













五個基于 LLM 的開源爬蟲項目
由于互聯網在技術、內容、渠道等方面越來越多樣化,并且不斷在演變。傳統的爬蟲大多時候都要根據網頁進行定制開發。這種道高一尺魔高一丈的循環,意味著要把有限精力投入到無限的變化中,難以動態響應互聯網的變化。基于AI的網頁數據提取可以像人類一樣動態地瀏覽數據、理解數據。其優勢主要有:實時適應不斷變化的網站結構,精確提取需要的內容,用類似人類的方法解析內容,以多種格式生成干凈的結構化數據,輕松處理海量數據抓取。
為了便于學習借鑒,下面主要推薦幾個比較好的開源的AI爬蟲項目。

1.crawl4ai
https://github.com/unclecode/crawl4ai
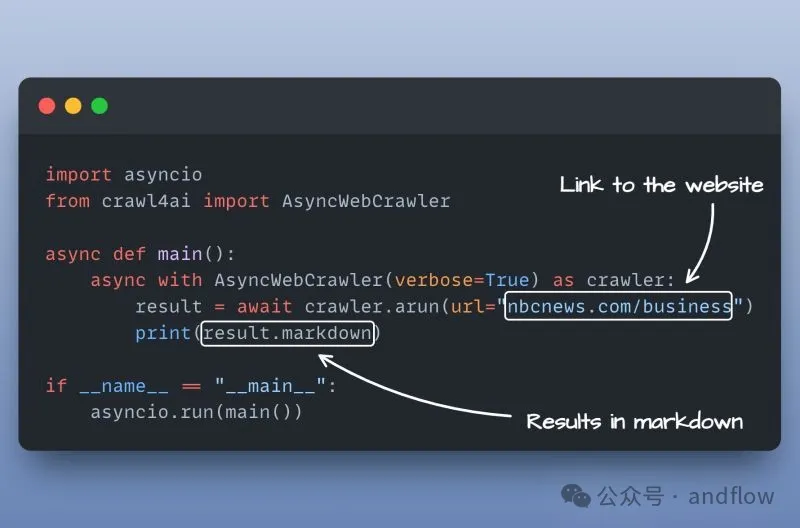
Crawl4AI簡化了Web數據異步提取的過程,使Web數據提取簡單高效,非常適合AI和LLM應用程序。
優勢特征:
- 100%開源免費。
- 閃電般的性能:在快速可靠的抓取方面優于許多付費服務。
- 基于AI LLM構建:以JSON、HTML或markdown格式輸出數據。
- 多瀏覽器支持:可與Chromium、Firefox和WebKit無縫配合。
- 可同時抓取多個URL:一次處理多個網站,以實現高效的數據提取。
- 全媒體支持:輕松提取圖像、音頻、視頻以及所有HTML媒體標簽。
- 提取鏈接:獲取所有內部和外部鏈接以獲得更深入的數據挖掘。
- XML元數據檢索:捕獲頁面標題、描述和其他元數據。
- 可定制:添加用于身份驗證、標題或自定義頁面修改的功能。
- 支持匿名:自定義用戶代理設置。
- 支持截圖:具備強大的錯誤處理功能,拍攝頁面快照。
- 自定義JavaScript:在抓取定制結果之前執行腳本。
- 結構化數據輸出:根據規則生成良好的JSON數據。
- 智能提取:使用LLM、集群、正則表達式或CSS選擇器進行準確的數據抓取。
- 代理驗證:通過安全代理支持訪問受保護的內容。
- 會話管理:輕松處理多頁導航。
- 圖像優化:支持延遲加載和響應式圖像。
- 動態內容處理:管理交互式頁面的延遲加載。
- 對LLM友好的頭文件:為特定于LLM的交互傳遞自定義頭文件。
- 精確提取:使用關鍵字或指令優化結果。
- ?靈活的設置:調整超時和延遲,以實現更流暢的抓取。
- iframe支持:提取iframe中的內容,以獲得更深入的數據提取。
2.Scrapegraph-ai
https://github.com/ScrapeGraphAI/Scrapegraph-ai
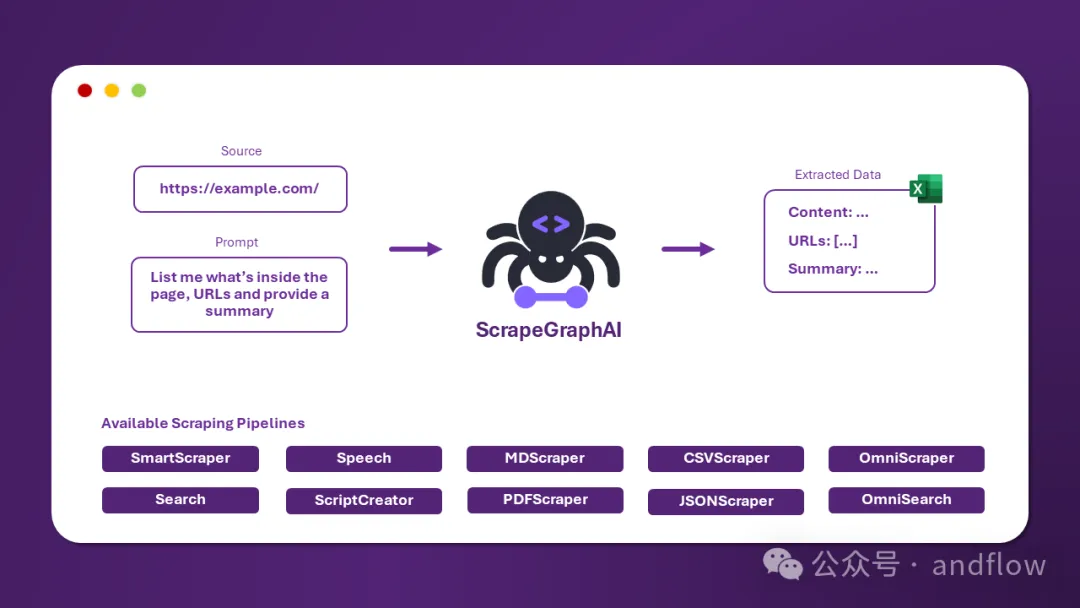
ScrapeGraphAI是一個用于web數據爬取python庫,它使用LLM和邏輯圖為網站或者本地文檔(XML,HTML,JSON,Markdown等)創建抓取流程。
3.llm-scraper
https://github.com/mishushakov/llm-scraper
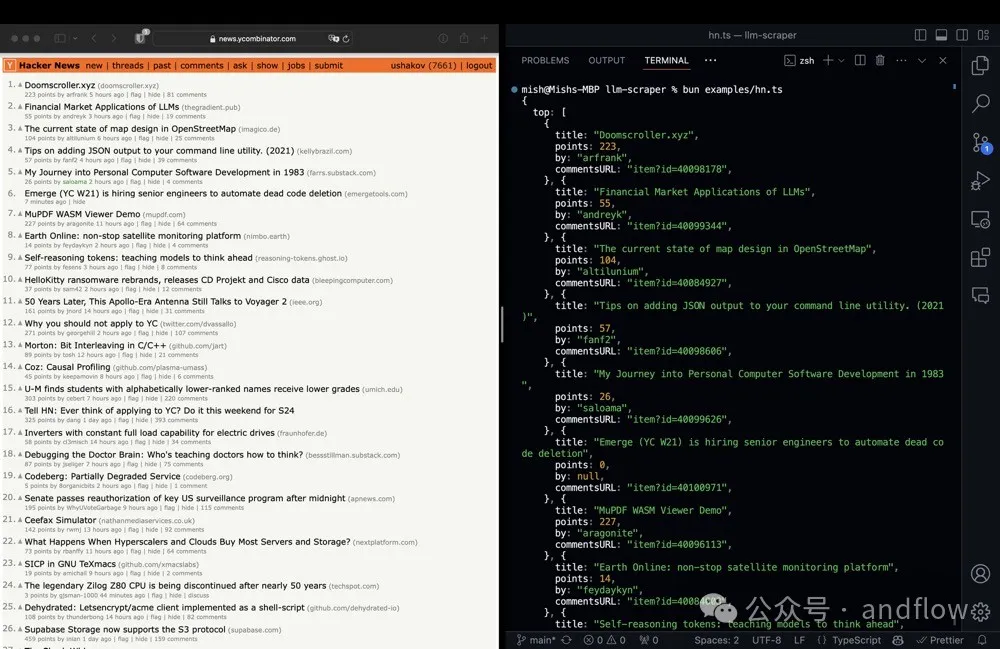
LLM Scraper是一個基于LLM的爬蟲TypeScript庫。并且支持代碼生成功能。
優勢特征:
- 支持本地或者MaaS提供商:Ollama、GGUF、OpenAI、Vercel AI SDK
- 使用Zod定義的模式
- 使用TypeScript實現完全類型安全
- 基于Playwright框架
- 流式對象
- 支持代碼生成
- 支持4種數據格式化模式:
- html用于加載原始HTML
- markdown用于加載markdown
- text用于加載提取的文本(使用Readability.js)
- image用于加載屏幕截圖(僅限多模式)
4.crawlee-python
https://github.com/apify/crawlee-python

Crawlee是一個Web爬蟲以及瀏覽器自動化Python庫。通過AI、LLM、RAG或GPT提取網頁數據,包括從網站下載HTML、PDF、JPG、PNG和其他文件。適用于BeautifulSoup、Playwright和原始HTTP。支持有頭和無頭模式,支持代理輪換規則。
5.CyberScraper
https://github.com/itsOwen/CyberScraper-2077
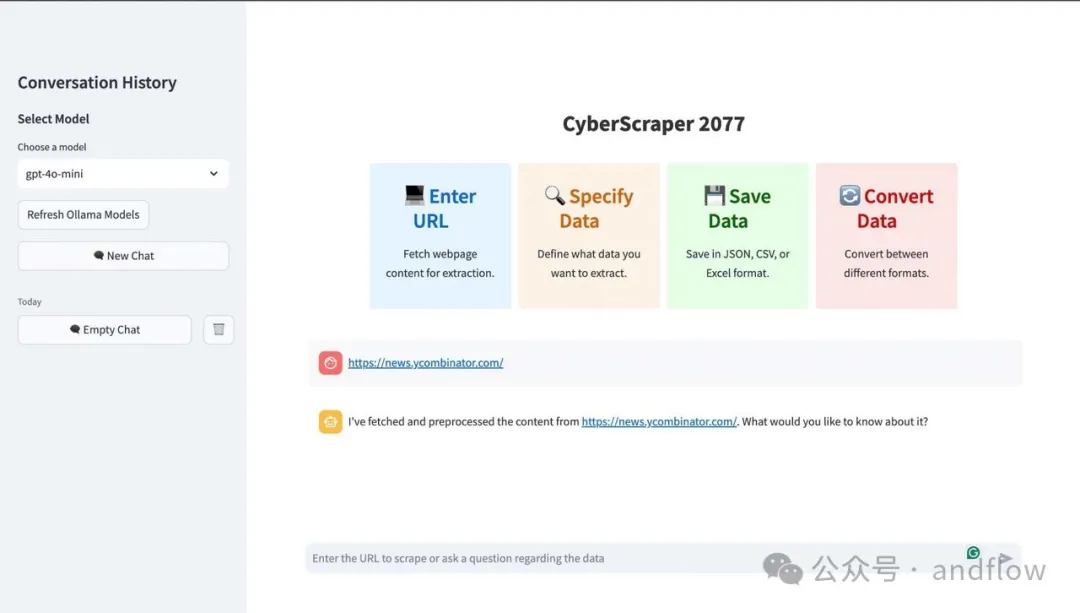
CyberScraper 2077是一款基于OpenAI、Gemini和或者本地大模型的Web爬取工具。它專為精確高效的數據提取而設計,適合數據分析師、技術愛好者和任何需要簡化在線信息訪問的人。
優勢特點:
- 基于人工智能的提取:利用人工智能模型來智能地理解和解析Web內容。
- 流暢的流線型界面:友好的用戶GUI。
- 多格式支持:以JSON、CSV、HTML、SQL或Excel格式導出數據。
- 隱身模式:實現了隱身模式參數,有助于避免被檢測為機器人。
- LLM支持:提供一個支持各種LLM的功能。
- 異步操作:異步操作以實現閃電般的快速操作。
- 智能解析:抓取內容,就好像它是直接從主自己的記憶中提取的一樣。
- 緩存:使用LRU緩存和自定義字典實現了基于內容和基于查詢的緩存,以減少冗余的API調用。
- 支持上傳到Google表格:可以輕松地將提取的CSV數據上傳到Google表格。
- 驗證碼繞過:可通過使用URL末尾的captcha來繞過驗證碼。(目前只能在本地工作,不能在Docker上工作)
- 當前瀏覽器:可以使用運行環境中的本地瀏覽器環境,幫助繞過99%的機器人檢測。
- 代理模式(即將推出):內置的代理支持,讓你繞過網絡限制。
- 瀏覽頁面:瀏覽網頁并從不同頁面抓取數據。


























