實戰SQL:地鐵換乘線路圖查詢
對于很多 IT 從業人員來說,SQL 僅僅意味著簡單的增刪改查(SELECT、INSERT、UPDATE 和 DELETE),但實際上 SQL 能夠實現的功能遠遠不止簡單的增刪改查。

今天我們就來介紹一個高級 SQL 功能:通用表表達式(Common Table Expression)。CTE 可以提高復雜查詢的性能和可讀性,實現樹狀結構或者圖數據的遍歷,實現以下功能:
- 生成數字序列;
- 獲取員工上下級的組織關系;
- 查詢地鐵、航班換乘線路;
- 社交網絡圖譜分析。
一般來說,我們只能通過應用程序或者存儲過程實現這些復雜的功能。但是有了 CTE,我們可以直接利用一個 SQL 語句完成以上功能。CTE 不僅強大而且通用,各種主流數據庫都提供了支持。

我們通過幾個實用案例,了解一下 CTE 的語法,同時介紹各種數據庫中的實現差異。
簡單 CTE
通用表表達式使用 WITH 關鍵字表示,例如:
WITH t(n) AS (
SELECT 4
)
SELECT * FROM t;
n|
-|
4|以上 WITH 子句相當于定義了一個語句級別的臨時表 t(n),在隨后的 SELECT、INSERT、UPDATE 以及 DELETE 語句中都可以使用。
WITH 子句定義了一個表達式,表達式的值是一個表,所以稱為通用表表達式。CTE 和子查詢類似,可以用于 SELECT、INSERT、UPDATE 以及 DELETE 語句。Oracle 中稱之為子查詢因子(subquery factoring)
CTE 與子查詢類似,只在當前語句中有效;不過一個語句中可以定義多個 CTE,而且 CTE 被定義之后可以多次引用:
WITH t1(n) AS (
SELECT 4 -- FROM dual
),
t2(n) AS (
SELECT n+1 FROM t1
)
SELECT t1.n, t2.n
FROM t1
CROSS JOIN t2;
n|n|
-|-|
4|5|第一個 CTE 名為 t1;第二個 CTE 名為 t2,引用了前面定義的 t1 ;每個 CTE 之間使用逗號進行分隔;最后的 SELECT 語句使用前面定義的 2 個 CTE 進行連接查詢。這種使用 CTE 的方法和編程語言中的變量非常類似。
CTE 和視圖、臨時表或者子查詢都有點類似,但是比它們的結構更加清晰;數據庫對于 CTE 只需要執行一次,性能也會更好。不過,CTE 真正強大之處是允許在定義中調用自己,也就是遞歸調用。
生成數字序列

WITH 子句還有一種遞歸形式,以下語句可以生成一個 1 到 10 的數字序列:
WITH RECURSIVE t(n) AS
(
SELECT 1 -- 初始化
UNION ALL
SELECT n + 1 FROM t WHERE n < 10 -- 遞歸結束條件
)
SELECT n FROM t;
n |
--|
1|
2|
3|
4|
5|
6|
7|
8|
9|
10|其中,RECURSIVE 表示遞歸查詢,Oracle 和 SQL Server 中不需要該關鍵字。
遞歸 CTE 包含兩部分,UNION ALL 上面的查詢語句用于生成初始化數據;下面的查詢語句用于遞歸,引用了它自身( t )。
- 運行初始化語句,生成數字 1;
- 第 1 次運行遞歸部分,此時 n 等于 1,返回數字 2( n+1 );
- 第 2 次運行遞歸部分,此時 n 等于 2,返回數字 3( n+1 );
- 第 9 次運行遞歸部分,此時 n 等于 9,返回數字 10( n+1 );
- 第 10 次運行遞歸部分,此時 n 等于 10;由于查詢不滿足條件( WHERE n < 10 ),不返回任何結果,并且遞歸結束;最后的查詢語句返回 t 中的全部數據,也就是一個 1 到 10 的數字序列。
只要是具有一定規律的數字序列都可以通過遞歸 CTE 生成,例如斐波那契數列。
遍歷組織結構圖
在公司的組織結構中,存在上下級的管理關系,如下圖所示。

示例表和數據:https://github.com/dongxuyang1985/thinking_in_sql
如果我們想要知道某個員工從上至下的各級領導,可以使用遞歸 CTE:
WITH RECURSIVE employee_path (emp_id, emp_name, path) AS
(
SELECT emp_id, emp_name, CAST(emp_name AS CHAR(100)) AS path
FROM employee
WHERE manager IS NULL
UNION ALL
SELECT e.emp_id, e.emp_name, CAST(CONCAT(ep.path, '->', e.emp_name) AS CHAR(1000))
FROM employee_path ep
JOIN employee e ON ep.emp_id = e.manager
)
SELECT * FROM employee_path WHERE emp_name = '黃忠';
emp_id|emp_name|path |
------|--------|-----------------|
5|黃忠 |劉備->諸葛亮->黃忠|上面是 MySQL 中的語法。
Oracle 以及 SQL Server 中需要將 CHAR(100) 改為 VARCHAR(100),同時省略 RECURSIVE 關鍵字;PostgreSQL 中需要將 CAST 函數里的 CHAR(100) 改為 VARCHAR(100);SQLite 沒有提供 CONCAT 函數,使用連接操作符(||)即可。
其中,初始化查詢用于查找沒有 manager 的員工,也就是最上級的領導;遞歸查詢通過將員工的 manager 和上級員工的 emp_id 進行關聯,獲取上下級管理關系;遞歸結束的條件就是沒有找到任何數據。當然,我們也可以從下級往上級進行遍歷。
其他具有這種層級關系的數據包括多層菜單、博客文章中的評論等。
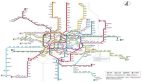
查找地鐵換乘線路

地鐵、公交、航班等,包括社交網站上的關注,都是一種有向圖數據結構。我們通常需要查找某一站點到另一站點的最短路徑,利用遞歸 CTE 可以實現這類需求。
示例表和數據:https://github.com/dongxuyang1985/sql_in_action
以下語句用于查找“王府井”到“積水潭”的換乘路線,使用 PostgreSQL 數據庫實現:
WITH RECURSIVE paths (start_station, stop_station, stops, path) AS (
SELECT station_name, next_station, 1, ARRAY[station_name::text, next_station::text]
FROM bj_subway WHERE station_name = '王府井'
UNION ALL
SELECT p.start_station, e.next_station, stops + 1, p.path || ARRAY[e.next_station::text]
FROM paths p
JOIN bj_subway e
ON p.stop_station = e.station_name AND NOT e.next_station = ANY(p.path)
)
SELECT * FROM paths WHERE stop_station = '積水潭';
start_station|stop_station|stops|path |
-------------|------------|-----|-------------------------------------------------------------------------------|
王府井 |積水潭 | 8|{王府井,天安門東,天安門西,西單,復興門,阜成門,車公莊,西直門,積水潭} |
王府井 |積水潭 | 9|{王府井,東單,建國門,朝陽門,東四十條,東直門,雍和宮,安定門,鼓樓大街,積水潭} |
王府井 |積水潭 | 13|{王府井,東單,建國門,北京站,崇文門,前門,和平門,宣武門,長椿街,復興門,阜成門,車公莊,西直門,積水潭} |
王府井 |積水潭 | 18|{王府井,天安門東,天安門西,西單,復興門,長椿街,宣武門,和平門,前門,崇文門,北京站,建國門,朝陽門,東四十條,東直門,雍和宮,安定門,鼓樓大街,積水潭}|查詢結果顯示有 4 條路線,如果選擇最短路線就是第一條。其中的 path 字段是個數組,用于存儲走過的站點;最后的 NOT e.next_station = ANY(p.path) 條件用于避免反復經過同一個站點,因為地鐵線路是一個雙向圖。
我們還可以進一步計算換乘次數,實現最少換乘路線;如果在表中增加一些字段,記錄每兩個站點之間的時間和換乘時間,還可以計算最快路線。
其他數據庫沒有提供數組類型,但是可以使用其他方法實現,以下是 MySQL 中的實現:
WITH RECURSIVE paths (start_station, stop_station, stops, path) AS (
SELECT station_name, next_station, 1, CAST(CONCAT(station_name , ',', next_station) AS CHAR(1000))
FROM bj_subway WHERE station_name = '王府井'
UNION ALL
SELECT p.start_station, e.next_station, stops + 1, CONCAT_WS(',', p.path, e.next_station)
FROM paths p
JOIN bj_subway e
ON p.stop_station = e.station_name AND (INSTR(p.path, e.next_station) = 0)
)
SELECT * FROM paths WHERE stop_station ='積水潭';我們使用了逗號分隔符的字符串模擬數組的效果,這種方法也適用于其他數據庫。