面試官:水平分表如何選擇 sharding key?分表和分區(qū)有什么區(qū)別?從 Innodb 底層存儲說明為什么需要做垂直分表?
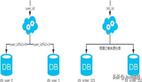
面試官:什么情況下選擇分庫?什么情況下選擇分表?
分庫和分表是數(shù)據(jù)庫層面的兩種常見解決方案,它們分別解決不同的問題。

1. 分庫解決的問題
分庫主要是為了解決高并發(fā)的問題。在數(shù)據(jù)庫系統(tǒng)中,當(dāng)對數(shù)據(jù)庫的訪問量(QPS,Queries Per Second)非常高時,會對數(shù)據(jù)庫實(shí)例造成很大的壓力,降低數(shù)據(jù)查詢效率,甚至導(dǎo)致連接失敗。這是因?yàn)槊總€數(shù)據(jù)庫實(shí)例都有連接數(shù)的限制,當(dāng)訪問連接數(shù)過多時,就會超出這個限制。
此時,將一個數(shù)據(jù)庫實(shí)例的操作拆分成對多個數(shù)據(jù)庫實(shí)例的操作,即進(jìn)行分庫,可以有效地降低單個數(shù)據(jù)庫實(shí)例的壓力,提高系統(tǒng)的并發(fā)處理能力。此外,分庫還可以實(shí)現(xiàn)業(yè)務(wù)數(shù)據(jù)的隔離,便于管理和維護(hù)。
2. 分表解決的問題
(水平)分表主要是為了解決數(shù)據(jù)量大的問題。當(dāng)一張表中的數(shù)據(jù)量過大時,對該表的讀寫操作都會變得效率低下。這是因?yàn)閿?shù)據(jù)庫需要遍歷的記錄過多導(dǎo)致可能得IO次數(shù)增多,如果表中的記錄數(shù)目過多,這個過程將會非常耗時。
通過分表,可以將數(shù)據(jù)分散到多個表中,每個表的數(shù)據(jù)量都相對較小,這樣在執(zhí)行查詢操作時,數(shù)據(jù)庫只需要在相對較小的表中查找數(shù)據(jù),從而大大提高查詢效率。此外,分表還可以避免單表數(shù)據(jù)過大引發(fā)的一系列問題,如備份和恢復(fù)的速度慢等。
現(xiàn)實(shí)情況中能不水平分表就盡量不要水平分表,而是在經(jīng)過增加索引,讀寫分離后仍無法解決查詢慢的情況下才進(jìn)行分表。原因主要基于以下幾點(diǎn)考慮:
- 復(fù)雜性增加:水平分表將原始表的數(shù)據(jù)按某種策略(如哈希、范圍等)拆分成多個子表,每個子表包含原始表的一部分?jǐn)?shù)據(jù)。這增加了系統(tǒng)的復(fù)雜性,因?yàn)樾枰芾矶鄠€表,并且在查詢、更新和刪除數(shù)據(jù)時需要考慮數(shù)據(jù)分布和路由。
- 數(shù)據(jù)一致性難以保證:在水平分表的情況下,某些操作(如跨分表事務(wù))可能難以保證數(shù)據(jù)的一致性。分布式事務(wù)問題是一個挑戰(zhàn),因?yàn)楫?dāng)使用分片技術(shù)進(jìn)行水平分表時,可能會涉及到多個數(shù)據(jù)庫節(jié)點(diǎn)的事務(wù)處理。這增加了系統(tǒng)的復(fù)雜性和開發(fā)成本,同時也可能影響數(shù)據(jù)的可靠性和完整性。
- 維護(hù)和遷移成本:水平分表后,數(shù)據(jù)的維護(hù)和遷移成本也會增加。例如,當(dāng)需要添加新的字段或修改現(xiàn)有字段時,需要在所有相關(guān)的子表上執(zhí)行相應(yīng)的操作。此外,如果需要進(jìn)行數(shù)據(jù)遷移或備份,也需要考慮如何高效地處理多個分片的數(shù)據(jù)。
面試官:水平分表該如何選擇sharding key,應(yīng)該遵循哪些原則?
Sharding Key(分片鍵)是用于將數(shù)據(jù)進(jìn)行分片的屬性或字段。選擇Sharding Key 最重要的原則是:我們的業(yè)務(wù)最頻繁的使用哪個字段訪問數(shù)據(jù)的。
以電商系統(tǒng)的訂單表分片為例。假設(shè)把 OrderlD 作為 Sharding Key行不行?
在電商系統(tǒng)中,買家和商家都有查看訂單列表的需求,但最能為電商帶來利益的是買家用戶,而買家用戶對于訂單最高頻的訪問是 app 中"我的訂單"頁面,此時的查詢條件是用戶ID。但是如果我們的分片依據(jù)是 OrderID,強(qiáng)行查詢的只能查詢所有的分片,并合并查詢結(jié)果,效率很低,且沒法分頁。
而如果把 UserID 作為Sharding Key,此時用戶在app中"我的訂單"頁面正好可以使用到分片鍵,一個用戶對應(yīng)的訂單信息都在一個分片中,因?yàn)榉制鞘褂玫腢serID,此時效率最高。直接去對應(yīng)的分片去查詢就可以了。
問題來了,有使用OrderlD進(jìn)行查詢的場景怎么辦,怎么通過OrderID找到對應(yīng)的數(shù)據(jù)分片?
管理員或者商家可能不使用UserID而只使用OrderID作為查詢條件查看單條訂單。為了保證用戶在主場景下的查詢效率,還是以UserID作為分片鍵。但是在生成訂單ID的時候,可以將用戶ID的后幾位作為訂單ID的一部分。比如18位的訂單號,它的第15-18位是用戶ID的后四位。此時按照訂單ID查詢的時候,可以根據(jù)訂單ID中的用戶ID找到分片。
假設(shè)我們已經(jīng)確定了把 UserID 作為Sharding Key ,那么商家想查詢自己的訂單列表怎么辦?
一般的方案是把訂單數(shù)據(jù)同步到其他的存儲中間件中,用其他存儲中間件解決復(fù)雜查詢的問題。例如可以構(gòu)建一套以商家ID作為Sharding Key的只讀訂單庫,專門供商家使用。或者可以將數(shù)據(jù)同步到HDFS中,用一些大數(shù)據(jù)技術(shù)生成對應(yīng)的訂單報(bào)表。
一個選擇分片鍵的一些通用依據(jù)如下所示:
(1) 數(shù)據(jù)分布均勻性:
- 分片鍵的數(shù)據(jù)基數(shù)要足夠大,也就是分片鍵的value盡可能不同,以確保數(shù)據(jù)能夠均勻分布到各個分片節(jié)點(diǎn)上,避免數(shù)據(jù)傾斜。
- 增長趨勢可預(yù)測,便于進(jìn)行容量規(guī)劃和分片管理。
- 避免選擇可能導(dǎo)致熱點(diǎn)數(shù)據(jù)的字段,如使用時間戳作為分片鍵時,需要注意追加寫入可能導(dǎo)致特定分片成為熱點(diǎn)。
(2) 查詢模式適配性:
- 與業(yè)務(wù)最頻繁的查詢模式匹配,以便在查詢時能夠高效地定位到數(shù)據(jù)所在的分片節(jié)點(diǎn)。
- 支持就近路由,即查詢時能夠直接定位到包含所需數(shù)據(jù)的分片節(jié)點(diǎn),提升查詢效率。
(3) 字段的更新頻率:
選擇低更新頻率的字段作為Sharding Key,以減少數(shù)據(jù)遷移和重新分片的頻率。
面試官:Mysql的水平分表和分區(qū)有什么區(qū)別,什么時候用水平分表什么時候用分區(qū)?介紹一下Mysql中常見的分區(qū)算法?
1. 水平分表(Sharding)
原理:水平分表是將一個大型表的數(shù)據(jù)按某種規(guī)則拆分到多個獨(dú)立的表中。這些表通常具有相同的結(jié)構(gòu),但存儲不同的數(shù)據(jù)。
應(yīng)用場景:水平分表適用于數(shù)據(jù)量特別大、需要分布式存儲和高并發(fā)訪問的場景,如大型電商平臺、社交網(wǎng)絡(luò)等。同時分表可以分散到不同的數(shù)據(jù)庫實(shí)例,當(dāng)單個數(shù)據(jù)庫實(shí)例無法承載所有數(shù)據(jù)或處理所有請求時,水平分表成為了一種有效的解決方案。
優(yōu)點(diǎn):
- 可以突破單節(jié)點(diǎn)數(shù)據(jù)庫服務(wù)器的I/O能力限制,提高系統(tǒng)的可擴(kuò)展性。
- 可以將數(shù)據(jù)分散到多個存儲單元中,以減輕單表的數(shù)據(jù)量和訪問壓力,從而提高數(shù)據(jù)庫的性能。
缺點(diǎn):
- 實(shí)現(xiàn)和維護(hù)相對復(fù)雜,需要手動管理各個分表,包括表的創(chuàng)建、數(shù)據(jù)遷移和備份恢復(fù)等操作。
- 跨表查詢需要應(yīng)用程序處理或使用中間件支持,增加了開發(fā)難度和成本。
2. 分區(qū)(Partitioning)
原理:分區(qū)是將一個表的數(shù)據(jù)按某種規(guī)則劃從邏輯上分成多個分區(qū),每個分區(qū)存儲一部分?jǐn)?shù)據(jù)。但這些分區(qū)仍然屬于同一個表和同一個數(shù)據(jù)庫實(shí)例。
應(yīng)用場景:分區(qū)適用于中等規(guī)模的數(shù)據(jù)優(yōu)化,通過分區(qū),可以優(yōu)化查詢性能和管理效率。
優(yōu)點(diǎn):
- 數(shù)據(jù)庫系統(tǒng)自動管理分區(qū),支持自動分區(qū)裁剪和優(yōu)化,提高了查詢性能。
- 管理和維護(hù)相對簡單,減少了開發(fā)和運(yùn)維成本。
缺點(diǎn):擴(kuò)展性相對較弱,受限于單個數(shù)據(jù)庫實(shí)例的資源。
當(dāng)需要增加新的分區(qū)或調(diào)整分區(qū)范圍時,可能需要重新定義分區(qū)規(guī)則并遷移數(shù)據(jù),增加了系統(tǒng)停機(jī)時間和數(shù)據(jù)不一致性風(fēng)險(xiǎn)。
3. 分區(qū)和分表對比
對比指標(biāo) | 分區(qū) | 分表 |
查詢性能 | 可以通過只掃描相關(guān)分區(qū)來提高查詢效率,減少I/O操作量。 | 查詢性能通常優(yōu)于分區(qū),因?yàn)槊總€小表都是獨(dú)立的,可以充分利用數(shù)據(jù)庫索引和緩存機(jī)制。 |
數(shù)據(jù)管理 | 便于進(jìn)行局部備份、恢復(fù)和數(shù)據(jù)清理操作,但整體表結(jié)構(gòu)仍然保持一致。 | 數(shù)據(jù)管理相對復(fù)雜,需要對多個表進(jìn)行協(xié)調(diào)操作。 |
并發(fā)性能 | 可以提高并發(fā)性能,因?yàn)椴煌謪^(qū)可以獨(dú)立操作,減少鎖沖突。 | 并發(fā)性能通常優(yōu)于分區(qū),因?yàn)槊總€小表都是獨(dú)立的,可以充分利用數(shù)據(jù)庫并發(fā)處理能力。 |
擴(kuò)展性 | 擴(kuò)展性有限,因?yàn)榉謪^(qū)仍然屬于同一個表,受到數(shù)據(jù)庫表大小等限制。 | 擴(kuò)展性較好,可以通過增加小表數(shù)量來實(shí)現(xiàn)水平擴(kuò)展。 |
維護(hù)成本 | 維護(hù)成本相對較低,因?yàn)楸斫Y(jié)構(gòu)仍然保持一致,只需關(guān)注分區(qū)策略的優(yōu)化。 | 維護(hù)成本較高,需要對多個表進(jìn)行協(xié)調(diào)操作和維護(hù)。 |
適用場景 | 適用于數(shù)據(jù)量大但查詢條件較為集中的場景,如按時間范圍查詢的日志表。 | 適用于數(shù)據(jù)量大且查詢條件較為分散的場景,如用戶信息表、訂單表等。 |
以下是MySQL中常見的分區(qū)算法及其使用場景:
(1) Range分區(qū)(范圍分區(qū))
定義:基于屬于一個給定連續(xù)區(qū)間的列值,把多行分配給分區(qū)。
使用場景:適用于那些可以基于某個范圍進(jìn)行劃分的數(shù)據(jù)。例如,可以按年份、月份或日期范圍對表進(jìn)行分區(qū),以便查詢特定時間段內(nèi)的數(shù)據(jù)時,能夠只掃描包含所需數(shù)據(jù)的分區(qū),從而提高查詢效率。
示例:
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT,
order_date DATE,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY (id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p0 VALUES LESS THAN (2010),
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN (2025)
);(2) List分區(qū)(列表分區(qū))
定義:基于預(yù)定義的值列表進(jìn)行劃分。
使用場景:適用于那些值具有離散特性的列。例如,當(dāng)某個字段的值只有有限的幾個選項(xiàng)時,可以使用List分區(qū)。
示例:
CREATE TABLE employees (
id INT NOT NULL,
department_id INT NOT NULL,
name VARCHAR(50)
)
PARTITION BY LIST (department_id) (
PARTITION p_hr VALUES IN (1, 2),
PARTITION p_finance VALUES IN (3, 4),
PARTITION p_it VALUES IN (5, 6)
);(3) Hash分區(qū)(哈希分區(qū))
定義:使用哈希函數(shù)對列值進(jìn)行計(jì)算,然后根據(jù)結(jié)果分配到不同的分區(qū)。
使用場景:適用于數(shù)據(jù)分布較為均勻的場景。通過哈希分區(qū),可以將數(shù)據(jù)均勻地分布到不同的分區(qū)中,從而提高查詢性能。
示例:
CREATE TABLE users (
id INT NOT NULL,
email VARCHAR(100) NOT NULL,
signup_date DATE NOT NULL
)
PARTITION BY HASH(id)
PARTITIONS 4;4. 選擇分區(qū)算法的建議
- Range分區(qū):當(dāng)需要基于某個范圍進(jìn)行劃分時,如按年份、月份等,可以選擇Range分區(qū)。
- List分區(qū):當(dāng)某個字段的值只有有限的幾個選項(xiàng)時,可以選擇List分區(qū)。
- Hash分區(qū):當(dāng)數(shù)據(jù)分布較為均勻,且希望將數(shù)據(jù)均勻地分布到不同的分區(qū)中時,可以選擇Hash分區(qū)。
面試官:能不能說說看什么是垂直分表以及垂直分表的場景?從Innodb底層存儲說明為什么需要做垂直分表?
1. 定義
垂直分表是將一個寬表(即包含多個字段的表)按照字段進(jìn)行拆分,形成多個子表,每個子表僅包含原表中的部分字段。這些子表通過主鍵或唯一索引進(jìn)行關(guān)聯(lián),以保持?jǐn)?shù)據(jù)的完整性。
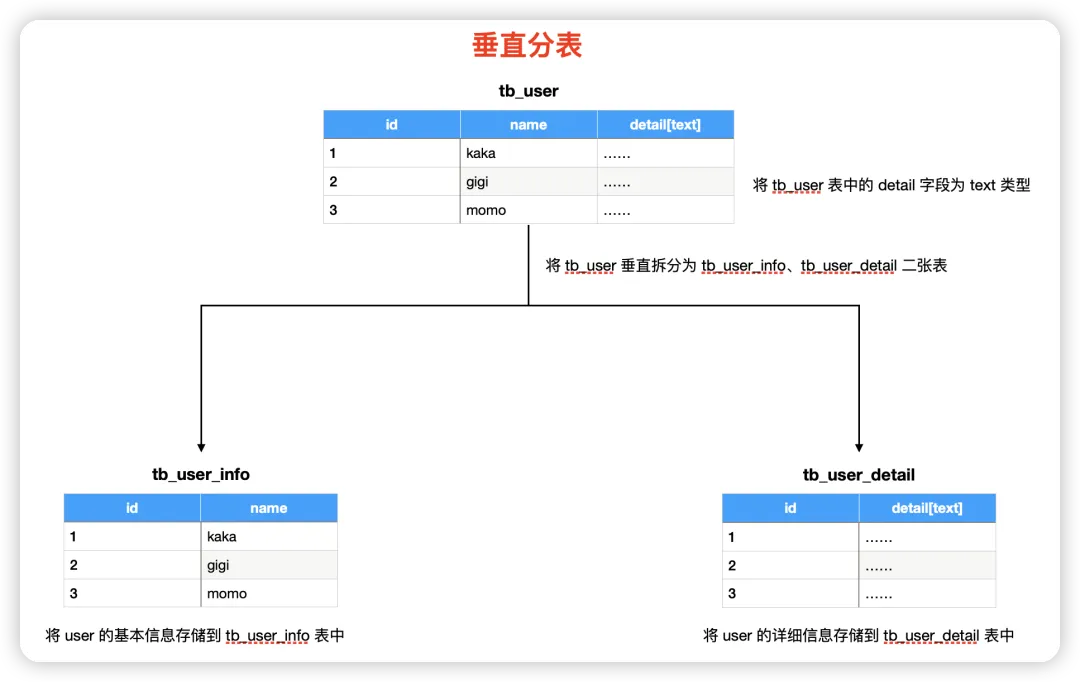
2. 原理及作用
優(yōu)化查詢性能:通過拆分表中的字段,可以減少單個表的寬度,從而提高查詢效率。尤其是當(dāng)查詢只涉及部分字段時,可以避免加載不必要的字段,減少I/O開銷。
分離冷熱數(shù)據(jù):將使用頻率較高的熱數(shù)據(jù)與使用頻率較低的冷數(shù)據(jù)分離到不同的表中,可以優(yōu)化數(shù)據(jù)庫性能,減少對冷數(shù)據(jù)的訪問開銷。
提高緩存命中率:表寬度減小后,緩存的效果會更好,因?yàn)榫彺嫱ǔV荒艽鎯τ邢迶?shù)量的數(shù)據(jù)行或數(shù)據(jù)頁。當(dāng)表寬度較小時,更多的數(shù)據(jù)行或數(shù)據(jù)頁可以被緩存,從而提高緩存命中率。
3. 適用場景
垂直分表通常適用于以下幾種場景:
- 寬表拆分:當(dāng)一個表中包含了大量的字段,且部分字段的使用頻率較低時,可以通過垂直分表將常用字段和不常用字段分開。
- 冷熱數(shù)據(jù)分離:在大數(shù)據(jù)應(yīng)用中,部分?jǐn)?shù)據(jù)的訪問頻率很高(熱數(shù)據(jù)),而部分?jǐn)?shù)據(jù)的訪問頻率很低(冷數(shù)據(jù))。通過垂直分表可以將冷熱數(shù)據(jù)分開,以優(yōu)化數(shù)據(jù)庫性能。
- 功能模塊獨(dú)立:如果某些功能模塊只需要訪問表中的部分字段,那么可以將這些字段獨(dú)立出來,以減少查詢時的I/O負(fù)擔(dān)。
- 大字段處理:表中包含大字段(如BLOB、TEXT等)時,這些字段會占用大量存儲空間和I/O資源。通過垂直分表,可以將這些大字段獨(dú)立存儲,以減少對其他查詢的影響。
從InnoDB存儲結(jié)構(gòu)的角度來看,實(shí)現(xiàn)垂直分表的原因主要基于以下幾點(diǎn):
4. InnoDB存儲結(jié)構(gòu)概述
InnoDB是MySQL的默認(rèn)存儲引擎,它管理數(shù)據(jù)的方式是通過行(Row)組成頁(Page),頁再組成區(qū)(Extent),區(qū)再組成段(Segment),最后段組成表空間(Tablespace)。其中,頁是InnoDB存儲的基本單位,其大小通常為16KB。
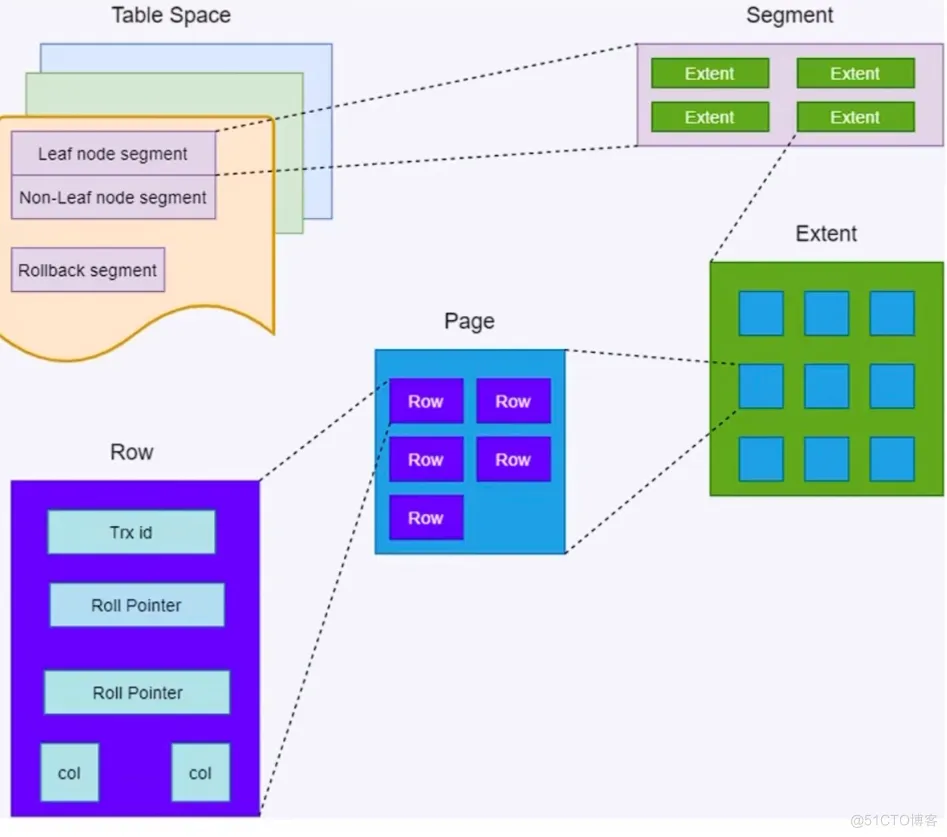
5. 垂直分表與InnoDB存儲結(jié)構(gòu)的關(guān)聯(lián)
減少跨頁檢索:
- 在InnoDB存儲結(jié)構(gòu)中,數(shù)據(jù)是按頁存儲的。如果表中的字段過多,每行數(shù)據(jù)占用的空間就會增大,這可能導(dǎo)致一行數(shù)據(jù)跨越多個頁存儲。當(dāng)進(jìn)行查詢時,如果需要跨頁檢索數(shù)據(jù),就會增加I/O操作的次數(shù),降低查詢效率。
- 通過垂直分表,將不常用或大字段拆分到單獨(dú)的表中,可以減少主表的寬度,使每行數(shù)據(jù)占用的空間減小,從而減少跨頁檢索的可能性,提高查詢效率。
優(yōu)化頁內(nèi)數(shù)據(jù)行存儲:
- InnoDB存儲引擎在壓縮和解壓縮時會花費(fèi)額外的時間。如果表中的數(shù)據(jù)行跨頁存儲,那么在解壓縮時需要處理更多的數(shù)據(jù),這會增加I/O負(fù)擔(dān)。
- 通過垂直分表,可以優(yōu)化頁內(nèi)數(shù)據(jù)行的存儲,使更多的數(shù)據(jù)行能夠在同一個頁內(nèi)存儲,從而減少跨頁檢索和磁盤掃描的范圍,達(dá)到提高查詢效率的目的。
提升緩存命中率:
- 數(shù)據(jù)庫緩存通常只能存儲有限的數(shù)據(jù)量。當(dāng)表寬度較大時,緩存中可能只能存儲少量的數(shù)據(jù)行,這降低了緩存的命中率。
- 通過垂直分表,將表拆分成更小的表,可以使更多的數(shù)據(jù)行能夠被緩存,從而提高緩存命中率,減少磁盤I/O操作,提高數(shù)據(jù)庫性能。