













synchronized 在 Java 多線程環境下的優秀實踐
在 Java 多線程環境中,synchronized 關鍵字是一種常用的同步機制,用于確保多個線程對共享資源的互斥訪問。合理使用synchronized 可以有效避免數據競爭和不一致問題,但不當使用也可能導致性能瓶頸或死鎖。本文將探討synchronized 在多線程環境下的最佳實踐,幫助開發者更好地理解和應用這一機制。

詳解synchronized幾個經典錯誤范例
1.正確鎖住共享資源保證原子性
看下面這段代碼,有兩個volatile變量a、b,然后有兩個線程操作這兩個變量,一個變量對a、b進行自增,另一個線程發現a<b的時候就打印a>b的結果:
private volatile int a = 1;
private volatile int b = 1;
public void add() {
log.info("add start");
//循環累加
for (int i = 0; i < 100_0000; i++) {
a++;
b++;
}
log.info("add done");
}
public void compare() {
log.info("compare start");
for (int i = 0; i < 100_0000; i++) {
//如果a<b,則打印a>b的結果
if (a < b) {
log.info("a:{},b:{},a>b:{} ", a, b, a > b);
}
}
log.info("compare done");
}隨后我們給出兩個線程分別調用add和compare方法:
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Main interesting = new Main();
//線程1
new Thread(() -> {
interesting.add();
countDownLatch.countDown();
},"t1").start();
//線程2
new Thread(() -> {
interesting.compare();
countDownLatch.countDown();
},"t2").start();
countDownLatch.await();
}結果出現了很奇怪的現象,我們發現進行了某些線程得到了進入了a<b的if分支,偶發的輸出a>b結果卻為true:
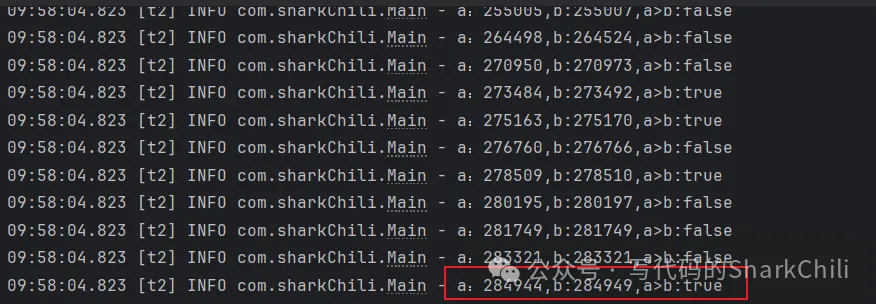
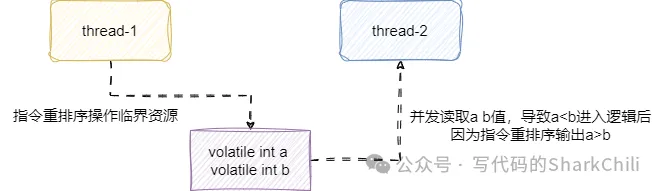
盡管我們使用volatile保證了兩個變量的可見性,確保一個線程變量對于另一個線程是可見的。但我們沒有保證臨界資源的互斥,即線程2判斷到a<b的時候,線程1依然可以操作變量a和b這就會導致下面這種情況:
- 線程1的add方法發生重排序,進行a、b變量的自增。
- 線程2在線程1的某個執行點得到a<b。
- 線程1進入邏輯后嘗試讀取a和b的結果,由于處理器或者JIT等原因,此時自增的指令發生重排序,導致自增順序被打亂。
- 線程2打印a大于b的結果變為true。
很明顯導致問題的原因就是兩個線程進行并發操作時沒有保證單位時間內只有一個線程操作臨界資源,結合as-if-serial規則在單線程的情況下,指令重排序只能對不影響處理結果的部分進行重排序,這就導致并發操作其間a、b結果大小可能是瞬息萬變的。
所以我們都在實例方法上添加一個synchronized 關鍵字,確保每一次操作都能鎖住實例對象,避免另一個線程操作:
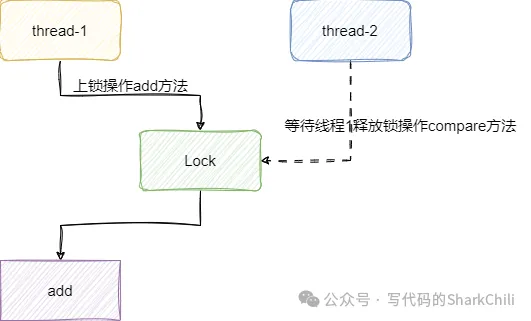
對應我們給出修改后的代碼,因為操作臨界資源時上了鎖,單位時間內只有一個線程可以操作臨界資源,對應的問題就有了很好的解決:
public synchronized void add() {
log.info("add start");
for (int i = 0; i < 100_0000; i++) {
b++;
a++;
}
log.info("add done");
}
public synchronized void compare() {
log.info("compare start");
for (int i = 0; i < 100_0000; i++) {
//如果a<b,則打印a>b的結果
if (a < b) {
log.info("a:{},b:{},a>b:{} ", a, b, a > b);
}
}
log.info("compare done");
}2.確保鎖住的對象和鎖屬于統一層級
在來看一個例子,我們現在有這么一個Data 對象,它包含一個靜態變量counter。還有一個重置變量值的方法reset。
@Slf4j
public class Data {
@Getter
@Setter
private static int counter = 0;
public static int reset() {
counter = 0;
return counter;
}
}這個變量需要被多線程操作,于是我們給它添加了一個add方法:
public synchronized void wrongAdd() {
counter++;
}測試代碼如下,你們猜猜最終的結果是多少呢?
public static void main(String[] args) {
Data.reset();
IntStream.rangeClosed(1, 100_0000)
.parallel()
.forEach(i -> {
new Data().wrongAdd();
});
log.info("counter:{}", Data.getCounter());
}輸出結果如下,感興趣的讀者可以試試看,這個值幾乎每一次都不一樣。原因是什么呢?
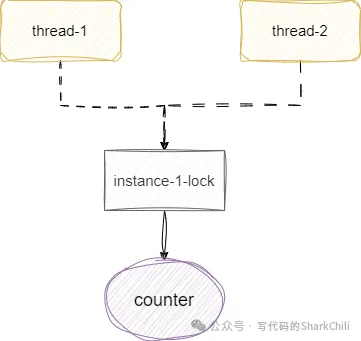
2023-03-19 14:42:53,006 INFO Data:54 - counter:390472仔細看看我們的add方法,它在實例上方法上鎖,鎖的對象是當前對象,在看看我們的代碼并行流中的每一個線程的寫法,永遠都是new一個data對象執行add方法,大家各自用各自的鎖,很可能出現兩個線程同時讀取到一個值0,然后一起自增1,導致最終結果變為1而不是2:
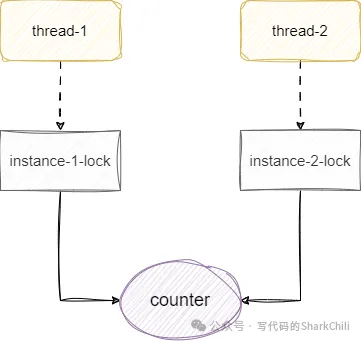
如果可以改變調用方式,那么我們就讓所有線程使用同一個實例對象,保證上的鎖都是基于同一個實例的對象鎖:
public static void main(String[] args) {
Data.reset();
Data data = new Data();
IntStream.rangeClosed(1, 100_0000)
.parallel()
.forEach(i -> {
data.wrongAdd();
});
log.info("counter:{}", Data.getCounter());
}
輸出結果:
2023-03-19 14:44:26,972 INFO Data:55 - counter:1000000如果不能改變調用方式,我們就修改調用方法,讓所有對象實例都用同一把鎖。
private static Object locker = new Object();
public synchronized void rightAdd() {
synchronized (locker) {
counter++;
}
}可以看到輸出結果也是正確的:
2023-03-19 14:55:21,095 INFO Data:56 - counter:10000003.避免鎖的粒度過粗
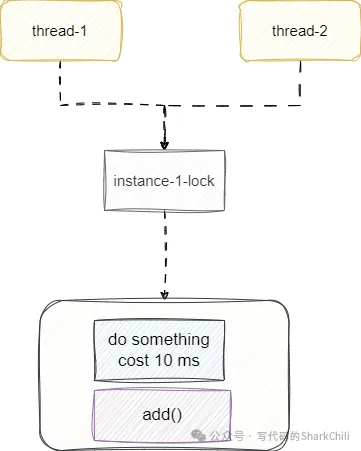
有時候我們鎖使用的確實沒有錯,但是鎖的粒度太粗了,將一些非常耗時的方法放到鎖里面,導致性能問題,就像下面這段代碼。我們用slow模擬耗時的方法,將slow放到鎖里面,這意味每個線程得到鎖就必須等待上一個線程完成這個10毫秒的方法加需要上鎖的業務邏輯才行。
private static List<Object> list = new ArrayList<>();
public void slow() {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void add() {
synchronized (Test.class) {
slow();
list.add(1);
}
}
我們的壓測代碼如下:
StopWatch stopWatch = new StopWatch();
stopWatch.start("add ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");輸出結果如下,可以看到1000個并行流就使用了15s左右:
-----------------------------------------
ms % Task name
-----------------------------------------
15878 084% add 所以我們需要對這個代碼進行一次改造,將耗時的操作放到鎖外面,讓耗時操作放在臨界資源之外,保證CPU感知到線程休眠,可以及時切換執行其他線程休眠邏輯,盡可能利用CPU讓盡可能多的線程進入IO狀態然后進入鎖內部操作:
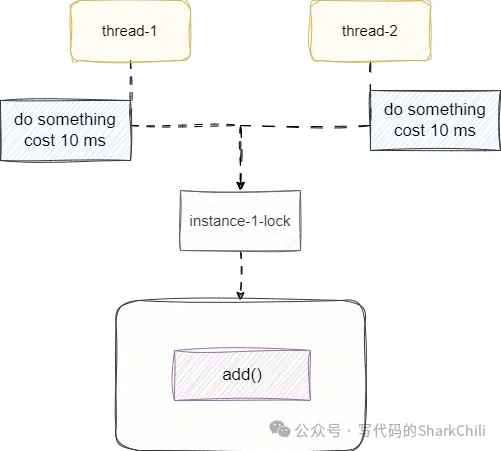
public void add2() {
slow();
synchronized (Test.class) {
list.add(1);
}
}我們再來完整壓測一次:
@org.junit.Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("add ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");
list.clear();
stopWatch.start("add2 ");
IntStream.rangeClosed(1, 1000).parallel()
.forEach(i -> {
new Test().add2();
});
stopWatch.stop();
Assert.isTrue(list.size() == 1000, "size error");
log.info(stopWatch.prettyPrint());
}可以看到改造后的性能遠遠高于前者:
2023-03-19 15:10:47,888 INFO Test:69 - StopWatch '': running time (millis) = 18853
-----------------------------------------
ms % Task name
-----------------------------------------
15878 084% add
02975 016% add2 4.死鎖問題
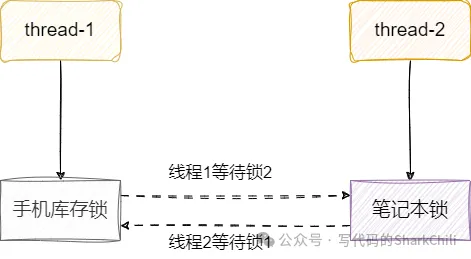
有時候鎖使用不當可能會導致線程死鎖,其中造成死鎖最經典的原因就是環路等待。
如下圖,線程1獲取鎖1之后還要獲取鎖2,才能操作臨界資源,這意味著線程1必須同時拿到兩把鎖完成手頭工作后才能釋放鎖。 同理線程2先獲取鎖2再去獲取鎖1,才能操作臨界資源,同樣必須操作完臨界資源后才能釋放鎖。雙方就這樣拿著對方需要的東西互相阻塞僵持著,造成死鎖。
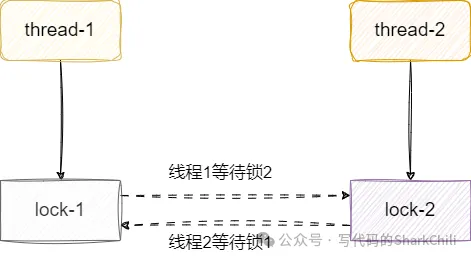
我們現在有這樣一個需求,不同用戶需要購買不同的商品,用戶執行庫存扣減的時候必須拿到所有需要購買的商品的鎖才成完成庫存扣減。
例如用戶1想購買筆者本和手機,它就必須同時拿到手機和筆者本兩個商品的鎖才能操作資源。這種做法可能會導致上述所說的死鎖問題,有個用戶打算先買筆者本再買手機,另一個用戶打算先買手機再買筆者本,這使得他們獲取鎖的順序是相反的,如果他們同時執行業務邏輯。雙方先取的各自的第一把鎖,準備嘗試獲取第二把鎖的時候發現鎖被對方持有,雙方僵持不下,造成線程死鎖。
我們不妨來演示一下這個問題,首先我們先來看看商品表,可以看到P001為筆記本,P002為手表:
SELECT * FROM product p ;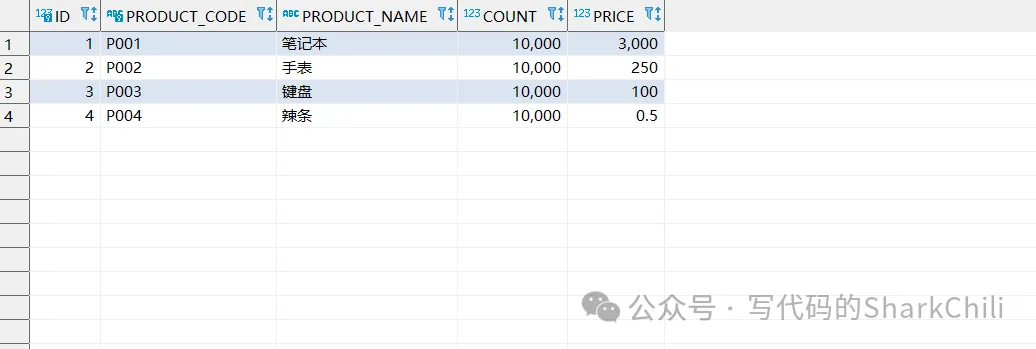
為了保證所有的商品的鎖只有一把,我們會使用一個靜態變量來存儲所有商品的鎖。所以我們現在controller上定義一個靜態變量productDTOMap ,key為商品的code,value為商品對象,這個商品對象中就包含扣減庫存時需要用到的鎖。
private static Map<String, ProductDTO> productDTOMap = new HashMap<>();然后我們的controller就用InitializingBean 這個擴展點完成商品鎖的加載。
@RestController
@RequestMapping()
public class ProductController implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
//獲取商品
List<Product> productList = productService.list();
//將商品轉為map,用code作為key,ProductDTO 作為value,并為其設置鎖ReentrantLock
productDTOMap = productList.stream()
.collect(Collectors.toMap(p -> p.getProductCode(), p -> {
ProductDTO dto = new ProductDTO();
dto.setLock(new ReentrantLock());
return dto;
}));
}
}接下來就能編寫我們的庫存扣減的邏輯了,步驟很簡單:
- 根據用戶傳入的code找到對應的商品對象。
- 獲取要購買的商品的鎖。
- 所有鎖都拿到完成商品扣減,有一把鎖沒拿到則將所有的鎖都釋放并返回false告知用戶本地下單失敗。
@PostMapping("/product/deductCount")
ResultData<Boolean> deductCount(@RequestBody List<String> codeList) {
//獲取商品
QueryWrapper<Product> query = new QueryWrapper<>();
query.in("PRODUCT_CODE", codeList);
//存儲用戶獲得的鎖
List<ReentrantLock> lockList = new ArrayList<>();
//遍歷每個商品對象,并嘗試獲得這些商品的鎖
for (String code : codeList) {
if (productDTOMap.containsKey(code)) {
try {
ReentrantLock lock = productDTOMap.get(code).getLock();
//如果得到這把鎖就將鎖存到list中
if (lock.tryLock(60, TimeUnit.SECONDS)) {
lockList.add(lock);
} else {
//只要有一把鎖沒有得到,就直接將list中所有的鎖釋放并返回false,告知用戶下單失敗
lockList.forEach(l -> l.unlock());
return ResultData.success(false);
}
} catch (InterruptedException e) {
logger.error("上鎖失敗,請求參數:{},失敗原因:{}", JSON.toJSONString(codeList), e.getMessage(), e);
return ResultData.success(false);
}
}
}
//到這里說明得到了所有的鎖,直接執行商品扣減的邏輯了
try {
codeList.forEach(code -> {
productService.deduct(code, 1);
});
} finally {
//釋放所有的鎖
lockList.forEach(l -> l.unlock());
}
//返回結果
return ResultData.success(true);
}完成后我們即可通過下面這個地址進行請求:
http://localhost:9002/product/deductCount對應的我們的請求可以基于下面這個參數順序調換進行請求,為方便復現死鎖問題讀者可以通過多線程調試模式將實現兩個線程先拿各自的一把鎖,然后嘗試獲取對方鎖的情況:
# 線程1參數
[
"P001",
"P002"
]
# 線程2參數
[
"P002",
"P001"
]發現請求阻塞之后,通過jstack 查看應用使用情況。
jstack -l 6792從控制臺可以看到,正是環路等待的取鎖順序,導致我們tryLock的方法上出現了死鎖的情況。
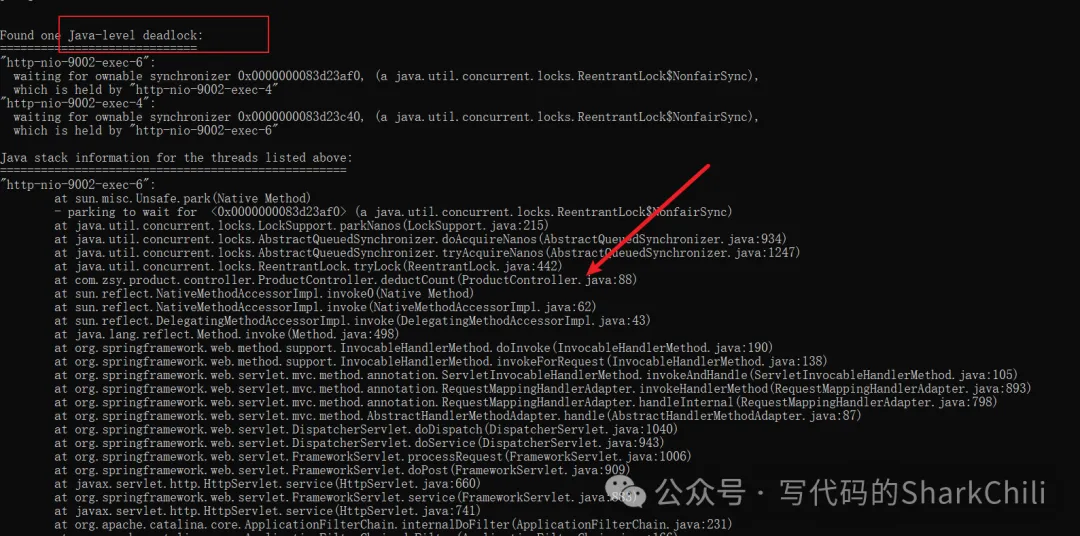
解決方式也很簡單,既然造成死鎖的原因是雙方取鎖順序相反,那么我們為什么不讓兩個線程按照相同的順序取鎖呢?
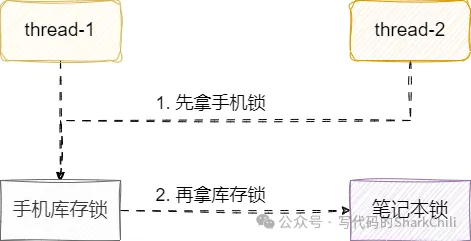
我們將雙方購買的商品順序,按照code排序一下,讓兩個線程都按照同一個方向的順序取鎖,不就可以避免死鎖問題了?代碼改動的地方很少,只需添加這樣一行讓用戶商品code排下序,這樣后續的取鎖邏輯就保持一致了。
Collections.sort(codeList);小結
鎖雖然可以解決線程安全問題,但是使用時必須注意以下幾點:
- 注意保證鎖的原子性。
- 注意鎖的層級,實例對象之間競爭就必須同一個對象作為鎖而不是各自的實例對象。
- 注意鎖的粒度不能過大,避免將不會造成線程安全且耗時的方法放到鎖中。
- 注意環路死鎖問題。



















