你了解布隆過濾器的“大家族”嗎?
你好,我是看山。
布隆過濾器的基本思想
布隆過濾器(Bloom Filter)是1970年由伯頓·霍華德·布隆(Burton Howard Bloom)提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。
布隆過濾器可以用于檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的算法,缺點是有一定的誤識別率和刪除困難。
如果想判斷一個元素是不是在一個集合里,一般想到的是將集合中所有元素保存起來,然后通過比較確定。鏈表、樹、散列表(又叫哈希表,Hash Table)等等數據結構都是這種思路。但是隨著集合中元素的增加,我們需要的存儲空間越來越大。同時檢索速度也越來越慢,上述三種結構的檢索時間復雜度分別為O(n)、O(logn)、O(1)。
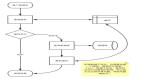
布隆過濾器的原理是,當一個元素被加入集合時,通過K個散列函數將這個元素映射成一個位數組中的K個點,把它們置為1。
 圖片
圖片
檢索時,我們只要看看這些點是不是都是1就(大約)知道集合中有沒有它了:如果這些點有任何一個0,則被檢元素一定不在;如果都是1,則被檢元素很可能在。
 圖片
圖片
布隆過濾器家族
基于上面的基本思想,結合布隆過濾器算法的優缺點,又衍生出了很多有特殊能力的布隆過濾器,也就是布隆過濾器家族(Bloom Filter Family)。
布隆過濾器(Bloom Filter)
實現邏輯
一種空間效率很高的數據結構,用于判斷一個元素是否在一個集合中。實現原理如前文所述。
運行過程
- 插入元素:元素經過多個哈希函數(這里假設為3個,即Hash1、Hash2、Hash3)映射到位數組中的不同位置。例如,元素X經過Hash1映射到位置3,經過Hash2映射到位置7,經過Hash3映射到位置12,然后將這些位置的值設為1。
- 查詢元素:當查詢元素X時,檢查位置3、7、12是否都為1。如果都為1,則認為元素X可能在集合中(存在誤報可能);如果有任何一個位置為0,則確定元素X不在集合中。
解決的問題
高效判斷元素是否在集合中,在犧牲一定準確性(存在誤報)的情況下,大大節省內存空間,提高查詢效率,適用于對內存要求苛刻且對少量誤報可容忍的場景。
應用場景
在網絡、數據庫等領域有廣泛應用,比如:
- 判斷一個數據項是否已經在緩存中,避免不必要的數據庫查詢,提高系統的響應速度。
- 作為數據庫索引的輔助結構,快速確定某個鍵值是否可能存在于數據庫中,輔助索引的精確查找過程;
- 在網絡路由中,判斷一個IP地址是否屬于某個特定的路由區域,快速篩選出可能匹配的路由條目,減少精確查找的范圍;
- 用于識別網絡流量中的某些特征模式,例如判斷一個數據包是否屬于某類特定的應用流量(如視頻流、音頻流等),以便進行針對性的處理(如流量整形、優先級設置等)。
在網絡、數據庫等領域有廣泛應用,例如在緩存系統中判斷一個數據項是否已經在緩存中,在網絡路由中判斷一個IP地址是否屬于某個特定的路由區域等。
設計權衡
涉及內存、計算和誤報性能之間的權衡。通過調整哈希函數的數量和位數組的大小,可以在不同程度上平衡這些因素。
計數布隆過濾器(Counting Bloom Filter,CBF)
改進點
將布隆過濾器中的1位單元擴展為c位計數器。
運行過程
- 插入元素:元素經過哈希函數映射到位數組中的位置,對應位置的計數器增加。例如,元素X第一次插入時,對應位置的計數器從0變為1。如果再次插入相同元素,計數器繼續增加。
- 刪除元素:當刪除元素X時,對應位置的計數器減1。當計數器為0時,表示該元素已被刪除。例如,計數器為2時,刪除一次變為1,再刪除一次變為0,表示元素已從“可能存在集合中”變為“確定不在集合中”。
解決的問題
解決布隆過濾器無法直接支持元素刪除的問題,但引入了較高的內存消耗問題,需要在內存使用和刪除功能之間進行權衡。
缺點
c倍地減少了實際可用的位空間(通常為3或4位以避免計數器溢出),導致內存消耗過高,例如在片上內存等資源受限的環境中不太適用。
應用場景
- 在數據庫事務中,用于記錄某個數據項被操作(如插入、更新、刪除)的次數。例如,在一個支持多版本并發控制(MVCC)的數據庫系統中,CBF可以用來跟蹤每個數據項的不同版本的使用情況,以便在事務提交或回滾時進行正確的處理。
- 用于統計網絡中某個源IP地址或某個應用協議的流量出現的次數,幫助網絡管理員了解網絡流量的分布和使用情況,以便進行網絡資源的合理配置和優化。
d-left計數布隆過濾器(d-left CBF,dlCBF)
改進點
基于d-left哈希和元素指紋,通過特定的哈希算法將元素映射到相應位置,利用元素指紋信息進行優化,減少位空間需求。對于給定的目標誤報率(fpr),它所需的位空間約為4位CBF的一半。
運行過程
- 插入元素:元素經過d - left哈希和基于元素指紋的處理后,映射到相應位置,計數器增加(原理同CBF,但映射方式更優化)。
- 查詢元素:根據優化后的映射關系查詢元素對應的計數器值,判斷元素是否可能在集合中以及相關操作(如刪除時的計數器減1判斷)。
解決的問題
在一定程度上解決了CBF內存消耗大的問題,提高了空間效率,同時保持對元素刪除的支持,使其更適用于對空間有一定要求的應用場景。
局限性
當目標誤報率要與標準布隆過濾器(SBF)相當時,構造所需的空間仍然較大,可能無法滿足某些應用的需求。
應用場景
- 分布式系統中的成員資格判斷:在分布式系統中,如分布式文件系統或分布式數據庫系統,用于判斷一個節點是否屬于某個特定的集群或組。由于其相對節省空間的特點,在大規模分布式系統中可以有效地減少內存占用,同時保持一定的準確性。
- 內容分發網絡(CDN):在CDN中,用于判斷一個內容是否已經在某個邊緣服務器上緩存。當用戶請求一個內容時,首先通過dlCBF快速判斷該內容是否可能在本地邊緣服務器上,如果可能存在,則進一步精確查找,提高內容分發的效率。
帶有變長簽名的布隆過濾器(Bloom filter with variable - length signatures,VLF)
改進點
通過只重置k位中的一部分來處理元素刪除操作,在插入和查詢操作的基礎上增加了對部分位重置的邏輯。
運行過程
- 插入元素:元素經過哈希函數映射到位數組中的位置,同時記錄相關變長簽名信息(圖中未詳細體現)。
- 刪除元素:根據變長簽名信息,只重置部分相關位(假設為k位中的一部分)。例如,對于元素X,只重置位置3和7中的部分信息(不是完全重置整個k位),然后更新相關狀態以反映元素的刪除情況。
解決的問題
嘗試解決布隆過濾器的刪除問題,但帶來了假陰性的風險,需要在刪除功能和準確性之間進行平衡。
缺點
存在假陰性問題,即可能錯誤地判斷元素不在集合中,不符合一些應用對準確性的要求。
應用場景
- 數據挖掘中的關聯規則挖掘:在數據挖掘中,當挖掘關聯規則時,用于快速篩選出可能存在關聯關系的數據集。由于其能夠處理部分位的重置,在一些需要動態調整關聯規則的場景中具有一定優勢,例如在市場分析中,根據消費者行為的變化動態調整商品關聯規則。
- 文本處理中的關鍵詞過濾:在文本處理中,用于快速過濾出可能包含某些關鍵詞的文檔。例如,在搜索引擎中,對大量文檔進行預處理時,使用VLF快速篩選出可能與用戶搜索關鍵詞相關的文檔,然后再進行更精確的文本匹配和排名。
可刪除布隆過濾器(Deletable Bloom Filter,DlBF)
改進點
繼承了布隆過濾器的簡潔性,通過記錄插入元素時位碰撞的位置,對可刪除位的區域進行緊湊編碼(使用部分過濾器內存)。只有一個元素設置的位可以安全刪除,若一個元素至少有一個位被重置,則該元素可被有效刪除。
運行過程
- 插入元素:元素經過哈希函數映射到位數組中的位置,同時記錄位碰撞區域信息。如果發生碰撞,標記相應區域不可刪除。例如,元素X插入時,在位置3和7發生碰撞,標記這兩個位置所在區域不可刪除,其他未碰撞位置所在區域可刪除。
- 查詢元素:檢查元素對應的位置是否都為1來判斷是否可能在集合中。
- 刪除元素:只清除位于可刪除區域的位。例如,對于元素X,如果位置12未發生碰撞且在可刪除區域,刪除時只重置位置12的值,避免誤報的同時實現元素刪除。
解決的問題
實現無假陰性的元素刪除操作,同時通過合理的設計和參數調整,控制誤報率和內存消耗,使其適用于對刪除操作有需求且對誤報率和內存有一定要求的場景。
性能特點
元素可刪除概率與劃分的區域數量(r)和過濾器密度(m/n)等因素有關。隨著(r)增大,可刪除元素的比例增加;隨著插入元素增多,刪除能力降低。
誤報概率的增加是可控的,且與標準布隆過濾器相當。通過實驗評估,可刪除率與理論預測相符但值相對較低,誤報率在元素刪除前有可接受的增加,刪除元素位后可能會改善。
應用場景示例
在LIPSIN中可用于刪除已處理的單向鏈路標識符,避免環路和刪除特殊鏈路標識;在數據中心環境中可緊湊表示數據包需要經過的一系列中間盒服務,根據匹配情況透明轉發數據包并刪除服務標識。
- 網絡路由中的鏈路狀態維護:在網絡路由協議中,如在LIPSIN中,用于刪除已處理的單向鏈路標識符,避免環路的形成,同時可以刪除特殊的鏈路標識(如多跳虛擬鏈路或控制消息),保持路由信息的準確性和有效性。
- 數據中心的服務鏈處理:在數據中心環境中,用于緊湊表示數據包需要經過的一系列中間盒服務(如防火墻、負載 balancer、DPI)。當數據包經過中間盒時,根據DlBF的匹配情況透明轉發數據包,并在離開中間盒時刪除服務標識,提高數據中心網絡的處理效率。
壓縮布隆過濾器(Compressed Bloom Filter)
改進點
通過使用壓縮算法對布隆過濾器的位陣列進行壓縮存儲,以減少內存占用。
在查詢時,需要先解壓縮位陣列再進行判斷操作。
運行過程
- 插入元素:元素經過哈希函數映射到位數組中的位置,然后對整個位陣列進行壓縮存儲。
- 查詢元素:先解壓縮位陣列,再按照布隆過濾器的常規查詢方式檢查元素是否可能在集合中。
解決的問題
解決布隆過濾器在內存受限環境下的應用問題,通過壓縮減少內存占用,但增加了查詢時的計算開銷,需要在內存和計算效率之間進行權衡。
應用場景
適用于對內存空間要求極為苛刻的環境,例如在一些嵌入式設備或內存受限的傳感器網絡中,同時對誤報率有一定容忍度的場景。
- 嵌入式設備中的數據處理:在嵌入式設備(如智能家居設備、傳感器節點等)中,由于內存資源有限,使用壓縮布隆過濾器可以在有限的內存空間內實現對數據的快速判斷。例如,在智能家居系統中,判斷某個設備狀態是否已經被記錄,以便決定是否需要進一步處理。
- 傳感器網絡中的事件檢測:在傳感器網絡中,用于快速檢測某些特定事件的發生。例如,在環境監測傳感器網絡中,判斷是否出現了某種特定的環境變化(如溫度超過閾值、濕度異常等),通過壓縮布隆過濾器快速篩選出可能發生事件的傳感器節點,然后進行更精確的檢測。
分層布隆過濾器(Hierarchical Bloom Filter)
改進點
構建多層的布隆過濾器結構。
通常,上層的布隆過濾器具有較低的精度(較高的誤報率)但占用較少的內存,用于快速篩選出可能存在于集合中的元素;下層的布隆過濾器則具有較高的精度(較低的誤報率),用于對上層篩選出的元素進行進一步的精確判斷。
運行過程
- 插入元素:元素首先進入上層布隆過濾器,上層過濾器具有較低精度(較高誤報率),快速篩選出可能存在于集合中的元素。例如,元素X在上層過濾器中被判斷為可能存在。
- 查詢元素:如果上層判斷為可能存在,元素進入下層布隆過濾器進行更精確的判斷。下層過濾器具有較高精度(較低誤報率),最終確定元素是否在集合中。
解決的問題
提高在大規模數據集上的查找效率,通過分層的方式快速排除大量不可能的元素,減少精確查找的工作量,適用于對查找速度有較高要求的大規模數據應用場景。
應用場景
在大規模數據集的快速查找場景中較為適用。比如:
- 大規模數據庫查詢優化:在大型數據庫的索引結構中,先使用上層的分層布隆過濾器快速排除大量不可能存在的數據項,然后使用下層的過濾器進行更精確的查找,從而提高整體查詢效率,減少查詢時間。
- 網絡搜索中的網頁篩選:在網絡搜索中,用于篩選海量網頁中的相關網頁。上層的分層布隆過濾器根據用戶搜索關鍵詞快速篩選出可能相關的網頁類別,下層的過濾器對這些類別中的網頁進行更精確的篩選和排名,提高搜索結果的質量和相關性。
動態布隆過濾器(Dynamic Bloom Filter)
改進點
能夠根據數據集的動態變化(如元素的插入和刪除頻率)自動調整自身的參數,如哈希函數的數量、位陣列的大小等。通常會設置一些閾值和自適應算法來實現這種動態調整。
運行過程
- 插入元素:元素進入動態布隆過濾器,過濾器根據當前的插入和刪除頻率等動態信息調整自身參數(如哈希函數數量、位陣列大小等),然后按照調整后的規則將元素插入(例如通過新的哈希函數映射到新的位置)。
- 查詢元素:按照調整后的參數和規則查詢元素是否可能在集合中。
解決的問題
適應數據的動態變化,保持布隆過濾器在不同數據流量和操作頻率下的性能,解決固定參數布隆過濾器在動態環境下性能下降的問題。
應用場景
在數據流量不穩定的網絡環境中,比如:
- 云計算環境中的資源管理:在云計算環境中,用于動態判斷資源是否已被分配(元素是否在集合中)。例如,判斷某個虛擬機是否已經被分配了特定的存儲資源或網絡資源,根據數據流量和資源使用情況動態調整自身參數,提高資源利用效率。
- 移動互聯網中的用戶行為分析:在移動互聯網中,用于分析用戶行為模式。根據用戶的操作行為(如打開應用、點擊鏈接等)動態調整布隆過濾器的參數,快速判斷用戶是否執行過某些特定行為,以便為用戶提供更個性化的服務和推薦。
布谷鳥布隆過濾器(Cuckoo Bloom Filter)
原理
結合了布隆過濾器和布谷鳥哈希(Cuckoo Hashing)的思想。
它使用多個哈希函數將元素映射到多個桶中,并且在發生沖突時采用類似布谷鳥哈希的方式來處理,即嘗試將元素“踢出”已占用的桶并重新放置到其他桶中,同時通過一定的機制來記錄這些操作,以支持元素的刪除和準確判斷元素是否在集合中。
運行過程
- 插入元素:元素經過多個哈希函數映射到多個桶中(假設為兩個桶,桶1和桶2)。例如,元素X經過Hash1映射到桶1,經過Hash2映射到桶2。如果桶1已經被占用,按照布谷鳥哈希的方式,將桶1中的元素“踢出”,重新放置到其他桶(可能需要多次嘗試和記錄相關操作),直到元素X成功插入。
- 查詢元素:根據元素映射到的桶以及相關記錄的操作信息判斷元素是否在集合中。
- 刪除元素:根據記錄的操作信息,準確刪除元素X,例如,如果元素X是通過替換桶1中的元素Y插入的,當刪除X時,需要將Y還原到桶1中(或者根據具體的刪除邏輯進行正確處理)。
解決的問題
高效處理沖突并支持元素刪除,在保證準確性的同時提高數據插入、刪除和查詢的效率,適用于對操作效率有較高要求且需要處理沖突和支持刪除的場景。
應用場景
在需要高效處理沖突且支持元素刪除的場景中較為適用,例如:
- 實時數據處理系統中的數據管理:在實時數據處理系統中,用于高效處理數據的插入、刪除和查詢操作。例如,在一個工業自動化控制系統中,對實時采集的數據進行管理,判斷某個數據值是否已經存在于系統中,同時支持數據的插入和刪除操作,保證系統的高效運行。
- 內存數據庫中的數據存儲:在內存數據庫中,用于存儲和管理數據。由于其結合了布谷鳥哈希的沖突處理機制,在內存有限的情況下,可以高效地利用內存空間,同時保證數據的準確性和可操作性。
文末總結
布隆過濾器為什么這么重要,那是因為有下面四個特點:
- 空間效率:布隆過濾器可以使用相對較少的內存來表示大量元素。
- 快速成員測試:布隆過濾器可以快速確定某個元素是否可能存在于集合中,而無需訪問實際的集合數據。
- 可擴展性:布隆過濾器可以處理大量元素,并且無論集合大小如何,都能為成員資格測試提供恒定時間的性能。
- 誤報率控制:Bloom Filter 的空間效率的權衡就是誤報率的控制。通過調整哈希函數的數量和位數組的大小,可以降低或增加誤報率以滿足特定要求。
所以,雖然TA有這樣那么小毛病,但是我們總有辦法適應TA。