解決 Elasticsearch cluster_block_exception 錯誤的終極指南
Elasticsearch 是一個功能強大的分布式搜索引擎,廣泛應用于全文檢索、實時分析等場景。
盡管如此,像任何復雜系統一樣,它也會遇到一些運行問題,其中較為常見且影響較大的就是 cluster_block_exception 錯誤。
本文將深入解析這種錯誤的常見原因、如何排查問題以及如何有效解決。
我們將為你提供一套簡明的解決方案,幫助你輕松應對這個問題。
一、什么是 cluster_block_exception 錯誤?
cluster_block_exception 是 Elasticsearch 中的一種錯誤,通常表示集群由于某種狀態阻止了某些操作的執行。
這是 Elasticsearch 的一種保護機制,避免數據丟失或系統崩潰。
常見的觸發原因包括磁盤空間不足、集群健康狀態不佳、節點故障或不正確的索引設置。
1. 磁盤空間不足
- 問題描述:
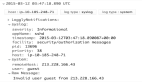
Elasticsearch 內置了磁盤空間警戒水位線機制,當磁盤空間不足時,系統會阻止數據寫入,以保護集群的完整性。這是最常見的 cluster_block_exception 觸發原因。
 圖片
圖片
- 如何檢查磁盤空間:
使用以下命令檢查集群各節點的磁盤使用情況:
GET _cat/allocation?v如果某個節點的磁盤使用率超過高水位線,Elasticsearch 會阻止進一步寫入數據。
 圖片
圖片
 圖片
圖片
- 解決方法:
增加磁盤空間。刪除不必要的舊索引:
DELETE /index_name2. 集群健康問題
- 問題描述:
當集群的健康狀態變為 yellow 或 red 時,某些操作可能會被阻止。
yellow 表示副本分片未完全分配,而 red 則表明主分片不可用或丟失。
 圖片
圖片
- 如何檢查集群健康狀態:
GET _cluster/health如果集群狀態為 yellow 或 red,這表明有潛在的集群健康問題需要解決。
- 解決方法:
確保所有節點正常運行,使用以下命令檢查節點狀態:
GET _cat/nodes?v 圖片
圖片
如果節點存在問題,檢查硬件或網絡問題,并重新啟動故障節點。
重新分配分片以恢復集群健康:
POST /_cluster/reroute優化集群配置,如增加副本分片數。
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html
3. 節點故障
- 問題描述:
節點故障通常是由于硬件、網絡或資源不足引起的。
當一個或多個節點出現故障時,可能會導致 cluster_block_exception,因為部分分片變得不可用。
- 如何識別節點故障:
GET _cat/nodes?v 圖片
圖片
通過檢查節點的狀態和資源使用情況,尤其是 CPU 和內存,確定哪些節點可能出現問題。
- 解決方法:
重新啟動出現故障的節點。
檢查并解決硬件或網絡問題,確保節點可以正常通信。
確保 Elasticsearch 進程有足夠的系統資源(CPU、內存等)。
4. 集群或索引被設置為只讀
- 問題描述:
有時,Elasticsearch 集群或索引可能被錯誤地設置為只讀模式,尤其是在磁盤空間不足時。
message [ElasticsearchException[Elasticsearch exception [type=cluster_block_exception, reasnotallow=blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];]]]此時,所有寫操作都會被阻止,導致 cluster_block_exception。
- 如何檢查集群是否為只讀:
GET /_cluster/settings 圖片
圖片
檢查 cluster.blocks.read_only 或 cluster.blocks.read_only_allow_delete 是否為 true。
- 解決方法:
將集群或索引設置為可寫:
PUT /_cluster/settings
{
"persistent": {
"cluster.blocks.read_only": false
}
}或者,移除索引的只讀設置(常見移除基本都是設置 null,其他類似命令可以參見如下):
PUT /index_name/_settings
{
"index.blocks.read_only_allow_delete": null
}5. 索引設置問題
- 問題描述:
有時,錯誤的索引設置(例如分片分配問題或副本數過少)可能導致操作失敗,引發 cluster_block_exception。
- 如何檢查索引設置:
GET /index_name/_settings 圖片
圖片
- 解決方法:
確保分片合理分配,避免過度分配。推薦閱讀:
Elasticsearch 使用誤區之三——分片設置不合理
檢查和調整副本分片數量,確保有足夠的副本來保障數據冗余和查詢性能。
二、預防措施
要預防 cluster_block_exception,我們可以采取以下措施:
- 措施1:定期監控磁盤空間
使用 Kibana 或其他監控工具設置磁盤空間的監控閾值,避免磁盤空間不足。
- 措施2:自動化分片管理:
使用索引生命周期管理(ILM)策略,自動化控制索引的遷移、刪除或凍結操作,以避免無限制的索引增長。
ILM 實戰視頻:https://www.bilibili.com/video/BV1MU4y1u7D4/
- 措施3:定期健康檢查。
定期檢查集群的健康狀態,并在集群狀態變為 yellow 或 red 時立即采取措施。
- 措施4:備份和更新
定期備份 Elasticsearch 數據,確保出現問題時數據可以快速恢復。
此外,確保 Elasticsearch 版本是最新的,以利用性能改進和錯誤修復。
三、總結
cluster_block_exception 錯誤雖然聽起來棘手,但只要你了解了它的觸發原因和解決方法,就能輕松應對。
通過本文的指南,結合日常的監控和優化策略,你可以確保 Elasticsearch 集群在高效且穩定的狀態下運行,避免潛在的停機和數據損失。
參考
【1】https://kasata.medium.com
【2】https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html