RabbitMQ vs Kafka,別再選錯了!!!
作為一名有著大量微服務系統處理經驗的軟件架構師,我經常遇到一個不斷重復的問題:“我應該使用 RabbitMQ 還是 Kafka?”出于某種原因,許多開發人員認為這些技術是可以互換的。雖然在某些情況下確實如此,但 RabbitMQ 還是 Kafka 之間存在根本上的差異。
因此,不同的場景需要不同的解決方案,選擇錯誤的方案會嚴重影響我們的軟件開發設計以及后續維護軟件。
本文的目標首先是介紹基本的異步消息傳遞模式。然后繼續介紹 RabbitMQ 和 Kafka 及其內部結構。

一、異步消息傳遞模式
異步消息傳遞是一種消息傳遞方案,其中生產者的消息生成與消費者的消息處理分離。在消息傳遞系統中,我們通常會分為兩種主要的消息傳遞模式:隊列模式和發布/訂閱模式。
1.隊列模式
在隊列模式中,隊列暫時將生產者與消費者解耦。多個生產者可以向同一個隊列發送消息。然后當消費者處理消息時,消息會被鎖定然后從隊列中刪除,并且不再可用。
隊列模式通常就是一個消息只能被一個消費者處理。

消息隊列
附帶說明一下,如果消費者無法處理某個消息,消息平臺通常會將消息返回到隊列,以供其他消費者使用。除了解耦之外,隊列還允許我們擴展生產者和消費者,并針對錯誤處理提供容錯能力。
2.發布/訂閱模式
在發布/訂閱模式中,單個消息可以由多個訂閱者同時接收和處理。

發布/訂閱
例如,此模式允許發布者通知所有訂閱者系統中發生了某些情況。在 RabbitMQ 中,關注工眾號:碼猿技術專欄,回復關鍵詞:1111 獲取阿里內部Java性能調優手冊!主題是一種特定類型的 pub/sub 實現(確切地說是一種交換類型),但在本文中,我將主題稱為整個 pub/sub 的表示。
一般來說,訂閱有兩種類型:
- 臨時訂閱,其中訂閱僅在使用者啟動并運行時才有效。一旦消費者關閉,他們的訂閱和尚未處理的消息就會丟失。
- 持久訂閱,只要未顯式刪除,訂閱就會得到維護。當消費者關閉時,消息平臺會維持訂閱,稍后可以恢復消息處理。
二、RabbitMQ
RabbitMQ 是消息代理的一種實現 — 通常稱為服務總線。它本身支持上述兩種消息傳遞模式。消息代理的其他流行實現包括 ActiveMQ、ZeroMQ、Azure 服務總線和 Amazon Simple Queue Service (SQS)。所有這些實現都有很多共同點,本文中描述的許多概念適用于其中的大多數。
1.Queues
RabbitMQ 支持開箱即用的經典消息隊列。開發人員定義命名隊列,然后發布者可以將消息發送到該命名隊列。反過來,消費者使用相同的隊列來檢索消息來處理它們。
2.Message exchanges
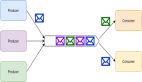
RabbitMQ 通過使用消息交換機來實現 pub/sub。發布者將其消息發布到消息交換機,不用知道這些消息的訂閱者是誰。
每個訂閱交換機的消費者都會創建一個隊列,然后消息交換機將生成的消息排隊以供消費者使用。它還可以根據各種路由規則過濾某些訂閱者的消息。

RabbitMQ message exchange
值得注意的是,RabbitMQ 支持臨時訂閱和持久訂閱。消費者可以通過 RabbitMQ 的 API 決定他們想要使用的訂閱類型。
由于 RabbitMQ 的架構,我們還可以創建一種混合方法,其中一些訂閱者形成消費者組,這些消費者組以特定隊列上競爭消費者的形式共同處理消息。通過這種方式,我們實現了發布/訂閱模式,同時還允許一些訂閱者擴展以處理接收到的消息。

發布/訂閱和隊列相結合
三、Apache Kafka
Apache Kafka 是一個分布式流處理平臺。
與基于隊列和交換的 RabbitMQ 不同,Kafka 的存儲層是使用分區事務日志實現的。Kafka 還提供了 Streams API 來實時處理流,以及 Connectors API 來輕松與各種數據源集成。不過,這些超出了本文的范圍。
云服務商為 Kafka 的存儲層提供了替代解決方案。這些解決方案包括 Azure 事件中心,在某種程度上還包括 AWS Kinesis Data Streams。Kafka 的流處理功能還有特定于云的開源替代方案,同樣,這些也超出了本文的范圍。
1.Topics
Kafka 沒有實現隊列的概念。Kafka 將記錄集合存儲在稱為主題的類別中。
對于每個主題,Kafka 都會維護一個分區的消息日志。每個分區都是一個有序的、不可變的記錄序列,其中不斷附加消息。
Kafka 在消息到達時將其附加到這些分區。默認情況下,它使用循環分區器在分區之間均勻地傳播消息。
生產者可以修改此行為以創建邏輯消息流。例如在多租戶應用程序中,我們可能希望根據每條消息的租戶 ID 創建邏輯消息流。在物聯網場景中,我們可能希望將每個生產者的身份不斷映射到特定分區。確保來自同一邏輯流的所有消息映射到同一分區,以保證它們按順序傳遞給消費者。

Kafka producers
消費者通過維護這些分區的偏移量(或索引)并按順序讀取它們來消費消息。
單個消費者可以使用多個主題,并且消費者可以擴展,直至與可用分區數量一致。
因此,在創建主題時,應仔細考慮該主題的消息傳遞的預期吞吐量。共同消費某個主題的一組消費者稱為消費者組。Kafka 的 API 通常負責消費者組中消費者之間分區處理的平衡以及消費者當前分區偏移量的存儲。

Kafka consumers
2.使用 Kafka 實現消息傳遞
Kafka 的內部實現其實很好地反映了 pub/sub 模式。
生產者可以向特定主題發送消息,多個消費者組可以消費同一條消息。每個消費者組都可以單獨擴展以處理負載。由于消費者維護其分區偏移量,因此他們可以選擇持久訂閱(在重新啟動時維持其偏移量)或臨時訂閱(即丟棄偏移量并在每次啟動時從每個分區中的最新記錄重新啟動)。
Kafka 其實是不太適合隊列模式的消息傳遞。當然我們可以創建一個只有一個消費者組的主題來模擬經典的消息隊列。但這有多個缺點,在本文第 2 部分我們將詳細討論。
第 2 部分文章地址:https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41
值得注意的是,無論消費者是否消費了這些消息,Kafka 都會將消息保留在分區中直至預先配置的時間段內。這種保留意味著消費者可以自由地重讀過去的消息。此外,開發人員還可以使用 Kafka 的存儲層來實現事件溯源和審計日志等機制。
四、最后
雖然 RabbitMQ 和 Kafka 有時可以互換,但它們的實現卻截然不同。因此,我們不能將它們視為同一類別工具的成員。一個是消息代理,另一個是分布式流平臺。
作為解決方案架構師,我們應該認識到這些差異,并積極考慮針對給定場景應使用哪些類型的解決方案。