0 Token 間間隔 100% GPU 利用率,百度百舸 AIAK 大模型推理引擎極限優化 TPS
1. 什么是大模型推理引擎
大模型推理引擎是生成式語言模型運轉的發動機,是接受客戶輸入 prompt 和生成返回 response 的樞紐,也是拉起異構硬件,將物理電能轉換為人類知識的變形金剛。
大模型推理引擎的基本工作模式可以概括為,接收包括輸入 prompt 和采樣參數的并發請求,分詞并且組裝成 batch 輸入給引擎,調度 GPU 執行前向推理,處理計算結果并轉為詞元返回給用戶。
- 和人類大腦處理語言的機制類似,大模型首先會把輸入的 prompt 進行統一理解,形成具有記憶能力的上下文。這個階段通常稱為 Prefill 階段。
- 在結束 Prefill 階段之后,大模型引擎會根據生成的上下文不停地推斷下一個可能出現的詞語,如此往復循環,直到遇到停止符或者滿足采樣參數中的停止條件。這是一個自回歸過程,通常稱為 Decoder 階段。
由于 Prefill 階段和 Decoder 階段所完成的任務不同,通常來講,會從用戶視角出發使用 SLO(Service Level Object): TTFT(Time To First Token)和TPOT(Time Per Output Token)去評測引擎。
- TTFT 就是首 token 延遲,用于衡量 Prefill 階段的性能。也就是用戶發出請求之后,收到第一個詞元返回的間隔,也就是系統的反應時間。對于客戶來說,這個指標越低越好。
- TPOT 就是出字間隔,用于衡量 Decoder 階段的性能。也就是每生成兩個詞元之間的間隔。通常需要比人眼閱讀文字的速度要快,這個指標同樣也是越低越好。
當然,只用這些 SLO 并不能完全評測推理引擎對資源的使用狀態,所以,和其他使用異構資源的系統一樣,會使用吞吐來評測引擎對資源的使用效率,常用的指標就是極限出字率。
極限出字率 TPS(Tokens Per Second )就是系統在滿載的情況下,使用所有可用的資源在 1s 內可以生成的詞元的最大數量。這個指標越高,代表硬件的效率越高,可以支持的用戶規模就越多。
目前市面上流行的推理引擎有很多,比如說 vLLM、SGLang、LMDeploy、TRT-LLM 等。其中 vLLM 是業界第一個完美解決了大模型不定長特性來各種問題的推理引擎,也是市面上使用最多,社區最活躍的推理引擎。
vLLM 的原創性高效顯存管理、高吞吐、極易用、易拓展、模式眾多、新特性支持快,社區活躍等特性是其受歡迎的原因。但是,vLLM 對復雜調度邏輯的處理沒有做到極致,引入了大量的 CPU 操作,拉長了 TPOT。TPOT 的拉長會降低用戶體驗,降低了出字率,造成了 GPU 資源浪費。
2. 影響 TPOT 的罪魁禍首 —— Token 間間隔
區別于小模型推理以 batch 為最小推理單位,大模型推理的最小單位是 step。這也是由大模型推理中自回歸的特點所決定的。
每一次 step 會給 batch 內部的每個請求生成一個詞元,如果有請求生成了結束符,那么這個請求將會提前結束,并且從下個 step 的 batch 中剔除,空余出來的資源將會被引擎動態的分配給其余正在排隊的請求。用戶可以感知到的觀測指標 TPOT,就是每次 step 的執行時間。
每個 step 的執行邏輯可以簡單的概括為一下兩部分:前向推理和 Token 間間隔。
- 前向推理是調用 GPU 計算資源對 Transfomer 結構進行運算的過程,是一個典型的 GPU 密集計算型任務。
- Token 間間隔,則負責做詞元拼接、結束檢測、用戶響應、請求調度、輸入準備等工作,是典型的 CPU 邏輯密集型任務。
優化推理引擎的終極目標其實就是,極限提升前向推理的吞吐,同時極限壓縮 Token 間間隔,最終提高極限出字率。
然而,vLLM 的實現中,這兩者天然存在著矛盾。極限提升前向推理的吞吐,(即充分發揮 GPU 算力)要求在適當范圍內盡可能增加 batch 內的請求數。然而更多的請求數卻拉長了 Token 間間隔,這樣不僅會使 TPOT 拉長,還會導致 GPU 斷流,出現空閑。在最差的情況下(比如 batch 為 256),Token 間間隔和前向推理時間幾乎相同,GPU 的利用率只有 50%-60%。
為了提升極限出字率,同時確保高 GPU 利用率,優化 Token 間間隔成為了提升推理速度的關鍵。
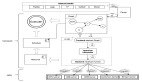
3. 百度百舸 AIAK 優化 Token 間間隔的方案
百度百舸的 AI 加速套件 AIAK 基于 vLLM ,在優化 TPOT 持續發力,并且始終保持著對社區在同周期的技術領先。
3.1. 解決方案 1:多進程架構
這個方案的目標是盡可能縮短 Token 間間隔,將 detokenizer 所耗費的時間從 TPOT 中拿去。
我們發現在處理輸入請求和生成返回的過程中,tokenize/detokenize 過程(token id 和字符串的轉換)是完全可以獨立于 GPU 推理運算的邏輯操作。
所以,我們借助 NVIDIA Triton 框架,將 tokenize/detokenize 的過程從推理流程中抽象出來作為單獨的 Triton 模型部署,借助 Triton 的 ensemble 機制,把串行過程轉變為 3 階段( 3 進程)流水,實現了 tokenize/detokenize 和 GPU 推理 overlap,有效縮短了 Token 間隔時間。盡管這個優化只把 Token 間間隔中一部分 CPU 操作消除了,但是依然有將近 10% 的收益。
 圖片
圖片
3.2. 解決方案 2:靜態 Slot 方案
這個方案主要改造了 vLLM 的調度邏輯,全方位優化了詞元拼接、結束檢測、用戶響應、請求調度、輸入準備,提高了各個模塊的并行效率,實現了對上一個方案中的「剩余部分」耗時的壓縮。
我們發現 vLLM 的調度邏輯是面向全局視角的。也就是說每個 step 的調度都會從全局中進行重新篩選,相當于當前 step 結束之后,調度器會把當前 batch 中的句子「放回」全局請求池子中,然后在下一個 step 開始前,從這個全局池子中「取回」適當請求進行運算,這一放一取引入了額外的 overhead。
為了實現全局調度,vLLM 在詞元拼接等其他環節引入了大量的 for 循環去串行的處理每個請求,由于這些操作都在發生在 CPU 上,導致在輸入打包過程中,必須要引入耗時較長的 host to device 操作。
事實上,step 之間的很多信息是可以復用的(每次放回去的請求和取回來的請求很大一部分是重復的)。也正是基于這個洞見,百度百舸的 AIAK 把 GPU 每次可以迭代的 batch 當成一批固定的 slot,一旦某個請求被調度到某個 slot 后,在完成請求所有推理迭代之前,都不會被喚出,也正是有了這些固定 slot 抽象,AIAK 實現了:
- 將全局調度改造為局部調度。也就是在下一個 step 調度時,最大程度復用上一個 step 的信息,避免全局搜索,只做增量調度。
- 串行轉并行。也正是有了 slot 的引入,詞元拼接、結束檢測等這些原本串行的操作可以用 CUDA Kernel 做并發處理,耗時從 ms 級別降低到 us 級別。
- 避開 host to device 操作。輸入打包的工作得以復用前序的顯存,有效避開了 host to device 操作。
 圖片
圖片
3.3. 方案 3:異步化執行
多進程架構將邏輯上容易獨立的部分解耦到其他進程做流水并行,靜態 Slot 方案則直面 token 間耗時問題,優化調度模式壓榨各個環節的耗時。有了這兩個方案,Token 間間隔已經從 35ms 降低到 14ms,GPU 的利用率已經從 50% 提升到了 75%,但是距離 100% 的 GPU 利用率和零耗時 Token 間間隔的目標還有不少距離。
百度百舸 AIAK 通過異步調度模式,將前一個方案中的「剩余部分」全部取出,最終實現了上述極限目標。
簡單來講,就是將 CPU 操作密集的 Token 間間隔和 GPU 計算密集的前向推理完全分開到兩條流水線上做二級流水并行。
- 從邏輯上來講,核心調度邏輯擺脫了對前向推理的同步依賴,實現異步化調度。
- 從效果上來說,GPU 避免 token 間同步導致的斷流問題,處于一直繁忙狀態,實現了推理過程中 100% 利用率和 0 Token 間間隔。
為了簡化實現,我們將操作相對簡單的前向推理當做一個任務放在后臺線程中進行運行,主線程則運行核心的復雜的調度邏輯。兩個線程通過一個隊列進行交互,分別沖當生產者和消費者,通過線程信號量和 GPU 流上的事件進行信號同步,實現二級流互相 overlap。
 圖片
圖片
和其他任何使用 GPU 類似的硬件作為加速器的系統一樣,追求 100% 的利用率一直是所有工程師的終極目標。百度百舸的 AI 加速套件 AIAK 在優化 TPOT,同時打滿 GPU 利用率這一目標上經歷漫長而又艱辛的探索,最終才徹底實現了 0 Token 間間隔和 100% 利用率這一目標。
當然,除去在這個過程中使用的諸多巧妙的優化手段外,百度百舸的 AIAK 還在量化、投機式、服務化、分離式、多芯適配等領域做了大量工作,致力于實現一個適用于全場景、多芯片、高性能的推理引擎,助力用戶在「降低推理成本,優化用戶體驗上」更上一層樓。