain 支持與外部數據源和API的集成,如數據庫查詢、知識圖譜、搜索引擎等,以便模型能夠訪問更廣泛的信息。
8.監控和調試工具:為了更好地理解和優化應用程序,LangChain 提供了日志記錄和分析功能,幫助開發者追蹤模型的行為和性能。
(二)LangChain4J
上面說的 LangChain 是基于python 開發的,而 LangChain4J 是一個旨在為 Java 開發者提供構建語言模型應用的框架。受到 Python 社區中 LangChain 庫的啟發,LangChain4J 致力于提供相似的功能,但針對 Java 生態系統進行了優化。它允許開發者輕松地構建、部署和維護基于大型語言模型的應用程序,如聊天機器人、文本生成器和其他自然語言處理(NLP)任務。
主要特點:
1.模塊化設計:LangChain4J提供了一系列可組合的模塊,包括語言模型、記憶、工具和鏈,使得開發者可以構建復雜的語言處理流水線。
2.支持多種語言模型:LangChain4J支持與各種語言模型提供商集成,如 Hugging Face、OpenAI、Google PaLM 等,使得開發者可以根據項目需求選擇最合適的模型。
3.記憶機制:它提供了記憶組件,允許模型記住先前的對話歷史,從而支持上下文感知的對話。
4.工具集成:LangChain4J 支持集成外部工具,如搜索API、數據庫查詢等,使得模型能夠訪問實時數據或執行特定任務。
5.鏈式執行:通過鏈式執行,可以將多個語言處理步驟鏈接在一起,形成復雜的處理流程,例如先分析用戶意圖,再查詢數據庫,最后生成回復。
主要功能:
1.LLM 適配器:允許你連接到各種語言模型,如 OpenAI 的 GPT-3 和 GPT-4,Anthropic 的 Claude 等。
2.Chains 構建:提供一種機制來定義和執行一系列操作,這些操作可以包括調用模型、數據檢索、轉換等,以完成特定的任務。
3.Agent 實現:支持創建代理(agents),它們可以自主地執行任務,如回答問題、完成指令等。
4.Prompt 模板:提供模板化的提示,幫助指導模型生成更具體和有用的回答。
5.工具和記憶:允許模型訪問外部數據源或存儲之前的交互記錄,以便在會話中保持上下文。
6.模塊化和可擴展性:使開發者能夠擴展框架,添加自己的組件和功能。
本地問答系統搭建環境準備
(一)用 Ollama 啟動一個本地大模型
1.下載安裝 Ollma
2.ollama 是一個命令行工具,用于方便地在本地運行 LLaMA 系列模型和其他類似的 transformer 基礎的大型語言模型。該工具簡化了模型的下載、配置和推理過程,使得個人用戶能夠在自己的機器上直接與這些模型交互,而不需要直接接觸復雜的模型加載和推理代碼;
3.下載地址:https://ollama.com/,下載完成后,打開Ollma,其默認端口為11334,瀏覽器訪問:http://localhost:11434 ,會返回:Ollama is running,電腦右上角展示圖標;
 圖片
圖片
1.下載大模型
2.安裝完成后,通過命令行下載大模型,命令行格式:ollmapull modelName,如:ollma pull llama3;
3.大模型一般要幾個G,需要等一會;個人建議至少下載兩個, llama3、 qwen(通義千問),這兩個都是開源免費的,英文場景 用 llama3,中文場景用 qwen;
下載完成后,通過 ollma list 可以查看 已下載的大模型;
 圖片
圖片
1.啟動大模型
確認下載完成后,用命令行 :ollma run 模型名稱,來啟動大模型;啟動后,可以立即輸入內容與大模型進行對話,如下:
 圖片
圖片
(二)啟動本地向量數據庫 chromadb
Chroma 是一款 AI 原生開源矢量數據庫,它內置了入門所需的一切,可在本地運行,是一款很好的入門級向量數據庫。
1.安裝:pip install chromadb ;
2.啟動:chroma run :
 圖片
圖片
用Java實現本地AI問答功能
(一)核心maven依賴
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain4j.version>0.31.0</langchain4j.version>
</properties>
<dependencies>
<!-- langchain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- chroma 向量數據庫 -->
<dependency>
<groupId>io.github.amikos-tech</groupId>
<artifactId>chromadb-java-client</artifactId>
<version>0.1.5</version>
</dependency>
</dependencies>(二)代碼編寫
1. 加載本地文件作為本地知識庫:
public static void main(String[] args) throws ApiException {
//======================= 加載文件=======================
Document document = getDocument("笑話.txt");
}
private static Document getDocument(String fileName) {
URL docUrl = LangChainMainTest.class.getClassLoader().getResource(fileName);
if (docUrl == null) {
log.error("未獲取到文件");
}
Document document = null;
try {
Path path = Paths.get(docUrl.toURI());
document = FileSystemDocumentLoader.loadDocument(path);
} catch (URISyntaxException e) {
log.error("加載文件發生異常", e);
}
return document;
}- 拆分文件內容:
//======================= 拆分文件內容=======================
//參數:分段大小(一個分段中最大包含多少個token)、重疊度(段與段之前重疊的token數)、分詞器(將一段文本進行分詞,得到token)
DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(200, 0, new OpenAiTokenizer());
List<TextSegment> segments = lineSplitter.split(document);
log.info("segment的數量是: {}", segments.size());
//查看分段后的信息
segments.forEach(segment -> log.info("========================segment: {}", segment.text()));- 文本向量化 并存儲到向量數據庫:
//提前定義兩個靜態變量
private static final String CHROMA_DB_DEFAULT_COLLECTION_NAME = "java-langChain-database-demo";
private static final String CHROMA_URL = "http://localhost:8000";
//======================= 文本向量化=======================
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
//======================= 向量庫存儲=======================
Client client = new Client(CHROMA_URL);
//創建向量數據庫
EmbeddingStore<TextSegment> embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl(CHROMA_URL)
.collectionName(CHROMA_DB_DEFAULT_COLLECTION_NAME)
.build();
segments.forEach(segment -> {
Embedding e = embeddingModel.embed(segment).content();
embeddingStore.add(e, segment);
});- 向量庫檢索
//======================= 向量庫檢索=======================
String qryText = "北極熊";
Embedding queryEmbedding = embeddingModel.embed(qryText).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding(queryEmbedding).maxResults(1).build();
EmbeddingSearchResult<TextSegment> embeddedEmbeddingSearchResult = embeddingStore.search(embeddingSearchRequest);
List<EmbeddingMatch<TextSegment>> embeddingMatcheList = embeddedEmbeddingSearchResult.matches();
EmbeddingMatch<TextSegment> embeddingMatch = embeddingMatcheList.get(0);
TextSegment textSegment = embeddingMatch.embedded();
log.info("查詢結果: {}", textSegment.text());- 與LLM交互
//======================= 與LLM交互=======================
PromptTemplate promptTemplate = PromptTemplate.from("基于如下信息用中文回答:\n" +
"{{context}}\n" +
"提問:\n" +
"{{question}}");
Map<String, Object> variables = new HashMap<>();
//以向量庫檢索到的結果作為LLM的信息輸入
variables.put("context", textSegment.text());
variables.put("question", "北極熊干了什么");
Prompt prompt = promptTemplate.apply(variables);
//連接大模型
OllamaChatModel ollamaChatModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
UserMessage userMessage = prompt.toUserMessage();
Response<AiMessage> aiMessageResponse = ollamaChatModel.generate(userMessage);
AiMessage response = aiMessageResponse.content();
log.info("大模型回答: {}", response.text());(三)功能測試
- 代碼中用到 "笑話.txt" 是我隨便從網上找的一段內容,大家可以隨便輸入點內容,為了給大家展示測試結果,我貼一下我 文本內容:
有一只北極熊和一只企鵝在一起耍,
企鵝把身上的毛一根一根地拔了下來,拔完之后,對北極熊說:“好冷哦!”
北極熊聽了,也把自己身上的毛一根一根地拔了下來,
轉頭對企鵝說:
”果然很冷!”- 當我輸入問題:“北極熊干了什么”,程序打印如下結果:
根據故事,北極熊把自己的身上的毛一根一根地拔了下來
結語
1.以上便是完成了一個超簡易的AI問答功能,如果想搭一個問答系統,可以用Springboot搞一個Web應用,把上面的代碼放到 業務邏輯中即可;
2.langchain 還有其他很多很強大的能力,prompt Fomat、output Fomat、工具調用、memory存儲等;
3.早點認識和學習ai,不至于被它取代的時候,連對手是誰都不知道。