快速學會一個算法,卷積神經網絡!!!
作者:程序員小寒
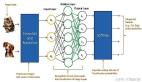
卷積神經網絡(CNN)是一類專門用于處理具有網格結構數據的深度學習模型,廣泛應用于圖像處理、計算機視覺等領域。
今天給大家分享一個強大的算法模型,卷積神經網絡。
卷積神經網絡(CNN)是一類專門用于處理具有網格結構數據(如圖像)的深度學習模型,廣泛應用于圖像處理、計算機視覺等領域。
CNN 通過模仿生物視覺系統的結構,通過層級化的卷積和池化操作,自動從輸入數據中提取特征并進行分類或回歸。CNN 的優勢在于其自動特征提取能力,不需要人工設計特征,非常適合處理圖像等高維數據。
 圖片
圖片
卷積神經網絡的基本結構
卷積神經網絡主要由卷積層、池化層和全連接層組成。
卷積層
卷積層是 CNN 的核心層,它的核心思想是通過卷積操作提取圖像的局部特征。
在卷積操作中,使用一組(多個)可訓練的卷積核(也稱為濾波器)在輸入圖像上滑動,并與圖像的局部區域進行卷積計算。
 圖片
圖片
每個卷積核提取圖像的某一特征(如邊緣、紋理、顏色等)。
卷積操作后的結果是一個特征圖(Feature Map),表示了該特征在圖像中的空間分布。
關鍵概念
- 卷積核(Filter/Kerner)
卷積核是一個小的矩陣,通常是 3x3 或 5x5。 - 卷積核數量
定義了卷積層的輸出特征圖的數量。每個卷積核產生一個特征圖,多個卷積核可以提取多種不同的特征。 - 步幅(Stride)
步幅是卷積核在輸入數據上滑動的步長。步幅決定了卷積操作的輸出尺寸。步幅越大,輸出特征圖越小。 - 填充(Padding)
為了保持輸入和輸出特征圖的尺寸一致,卷積操作通常會在輸入數據的邊緣添加額外的像素。這些額外的像素值通常設置為0。 - 卷積運算
卷積核與輸入數據的每個局部區域進行逐元素相乘并求和的操作。
例如,3x3的卷積核在圖像上滑動時,會與圖像的每個 3x3 區域進行卷積計算,生成對應位置的特征圖。
 圖片
圖片
池化層
池化層用于降低特征圖的空間尺寸,減少計算量和參數數量,同時保留重要的特征信息
常用的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化(Max Pooling),從特定區域中選取最大值。
 圖片
圖片
- 平均池化(Average Pooling),取特定區域的平均值。
 圖片
圖片
全連接層
在卷積層和池化層提取了局部特征后,CNN 通常會通過一個或多個全連接層將這些特征映射到最終的輸出。例如,圖像分類問題中,全連接層的輸出就是各個類別的預測值。
 圖片
圖片
CNN的優勢
- 局部感知和權重共享
卷積操作利用局部感知特性,能夠在圖像的不同區域提取相似的特征(如邊緣、角點等)。
卷積核在整個圖像上共享權重,從而減少了參數的數量,避免了全連接網絡中參數過多帶來的問題。 - 平移不變性
由于卷積操作具有平移不變性,CNN 能夠有效地識別圖像中的目標,無論它們的位置如何。 - 自動特征學習
CNN 能夠自動從原始數據中學習到特征,而無需人工設計特征。
通過卷積層、池化層和全連接層的逐層組合,網絡能夠從簡單到復雜地學習圖像的層次化特征。
案例分享
下面是一個使用卷積神經網絡(CNN)進行手寫數字識別的示例代碼。
首先,我們加載 MNIST 數據集。
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# 加載 MNIST 數據集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
# 重塑數據為 [batch_size, 28, 28, 1] 形式
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)接下來我們將創建一個簡單的 CNN 模型。
# 構建卷積神經網絡 (CNN) 模型
model = models.Sequential()
# 第一層卷積層,32個3x3的卷積核,激活函數ReLU
model.add(layers.Conv2D(32, (3, 3), activatinotallow='relu', input_shape=(28, 28, 1)))
# 池化層,2x2的最大池化
model.add(layers.MaxPooling2D((2, 2)))
# 第二層卷積層,64個3x3的卷積核
model.add(layers.Conv2D(64, (3, 3), activatinotallow='relu'))
# 池化層,2x2的最大池化
model.add(layers.MaxPooling2D((2, 2)))
# 展平層,將卷積層的輸出展平為一維
model.add(layers.Flatten())
# 全連接層,128個神經元
model.add(layers.Dense(128, activatinotallow='relu'))
# 輸出層,10個神經元,使用Softmax激活函數進行分類
model.add(layers.Dense(10, activatinotallow='softmax'))
model.summary()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])接下來,我們將使用訓練數據來訓練模型。
history = model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels))訓練完成后,我們可以使用測試集評估模型的性能。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"測試集準確率: {test_acc}")
predictions = model.predict(test_images)
# 打印預測結果和真實標簽
for i in range(5):
print(f"真實標簽: {test_labels[i]}")
print(f"預測標簽: {np.argmax(predictions[i])}")
plt.imshow(test_images[i].reshape(28, 28), cmap=plt.cm.binary)
plt.show() 圖片
圖片
責任編輯:武曉燕
來源:
程序員學長