













拼多多二面:G1 垃圾回收器有幾次 STW ?
垃圾回收器是 JVM中很難懂但是又很重要的一個技術點,而 G1又是 JVM程碑的一款垃圾回收器,因此,這篇文章,我們來分析拼多多一道2面題目:G1 垃圾回收器會有幾個STW?

在分析這個問題之前,我們需要先對 G1回收器的原理進行一個整體的分析:
一、簡介
G1 是 Garbage First 的簡稱,最初起源于 Sun在2004年發布的一篇 G1學術論文 ,2012年9月,JDK 7 Update 4 發布,G1正式投入商業使用,耗時 8年之久。
G1收集器是一款面向服務器的垃圾收集器,采用標記整理算法,用于大內存的多處理器計算機,目標是實現低延時垃圾回收,從 2017年9月發布的 JDK9 開始,G1 就已經成為了默認的垃圾收集器。
Oracle官方給 G1的定位是用來替代 CMS收集器,這就是為什么很多文章會把 G1 和 CMS進行對比的根本原因。
二、堆內存結構
和以往的垃圾收集器不一樣,G1盡管依然保留了年輕代和老年代的概念, 但是它們已經變成了一個邏輯上的概念,G1的堆內存被切分成若干個大小(1M ~ 32M)相同且不連續的 Region,包括 4種類型:
- Eden Region,Eden區域
- Survivor Region,存活區域
- Old Generation Region,老年代區域
- Humongous Region,大對象區域
具體的堆內存結構如下圖:
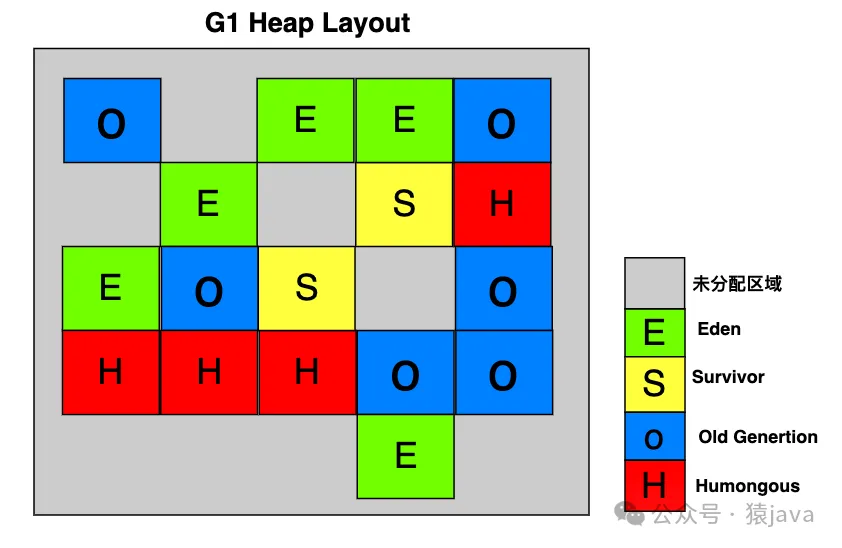
Eden 區和 Survivor區的組合就是通常說的年輕代。
Humongous是 G1 提出來的一個新區域,專門用于存儲大對象,這里的大對象是指內存占用大于等于單個 Region一半大小的對象。
比如,假設每個 Region是 2M,如果當前對象是 1M,那么它就是一個大對象,如果當前對象的大小是 3M,超過 1個 Region的范圍, 那么 G1會尋找連續的 2個 Humongous 區域來存放它,如果找不到連續的空間存放當前對象, G1可能會觸發一次垃圾回收來釋放空間,或者進行內存壓縮操作。
參數-XX:G1HeapRegionSize可以用來設置Region的大小,-XX:G1HeapReginotallow=4M,代表每個 Region的大小是 4M。
從 JVM運行時內存結構的角度看,G1 回收對象是整個堆內存,如下圖:
Region的特別說明:一個 Region可以是 Eden,Survivor,Old,Humongous 4種角色中的任意一種。在垃圾回收的過程中,存活對象可以從一個 Region 移動到另一個 Region, 比如,從 Eden區 移動到 Survivor區,從 Survivor區移動到老年代,所以,每個 Region具體屬于哪一種角色也是動態變化的。理解這一點,可以幫助我們更好地領會下文 G1的回收原理。
三、幾個重要技術點
在 CMS收集器這篇文章中,我們分析過三色標記法,記憶集,卡表,可達性分析等重要技術,作為 CMS的替換者和繼承人,G1也使用了類似的技術點。
在 CMS收集器中,存在跨代引用的問題,在 G1收集器中也存在同樣的問題:跨區域引用,可能因為 G1堆內存有很多的 Region,所以這個跨區域引用的問題似乎表現得更明顯。
1.什么是跨區域引用?
如下圖:Eden區的 A對象引用 Old區的 B對象,這是一種跨區域引用,Old區的 D對象指向 Eden區域的 E對象,這也是一種跨區域引用。
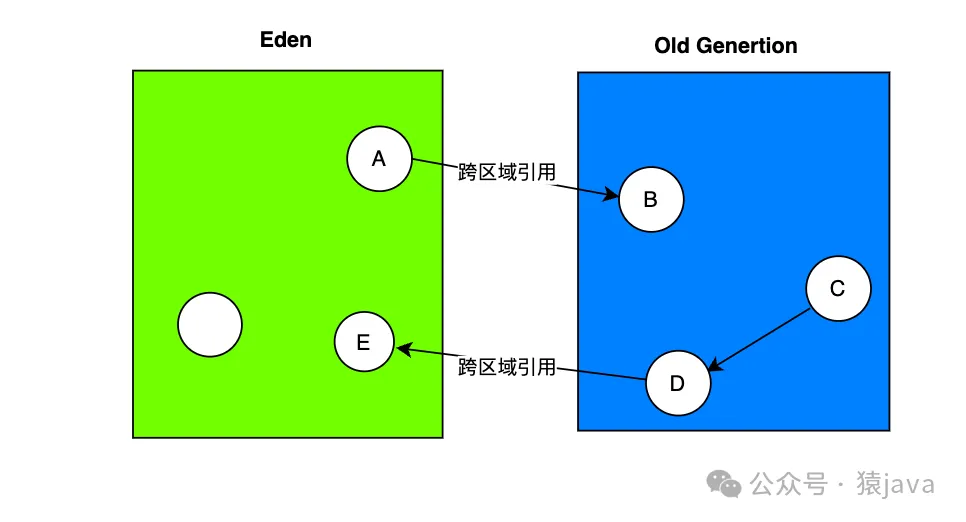
2.跨區域引用產生的問題
對于上圖中 Eden區域(年輕代)A對象指向老年代 B對象,即便 Young GC把 A對象回收了,程序還能正常運行,隨著 A->B引用鏈的斷開,B對象最終也可能因為無法被標記被回收,這種行為是可以接受的。但是,對于老年代 D對象指向 Eden區域(年輕代)E對象的場景,因為老年代 D對象是一個活躍對象,它是一個 GC Root, 所以,D對象直接關聯的 E對象也應該是存活對象,假如 E對象被 Young GC掉,就會出現存活的對象無故消失,該如何避免呢 ?
- 方法1:在 Young GC時掃描所有的老年代,找出指向 E對象的引用,因為 G1是用于大內存的垃圾回收器,如果全局掃描老年代區域,將會是一個很耗時的操作,顯然和 G1的設計初衷相違背。
- 方法2:把老年代指向年輕代(A -> B)的引用關系記錄起來,GC時只要掃描這些記錄數據,而 G1就是采用這種方式。在 G1中, 這種關系數據叫做記憶集(Remembered Set,RSet,RS),對于這里 A -> B里面的 B,G1也有專門的術語叫收集集(Collection Set)。
3.收集集(Collection Set)
在 G1中,收集集(Collection Set,CSet,CS)是指那些將要被清理以回收空間的源區域(Regions)的集合。根據垃圾回收的類型,收集集包含不同種類的區域:
- Young-Only階段:在這個階段,收集集只包含年輕代中的區域,以及那些可能被回收的大對象區域中的對象。
- 空間回收階段:在這個階段,收集集包括年輕代區域、可能被回收的大對象區域中的對象,以及從候選收集集區域集合中選出的一些老年代區域。
候選收集集區域(Collection Set Candidate Regions)是指那些在空間回收階段很可能被回收的區域。G1 會根據區域存活對象的數量以及和其他區域的連接性兩個指標進行選擇。存活對象少,連接性低的區域會優先成為候選收集集區域,這種選擇的目的是為了優化垃圾回收過程的效率,減少暫停時間,同時最大化回收空間。
4.記憶集(Remembered Set)
在 G1中,記憶集(Remembered Set,RSet,RS)本質上是一種哈希表,它用于跟蹤那些包含指向收集集中對象的引用的位置,這些引用是通過 Cards Table(卡表)來管理。
因為 Region的角色(Eden,Survivor,Old,Humongous)是動態變化的,所以 G1會給每個 Region設置一個 RSet,RSet本質上是一種哈希表,Key是 Region的起始地址,Key對應的 Value是一個集合,里面存儲的元素是卡表的索引號。
如下圖:Eden是一個收集集,包含一個記憶集(RSet),RSet 指向了兩個 Old區域。
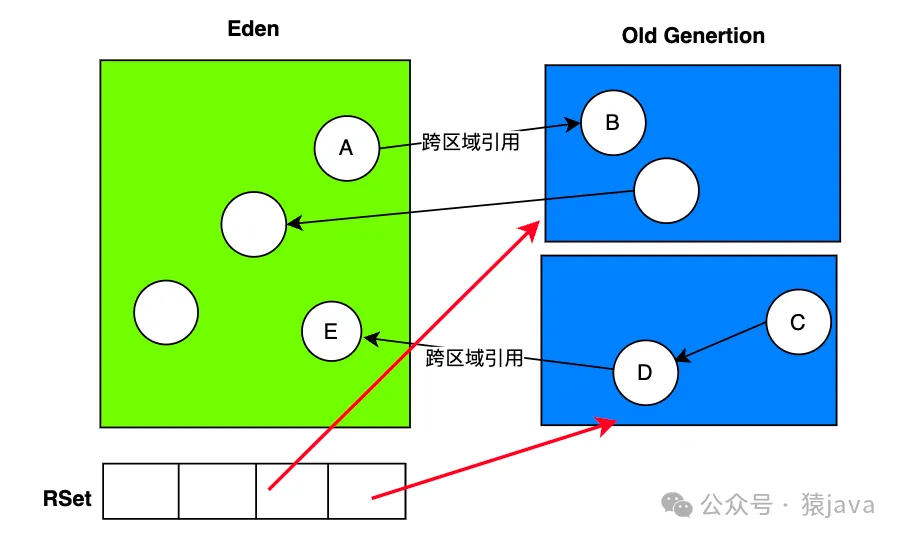
記憶集的作用,主要有 2點:
- 為了防止整個堆作為GC Roots的掃描范圍
- 確保在垃圾回收過程中,當收集集中的對象被移動,所有指向這些對象的引用都能夠更新,指向對象的新位置
5.卡表
卡表(Card Table)是記憶集的一種具體實現,每個 Region被分成了若干個大小為 512字節的連續內存區域,即卡表(Card Table),因為 Region的大小是 1~32M,所以每個 Region中卡表數量是 2~64個。
當一個老年代區域中的對象被修改,比如更新了一個引用字段指向一個年輕代對象時,JVM會使用寫屏障(Write Barrier)將相應的卡片標記為“臟”(Dirty)。在執行 Young GC時,G1會檢查這些卡表并找出所有的臟卡片,然后只掃描這些臟卡片對應的內存區域,以更新老年代到年輕代的引用,避免每次 Young GC時都會掃描整個老年代。
如下圖:假設 Region的大小為 1M,因此每個 Region就包含 2個卡表。對象D 指向對象E,對象 E所在的 Eden是一個收集集,它會包含一個 RSet,RSet里有一個 Entry(Key)指向對象 D所在的 Old區域的起始地址,這個 Key對應的 Value包含了卡表的信息。

好了,有了上述幾個知識點的鋪墊,接下來正式進入 G1 工作流程講解環節。
四、工作流程
1.兩條主線
為了更好地講解 G1回收過程,我特地整理了官方文檔的兩條主線(或者說兩個維度):回收過程 和 回收周期。
(1) 回收過程
回收過程是指 G1回收過程中會經歷哪些具體的步驟,從全局上看,包括年輕代回收(Young GC),老年代并發標記周期(Concurrent Marking Cycle),混合回收(Mixed GC)和 Full GC 4個過程。
而老年代并發標記周期(Concurrent Marking Cycle)又包含以下 5個過程:
- Initial Marking(初始標記)
- Root Region Scanning(根據掃描)
- Concurrent Marking(并發標記)
- Remark(重新標記)
- Copying/Cleanup(清除垃圾)
從回收過程角度,G1工作流程可以抽象成如下示意圖:
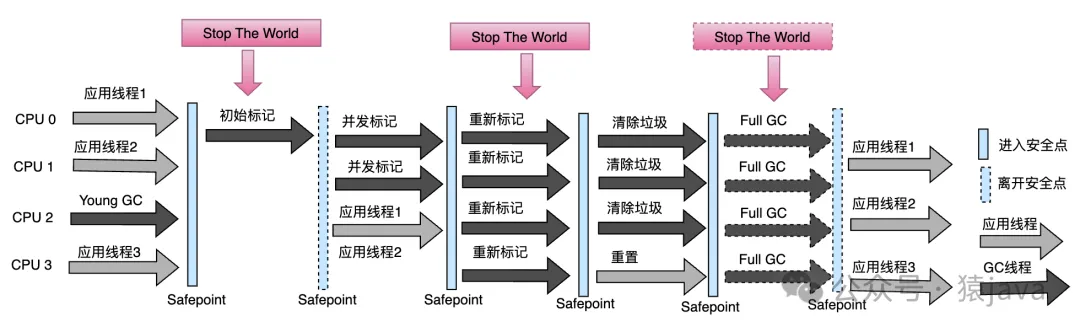
嚴格意義上講,Full GC并不能算是一個必需過程,它是 G1設計時需要盡量避免的,但因為這個點比較重要,所以還是把它放在過程中。
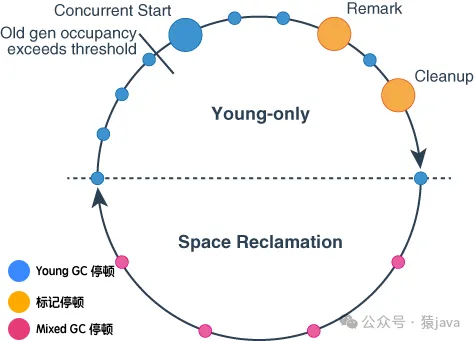
(2) 回收周期
回收周期是對應官方文檔的“On a high level”,它是對回收過程更高一層的抽象,包括 Young-only phase 和 Space-reclamation phase 兩個階段。
- Young-only phase:這里的“Young-only”是指垃圾收集器只會回收年輕代,該階段主要完成回收過程中的 年輕代回收(Young GC) 和 老年代并發標記周期(Concurrent Marking Cycle) 兩個過程。
- Space-reclamation phase:空間回收階段,該階段會進行多次年輕代收集(Young GC)以及增量回收部分老年代,被稱為混合收集(Mixed GC)。當 G1判斷繼續回收老年代不足以釋放更多的空間,或者停頓時間大于 MaxGCPauseMillis(默認 200ms)時,會退出該階段。空間回收階段對應回收過程中的混合回收(Mixed GC)。
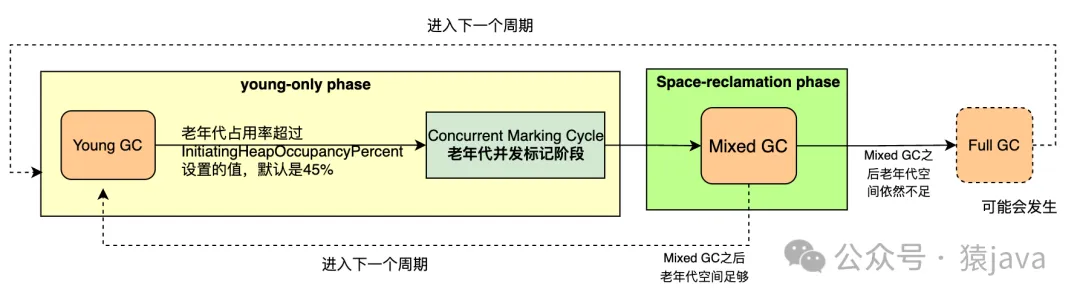
從回收周期角度,G1的工作流程可以抽象成如下示意圖:
扁平化后的示意圖:
最后,我們從回收過程和回收周期兩個維度進行對比,G1的工作流程可以抽象成如下示意圖:
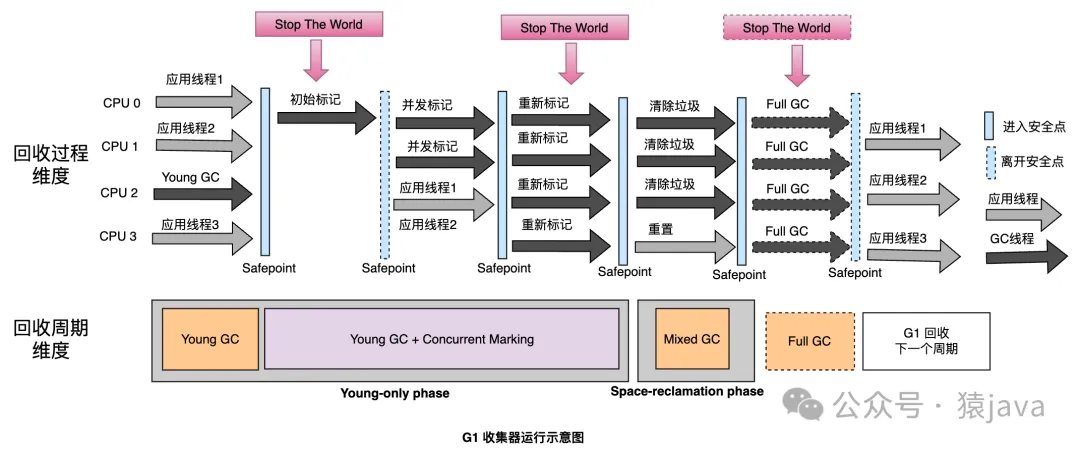
G1的實現細節比較難懂,但是我們可以通過上述兩條主線,從整體上去把握 G1,接下來,我們將逐步來分析 G1的工作流程。
2.回收過程詳解
(1) 年輕代回收
年輕代回收,顧名思義就是對年輕代的回收,它是一個 Stop The World的過程,當 Eden區的剩余空間無法完成新對象的分配時會觸發 Young GC,年輕代回收包含對 Eden區 和 Survivor區的回收, 具體表現為存活對象被復制或移動到一個或多個 Survivor區域,如果對象存活時間達到進入老年代(Old Generation)的閾值,對象將被提升到老年代。
G1 Young GC回收過程示意圖如下:

(2) 老年代并發標記周期
① Initial Mark(初始標記)
初始標記階段會 Stop The World(STW),但耗時很短,它是伴隨 Young GC同步完成的。
初始標記主要完成 2件事情:
- 標記 GC Roots直接關聯的對象
- 標記出所有的 survivor區(Root區)
下圖為一個簡單的初始標記過程示例:
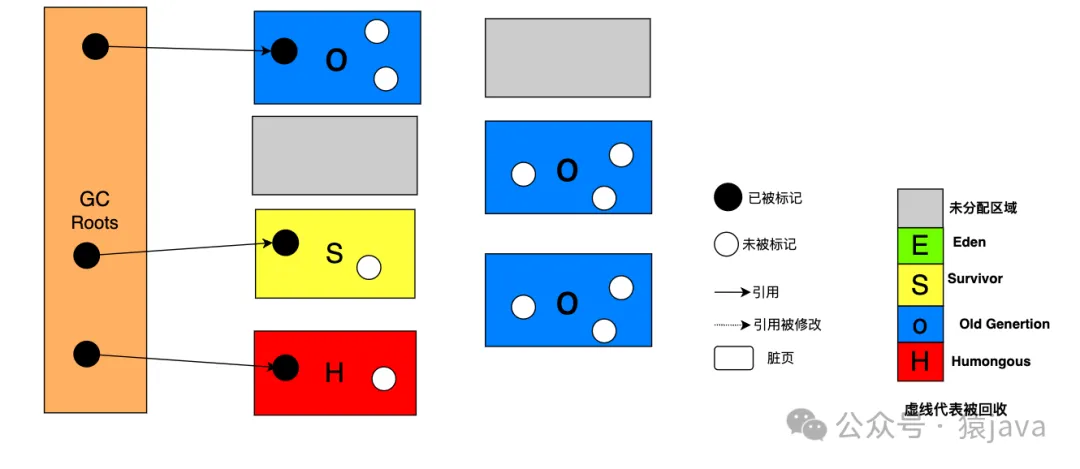
② 為什么初始標記會伴隨 Young GC?
最大的考慮是性能問題,這里給出兩個具體的理由:
- 減少停頓時間:Young GC會 Stop The World,而初始標記剛好借著這個停頓時間,做一些額外的標記工作,從而減少 STW的時間;
- 提升效率:Young GC是回收年輕代,而初始標記是標記年輕代和老年代中存活的對象。兩者結合,就可以把處理年輕代這個重疊的過程給復用了,提高垃圾收集的效率;
③ Root Region Scanning(根區掃描)
根區掃描主要是掃描 Survivor區指向老年代的引用。掃描線程和用戶線程是并發執行的, 另外,該過程必須在下一個 Young GC到來之前完成,主要原因是 Young GC會涉及到存活對象的在 Region間的移動, 因此,可能會改變 Survivor指向老年代的引用,從而影響數據的正確性。
④ Concurrent Marking(并發標記)
這里的并發是指 GC線程和用戶線程可以并發執行,并發標記階段的耗時會較長一些。
并發標記主要完成 3件事情:
- 從 GC Root開始,對堆中所有對象進行可達性分析,確認需要回收的對象
- 更新卡表
- 標記空的 Region
并發標記示意圖如下:
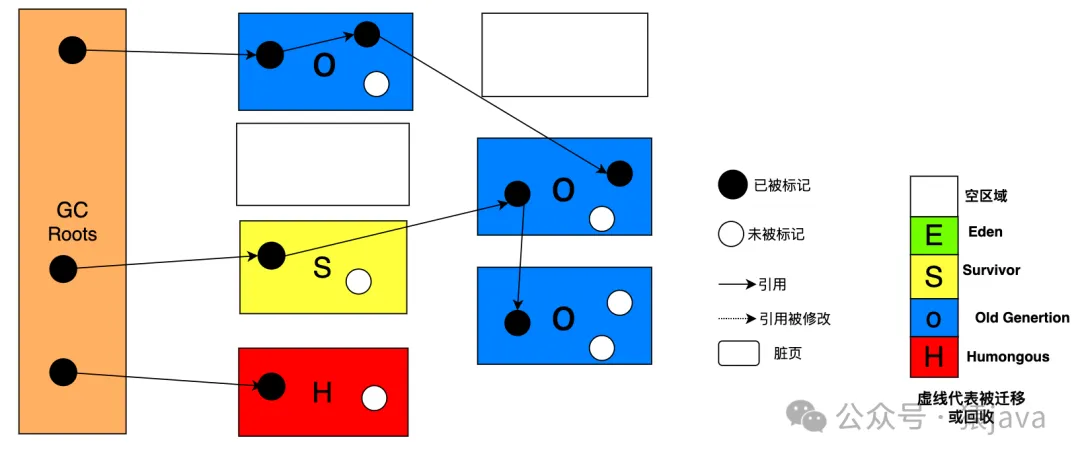
⑤ Remark(重新標記)
重新標記主要完成 2件事情:
- 回收并發標記過程中的空 Region
- 利用 Snapshot-At-The-Beginning (SATB) 修正并發標記中的數據
⑥ Cleanup(并發清理)
并發清除階段主要完成 3件事情:
- 對存活對象進行統計并完全釋放空閑區域。(STW)
- 清理記憶集(Remembered Sets)。(STW)
- 重置空閑區域并將它們返回到空閑列表。(并發執行)
(3) 混合回收
當老年代的堆使用率達到參數 -XX:InitiatingHeapOccupancyPercent 設定閾值(默認是 45%), 則觸發混合回收,混合回收階段會進行多次 Young GC 以及對部分老年代進行增量回收。
(4) Full GC
Fu1l GC 是 G1最后的防護線,它本是 G1設計時需要盡量避免的,嚴格上說,不應該作為一個過程來講,但是 Full GC是實際生產中大家比較關注的問題,所以作為一個過程來分析。
G1 主要通過以下幾個參數和指標來決定是否需要觸發Full GC:
- -XX:G1HeapWastePercent:堆中可以容忍的最大垃圾比例。如果在 Mixed GC之后,垃圾的比例超過了這個閾值,G1可能會觸發 Full GC來回收更多的空間。
- -XX:G1MixedGCLiveThresholdPercent:當 Old區中的對象占用的比例超過多少時,這部分區域會被包含在 Mixed GC中,默認 85。如果這個比例設置得太低,可能會導致過多的 Old區域被包含在 Mixed GC中,進而增加GC的工作量和停頓時間,最終可能引發 Full GC。
- -XX:G1MixedGCCountTarget:在開始進行 Full GC之前,可以執行 Mixed GC的最大次數。如果連續的 Mixed GC沒有有效地回收內存,達到這個次數限制后,G1可能會觸發 Full GC。
- -XX:G1ReservePercent:保留的堆內存的百分比,默認是10,作為一個緩沖區來減少 Full GC的發生。如果可用內存低于這個閾值,G1可能會觸發 Full GC。
五、G1 有幾個STW?
從上面我們對 G1的原理分析可以看出,在G1回收器中,STW事件主要發生在以下幾個階段:
- 初始標記(Initial Mark) :這是一個STW事件,標記從GC Roots直接可達的對象。
- 并發標記(Concurrent Marking) :這個階段大部分是并發的,但可能會有短暫的STW暫停來完成標記(Remark)。
- 最終標記(Remark) :這是一個STW事件,用于完成標記過程,處理在并發標記階段發生變化的對象。
- 清理(Cleanup) :部分操作可能會導致短暫的STW暫停。
- 混合垃圾收集(Mixed GC) :在這個階段,可能會有多個STW暫停,但每次暫停的時間通常較短。
因此,G1的STW總數是 2 + N,N發生在步驟4和步驟5,而且次數是不確定的。
六、總結
本文,我們全面分析 G1的工作原理,因為 G1涉及的知識點太多,所以文章從兩條主線(回收過程和回收周期)進行講解,通過分析原理,我們總結出了G1 中Stop The World 的次數。




















