譯者 | 布加迪
審校 | 重樓
幾十年來,以Elasticsearch為代表的關鍵詞匹配(又稱為全文搜索)一直是企業搜索和推薦引擎等信息檢索系統的默認選擇。

隨著基于人工智能的搜索技術不斷進步,如今企業組織在向語義搜索轉變,從而使系統能夠理解用戶查詢背后的含義和意圖。嵌入模型和矢量數據庫已成為這一轉變的核心。
語義搜索將數據表示為矢量嵌入,從而比關鍵字匹配更勝一籌,提供了對搜索意圖更深入細致的理解,并徹底改變從檢索增強生成(RAG)到多模態搜索的各種應用場景。
在實踐中,有效的信息檢索系統既需要語義理解,又需要精確的關鍵詞匹配。比如說,用戶希望搜索結果顯示與其搜索查詢相關的概念,又同時尊重查詢中使用的字面文本,比如特殊術語和名稱,并返回精確匹配的結果。
基于密集矢量的語義搜索有助于理解含義(比如知道“car”和“automobile”是同一個意思),而傳統的全文搜索提供用戶期望的精確結果(比如找到“Python 3.9”的精確匹配)。因此,許多組織正在采用混合搜索方法,結合兩種方法的優勢,以兼顧靈活的語義相關性和可預測的精確關鍵字匹配。
混合搜索面臨的挑戰
實現混合搜索的一種常見方法是使用專門構建的矢量數據庫(比如開源Milvus)進行高效、可擴展的語義搜索,同時使用傳統的搜索引擎(比如Elasticsearch或OpenSearch)進行全文搜索。
雖然這種方法可以獲得良好的效果,但也帶來了新的復雜性。管理兩個不同的搜索系統意味著要處理不同的基礎設施、配置和維護任務,這會造成更沉重的操作負擔,并加大潛在集成問題的可能性。
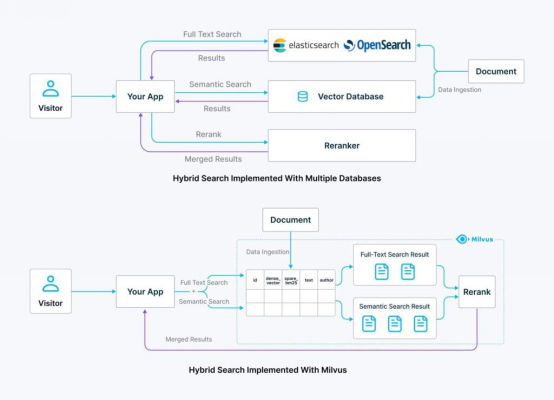
混合搜索的統一解決方案帶來了許多好處:
- 減少基礎設施維護:管理一個系統而不是兩個系統大大降低了操作復雜性,還節省了時間和資源。這也意味著可以減少上下文切換和掌握兩組不同API的麻煩。
- 統一的數據管理:統一的表結構允許你存儲密集數據(基于矢量)和稀疏數據(基于關鍵字)以及共享的元數據標簽。使用兩個獨立的系統需要將元數據標簽存儲兩次,以便雙方能夠進行元數據過濾。
- 簡化的查詢:單單一個請求可以執行語義搜索任務和全文搜索任務,因而不需要對不同的系統進行兩次API調用。
- 增強的安全性和訪問控制:統一的方法可以實現更直接、更穩健的安全管理,因為所有訪問控制都可以在矢量數據庫中加以集中管理,從而增強了安全合規和一致性。
統一矢量方法如何簡化混合搜索?
在語義搜索中,機器學習模型基于文本的含義,將文本作為點(即密集矢量)“嵌入”到高維空間中。語義相似的文本在這個空間中彼此挨得更近。比如說,“apple”(蘋果)和“fruit”(水果)在這個空間中可能比“apple”(蘋果)和“car”(汽車)挨得更近。這便于我們只需使用近似最近鄰(ANN)算法計算每個點之間的距離,就可以快速找到語義相關的文本。
通過將文檔和查詢編碼為稀疏矢量,該方法還可以應用于全文搜索。在稀疏矢量中,每個維度表示一個術語,其值表示每個術語在文檔中的重要程度。
文檔中沒有出現的術語的值為零。由于任何給定的文檔通常只使用詞匯表中所有可能術語的一小部分,因此大多數術語不會出現在文檔中。這意味著得到的矢量是稀疏矢量——它們的值大部分是0。比如說,在通常用于評估信息檢索任務的MS-MARCO數據集中,雖然有大約900萬個文檔和100萬個獨特的術語,但搜索系統通常將這個龐大集合分成比較小的部分,以便于管理。
即使在片段級別,詞匯表中有數十萬個術語,每個文檔通常包含少于100個術語,這意味著每個矢量的值超過99%為0。這種極端稀疏性對我們有效地存儲和處理這些矢量的方式有著重要的意義。
可以利用這種稀疏模式來優化搜索性能,同時保持準確性。最初為密集矢量設計的矢量數據庫可加以改動,以便有效地處理這些稀疏矢量。比如說,開源矢量數據庫Milvus剛剛發布了原生全文搜索支持,使用Sparse-BM25,這是Elasticsearch及其他全文搜索系統使用的BM25算法的稀疏矢量實現。Sparse-BM25借助以下機制,充分發揮了基于近似的全文搜索優化:
- 基于數據修剪的高效檢索算法:通過運用基于啟發式方法的修剪,丟棄片段索引中稀疏矢量值最低的文檔,并忽略搜索查詢中的低值稀疏矢量,矢量數據庫就可以顯著減少索引大小,優化性能,同時確保質量損耗最小。
- 充分利用進一步的性能優化:將術語頻率表示為稀疏矢量而不是反向索引,可以實現額外的基于矢量的優化。這些包括:
- 圖索引用于比蠻力掃描更有效的搜索。
- 產品量化(PQ)/標量量化(SQ)進一步減少內存占用。
除了這些優化外,Sparse-BM5實現還繼承了高性能矢量數據庫Milvus的幾個系統級優勢:
- 高效的低級實現和內存管理:Milvus的核心矢量索引引擎是用C++實現的,提供了比Elasticsearch等基于Java的系統更高效的內存管理。與基于JVM的方法相比,僅這一點就可以節省數GB,從而減少內存占用。
- 支持MMap:與Elasticsearch在內存和磁盤中使用頁面緩存用于存儲索引相似,Milvus支持內存映射(MMap),以便在索引超過可用內存時擴展內存容量。
為什么傳統的搜索堆棧面對矢量搜索表現不佳?
Elasticsearch是為傳統的反向索引構建的,這使得它從根本上難以為密集矢量搜索進行優化。其影響顯而易見:即使只有100萬個矢量,Elasticsearch也需要3770毫秒(ms)來返回搜索結果,而Milvus僅需6毫秒,足足相差600倍。這種性能差距隨著規模的擴大而拉大,Elasticsearch的Java/JVM實現很難與基于C++ /Go的矢量數據庫的可擴展性相匹配。此外,Elasticsearch缺乏關鍵的矢量搜索功能,比如基于磁盤的索引(DiskAnn和MMap)、經過優化的元數據過濾以及范圍搜索。
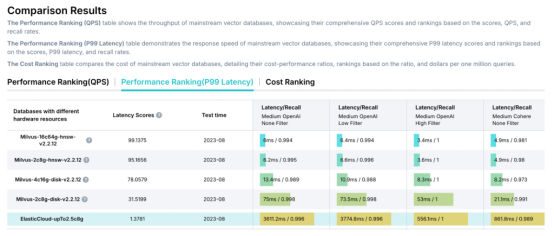 VectorDBBench基準測試結果
VectorDBBench基準測試結果
結語
以Milvus為代表的矢量數據庫有望超越Elasticsearch,成為混合搜索的統一解決方案。通過將密集矢量搜索與經過優化的稀疏矢量技術相結合,矢量數據庫提供了卓越的性能、可擴展性和效率。
這種統一的方法簡化了基礎設施,減少了內存占用,并增強了搜索功能,使其可以滿足未來的高級搜索需求。因此,矢量數據庫提供了一種全面的解決方案,可以無縫地結合語義搜索和全文搜索,性能比Elasticsearch等傳統的搜索系統更勝一籌。
原文標題:Elasticsearch Was Great, But Vector Databases Are the Future,作者:Jiang Chen