













快速學會一個算法,Transformer
大家好,我是小寒
今天給大家分享一個強大的算法模型,Transformer
Transformer 是近年來在自然語言處理(NLP)領域取得顯著成果的一種深度學習模型,最初由 Vaswani et al. 在 2017 年提出。
與傳統的序列模型(如 RNN 和 LSTM)相比,Transformer 的主要優勢在于其能夠更好地處理長距離依賴關系,同時顯著提高了計算效率。
Transformer 架構
Transformer 模型的核心由編碼器(Encoder)和解碼器(Decoder)兩部分組成,每部分由多個相同的層(Layer)堆疊而成。
 圖片
圖片
編碼器
編碼器部分由六個相同的層(來自原始論文)堆疊而成,每層分為 2 個子層。
- 多頭自注意力機制
通過計算輸入序列中每個位置與其他位置之間的注意力權重,來捕捉序列中的長距離依賴關系。 - 前饋神經網絡
對每個位置的表示進行進一步的非線性變換。
每個子層后面都緊跟著一個殘差連接(Residual Connection)和層歸一化(Layer Normalization)。
 圖片
圖片
下面,我們來對編碼器的組件進行詳細的描述。
- 詞向量
原始形式的單詞對機器來說毫無意義。
詞向量是將離散的詞表示成連續的向量,以捕捉詞與詞之間的語義關系。
詞向量通過嵌入層(Embedding Layer)實現,將每個詞映射到一個高維的向量空間中。
這使得模型可以處理輸入序列中的詞,并在訓練過程中學習詞與詞之間的語義關系。
 圖片
圖片
- 位置編碼
由于 Transformer 不像 RNN 那樣具有順序信息,因此需要顯式地將位置信息加入到輸入中。
位置編碼通過將每個位置映射到一個向量,提供了詞在序列中的位置信息。
常見的方法是使用正弦和余弦函數來生成位置編碼。
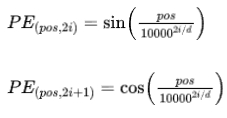
其中,pos 是位置,i 是維度索引,d 是嵌入維度。位置編碼將被添加到詞向量中,使得每個詞的表示包含了位置信息。
 圖片
圖片
- 自注意力
自注意力機制是 Transformer 的核心組件,它通過計算輸入序列中每個位置與其他位置之間的注意力權重,來捕捉序列中的長距離依賴關系。
具體步驟如下:
- 查詢(Query)、鍵(Key)、值(Value)向量通過線性變換得到查詢、鍵和值向量。
 圖片
圖片
- 注意力權重
通過查詢和鍵向量的點積計算注意力權重,然后應用 softmax 函數。
- 加權和
利用注意力權重對值向量進行加權求和。
- 殘差連接和層歸一化
殘差連接和層歸一化用于穩定訓練過程,并加速模型的收斂。
殘差連接將子層的輸入直接添加到輸出中,使得每一層都可以直接訪問輸入信號。
層歸一化則對每一層的輸出進行標準化,減少內部協變量偏移。 - 前饋層
前饋層是一個簡單的兩層全連接神經網絡,用于對每個位置的表示進行進一步的非線性變換。
它在每個位置上獨立操作,不共享參數。 - 輸出
編碼器的輸出是一個大小為 (N, T, d) 的張量,其中每個位置的向量表示是經過多層編碼器后的最終表示。
這些表示將被傳遞到解碼器或用于下游任務(如分類、翻譯等)。
解碼器
解碼器層除了包含與編碼器層相同的兩個子層外,還額外包含一個用于處理編碼器輸出與解碼器輸入之間關系的多頭注意力機制。
具體來說,解碼器層包括以下三個子層:
- Masked 多頭自注意力子層(Masked Multi-Head Self-Attention Sub-layer)
- 編碼器-解碼器注意力子層(Encoder-Decoder Multi-Head Attention Sub-layer)
- 前饋神經網絡
同樣,每個子層后面都有殘差連接和層歸一化。
 圖片
圖片
- Masked 多頭自注意力子層
在標準的多頭注意力機制中,每個位置的查詢(Query)會與所有位置的鍵(Key)進行點積計算,得到注意力分數,然后與值(Value)加權求和,生成最終的輸出。
然而,在解碼器中,生成序列時不能訪問未來的信息。因此需要使用掩碼(Mask)機制來屏蔽掉未來位置的信息,防止信息泄露。
具體來說,在計算注意力得分時,對未來的位置進行屏蔽,將這些位置的得分設為負無窮大,使得 Softmax 歸一化后的權重為零。
 圖片
圖片
- 編碼器-解碼器注意力子層
編碼器-解碼器多頭注意力子層在 Transformer 解碼器中起到了關鍵作用,它使解碼器能夠有效地關注輸入序列(編碼器的輸出),從而在生成序列時參考原始輸入信息。
具體來說,編碼器-解碼器多頭注意力的基本思想是通過對編碼器輸出(Key 和 Value)和解碼器當前輸入(Query)來生成新的表示。
這種機制使得解碼器能夠在生成序列時動態地選擇性關注輸入序列的不同部分。
 圖片
圖片
- 前饋神經網絡子層
這是一個完全連接的前饋神經網絡,通常由兩個線性變換和一個ReLU激活函數組成。
它在每個位置上獨立地應用相同的網絡,處理每個位置的表示。




























