布隆過濾器,你用對了嗎?
布隆過濾器(Bloom Filter)是一種概率型數據結構,用于判斷一個元素是否屬于一個集合。它特別擅長處理大規模數據的快速查找,具有高效的空間利用率和查詢速度。下面是布隆過濾器的工作原理、優缺點和使用場景。

工作原理
(1) 初始化:布隆過濾器初始化時,創建一個長度為m的位數組(bit array),所有位初始化為0,并選擇k個獨立的哈希函數。
(2) 添加元素:將一個元素添加到布隆過濾器時,使用k個哈希函數對該元素進行哈希運算,得到k個哈希值(位置)。然后,將位數組中這k個位置的值設為1。
(3) 檢查元素:要檢查一個元素是否在布隆過濾器中,同樣使用k個哈希函數對該元素進行哈希運算,得到k個哈希值(位置)。檢查位數組中這k個位置的值:
- 如果所有位置的值都是1,則判斷該元素可能在集合中。
- 如果有一個位置的值是0,則判斷該元素肯定不在集合中。
示例展示
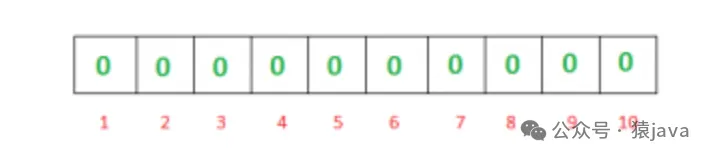
首先,一個空的布隆過濾器是一個 m 位的位數組,所有位都設置為零,如下所示:
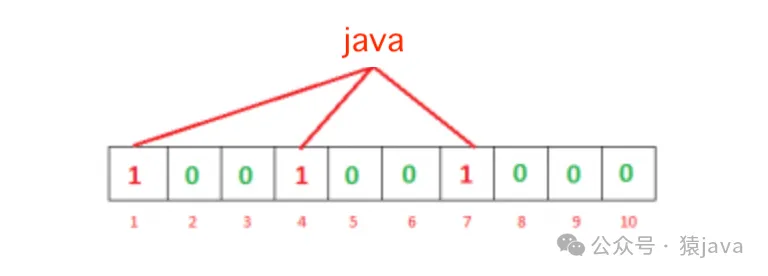
我們需要使用 k個哈希函數來計算給定輸入的哈希值。當我們想要將一個項目添加到過濾器中時,會設置索引h1(x)、h2(x)、… hk(x)處的位,其中索引是使用哈希函數計算的。例如,假設我們想要將“java”輸入過濾器,我們使用3個哈希函數和一個長度為10的位數組,初始時所有位都設置為0。首先我們將計算哈希值如下:
h1(“java”) % 10 = 1
h2(“java”) % 10 = 4
h3(“java”) % 10 = 7注意:這些輸出僅用于解釋。然后我們會將索引1、4和7處的位設置為1:
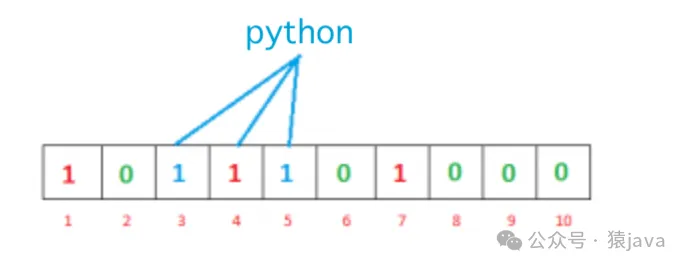
再次,我們想要輸入“python”,同樣地,我們將計算哈希值:
h1(“python”) % 10 = 3
h2(“python”) % 10 = 5
h3(“python”) % 10 = 4將索引3、5和4處的位設置為1,如下圖:
現在,如果我們想要檢查“java”是否存在于過濾器中。我們將執行相同的過程,但這次是反向的。我們使用h1、h2和h3計算相應的哈希值并檢查這些索引處的所有位是否都設置為1。如果所有位都設置為1,我們可以說“java”可能存在。如果這些索引處的任一位為0,則“java”肯定不存在。
為什么說:如果所有位都設置為1,我們可以說“java”可能存在?為什么有這種不確定性。讓我們通過一個例子來理解這一點。假設我們想要檢查“rust”是否存在,將使用h1、h2和h3計算哈希值:
h1(“rust”) % 10 = 1
h2(“rust”) % 10 = 3
h3(“rust”) % 10 = 7如果我們檢查位數組,這些索引處的位都設置為1,但我們知道“rust”從未被添加到過濾器中。索引1和7處的位是在我們添加“java”時設置的,索引3處的位是在我們添加“rust”時設置的。
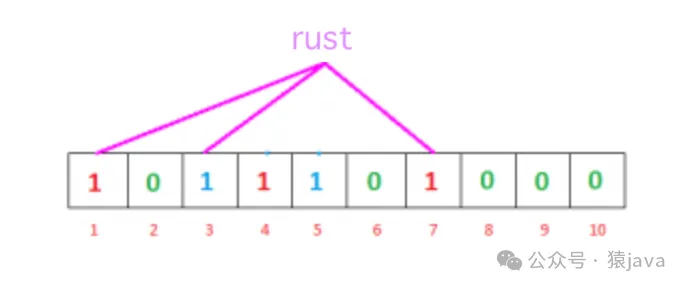
因此,由于計算出的索引處的位已經被其他項目設置,布隆過濾器錯誤地聲稱“rust”存在,并生成了一個假陽性結果。根據應用程序的不同,這可能是一個巨大的缺點或者是相對可以接受的。
優缺點
優點:
- 空間效率高:相比其他數據結構如哈希表,布隆過濾器的空間利用率非常高。
- 查詢速度快:查詢操作只需要進行k次哈希運算和k次數組訪問,速度非常快。
- 插入操作高效:插入操作同樣只需要進行k次哈希運算和k次數組訪問,效率高。
缺點:
- 誤判率:布隆過濾器可能會誤判,即可能會錯誤地認為某個元素在集合中(假陽性),但不會出現假陰性(即不存在的元素被誤判為存在)。
- 無法刪除元素:標準的布隆過濾器不支持刪除操作,因為刪除操作可能會影響其他元素的查詢結果。不過,可以使用計數布隆過濾器(Counting Bloom Filter)來支持刪除操作。
- 哈希函數選擇:需要選擇合適的哈希函數,以保證哈希值均勻分布,避免過多的沖突。
使用場景
- 網頁去重:在搜索引擎中,布隆過濾器可以用于判斷網頁是否已經被抓取過,從而避免重復抓取。
- 緩存系統:在分布式緩存系統中,布隆過濾器可以用于快速判斷某個數據是否在緩存中,從而減少對后端數據庫的查詢壓力。
- 垃圾郵件過濾:在郵件系統中,布隆過濾器可以用于快速判斷郵件是否為垃圾郵件,提高過濾效率。
- 數據庫查詢優化:在數據庫系統中,布隆過濾器可以用于快速判斷某個記錄是否存在,從而減少磁盤I/O操作,提高查詢效率。
總結
布隆過濾器是一種簡單但非常有效的數據結構,特別適用于大規模數據的快速查找和去重等場景。盡管它有一定的誤判率,但在很多應用中,這一點點誤判是可以接受的。