













AAAI 2025 | 合成數據助力自駕點云異常檢測新SOTA
論文信息
- 論文題目:LiON: Learning Point-wise Abstaining Penalty for LiDAR Outlier DetectioN Using Diverse Synthetic Data
- 論文發表單位:清華大學, 廈門大學,滴滴出行, 香港中文大學-深圳
- 論文地址:https://arxiv.org/abs/2309.10230
- 項目倉庫:https://github.com/Daniellli/LiON

1.Motivation
基于點云的語義場景理解是自動駕駛汽車感知技術棧中的重要模塊。然而,由于點云不像圖像那樣具有豐富的語義信息,在點云中這個識別異常點是一項極具挑戰性的任務。本工作從兩個方面緩解了點云缺乏語義信息對異常點感知的影響:1) 提出了一種新的學習范式,使模型能夠學習更魯棒的點云表征,增強點與點之間的辨別性;2) 借助額外的數據源,ShapeNet,提出了一套可以生成多樣且真實偽異常的方法。實驗結果表明,在公開數據集 SemanticKITTI 和 NuScenes 上,本方法顯著超越了前 SOTA。
2.Method
給定一個場景點云,點云語義分割的主要任務是為點云中的每個樣本點分配一個預先定義的類別,例如車、樹、行人等。本工作將這些屬于預先定義類別的樣本點稱為正常樣本點。而 點云異常檢測則作為點云語義分割模塊的補充,用于識別那些不屬于預先定義類別集合的樣本點,例如桌子、椅子等無法預料的類別。本工作將這些樣本點稱為異常樣本點。
此前的工作 REAL 將圖像異常檢測方法直接適配到點云異常檢測領域,并通過實驗發現,大量異常樣本被錯誤分類為預先定義的類別。為了解決這一問題,REAL 提出了一種新的校正損失,用于校正正常樣本的預測。然而,本工作的實驗結果表明,盡管該校正損失能夠提升異常樣本的分類性能,但同時也對正常樣本的分類性能造成了顯著的負面影響。
本工作將圖像異常檢測方法在點云異常檢測領域表現不佳的原因歸結于點云不像圖像那樣具有豐富的語義信息。比如Figure 1左側,即使是人類也難以識別道路中央的家具信息。因此,該工作從兩個方面緩解點云缺乏豐富語義含義所帶來的影響。

Figure 1 點云語義分割模塊錯誤地將家具分類成道路
首先,該工作提出為每個樣本點計算一個懲罰項,并通過額外的損失函數保證正常樣本點的懲罰較小,而異常樣本點的懲罰較大。然后,將該懲罰項嵌入交叉熵損失中,以動態調整模型的優化方向。通過為每個樣本點學習額外的懲罰項并改進學習范式,本工作增強了樣本點之間的辨別性,緩解了點云缺乏語義信息的問題,從而全面提升了異常檢測能力。
此外,該工作提出利用 ShapeNet 數據集生成偽異常。ShapeNet 是一個大規模的三維形狀數據集,包含超過 22 萬個三維模型,覆蓋 55 個主要類別和 200 多個子類別。因此,通過 ShapeNet 生成的偽異常具有較高的多樣性。其次,在生成偽異常時,該工作進一步考慮了點云的采樣模式,從而使生成的偽異常更加真實。因此,該工作通過生成更加多樣且真實的偽異常,更好地估計和模擬了真實異常的分布,緩解了點云缺乏語義信息的問題。
2.1. 模型整體架構
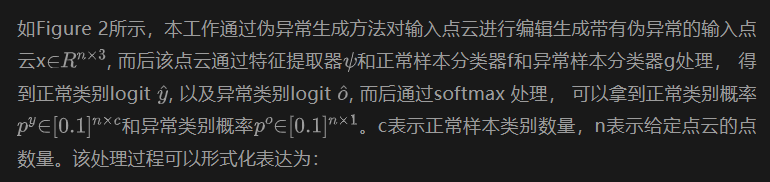

其中[·]表示拼接操作。
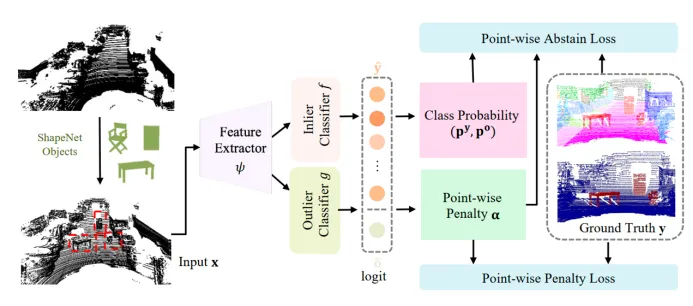
Figure 2 算法處理流程
2.2. 基于逐點懲罰的學習范式
本工作提出對每個樣本點用能量函數計算一個額外的懲罰項a,懲罰項的計算如下所示:

此外,該工作通過一個額外的逐點懲罰損失函數使得對于所有的正常樣本點都有個較小的懲罰,對于所有的異常樣本點都有較大的懲罰。該逐點懲罰損失函數的形式化表達如下:



Figure 3 懲罰項和逐點懲罰損失之間關系
而后,該工作用懲罰項a升級交叉熵損失函數,動態調整交叉熵損失的優化重點, 升級后的交叉熵損失函數被叫做逐點拒絕(abstain)損失函數:


因此整個算法的損失函數為:


2.3.合成數據生成點云異常
該工作通過引入額外的數據源, ShapeNet,來生成更加多樣且真實的偽異常,從而更好地近似真實異常分布。首先,通過伯努利分布計算插入的偽異常數量G。而后,通過循環G次下面流程來插入偽異常。
如Figure 4所示,該生成方法包括以下步驟:(a)加載物體后,基于均勻分布計算平移距離和旋轉角度,并對物體進行(b)平移和(c)旋轉,使其有可能放置在場景中的任意角落;(d)基于均勻分布計算的縮放系數,對物體進行縮放;(e) 將物體放置于場景地面; (f)使用被插入物體遮擋住的場景樣本點來替換插入物體的樣本點。

Figure 4 偽異常生成流程
3.Experiment
實驗結果表明,該工作提出的方法在SemanticKITTI和NuScenes兩個公開數據集上能夠大幅優于之前的SOTA方法。
3.1.實驗基準
該工作沿用了之前的實驗基準。采用SemanticKITTI和NuScenes作為基準數據集。在SemanticKITTI中,將{other-vehicle}設為異常類別;在NuScenes中,將{barrier,constructive-vehicle,traffic-cone,trailer}設為異常類別。這些異常類別的樣本在訓練過程是不可見的。

3.2.定量結果

Table 1 定量結果對比
該工作沿用之前的實驗設置, 選C3D(Cylinder3D)作為分割基座模型。前SOTA方法, APF,沒有在NuScenes上開展實驗并且沒有開源代碼, 因此該工作無法在NuScenes上與其進行對比。Table 1實驗結果表明,該工作提出的算法在兩個公開基準數據集上大幅優于之前SOTA方法。
3.3.定性結果
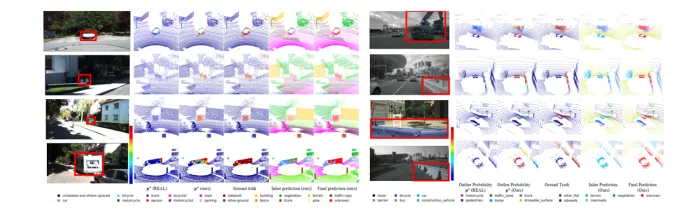
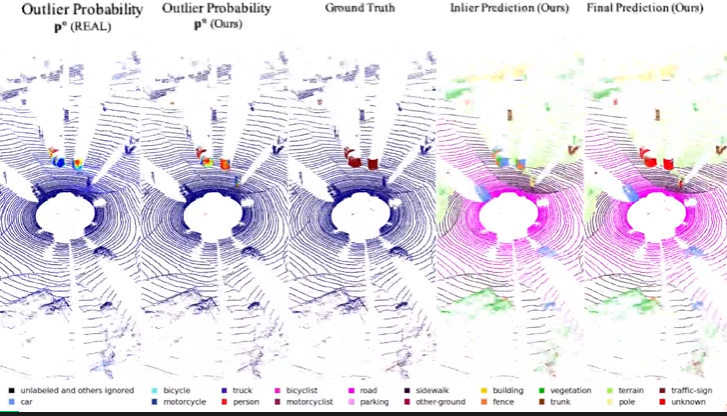
Figure 5 SemanticKITTI(左)和NuScenes(右)上的定性結果對比
與前SOTA算法對比,該工作提出的算法不管是在64線雷達采集的點云數據上(SemanticKITTI)還是32線雷達采集的點云數據(NuScenes)上都表現出了優越的性能, 不僅能夠精確定位異常類別而且能夠賦予較高的置信度。


























