阿里二面:為什么要分庫分表?
本文轉載自微信公眾號「蘇三說技術」,作者因為熱愛所以堅持ing。轉載本文請聯系蘇三說技術公眾號。
前言
在高并發系統當中,分庫分表是必不可少的技術手段之一,同時也是BAT等大廠面試時,經常考的熱門考題。
你知道我們為什么要做分庫分表嗎?
這個問題要從兩條線說起:垂直方向 和 水平方向。
1 垂直方向
垂直方向主要針對的是業務,下面聊聊業務的發展跟分庫分表有什么關系。
1.1 單庫
在系統初期,業務功能相對來說比較簡單,系統模塊較少。
為了快速滿足迭代需求,減少一些不必要的依賴。更重要的是減少系統的復雜度,保證開發速度,我們通常會使用單庫來保存數據。
系統初期的數據庫架構如下:
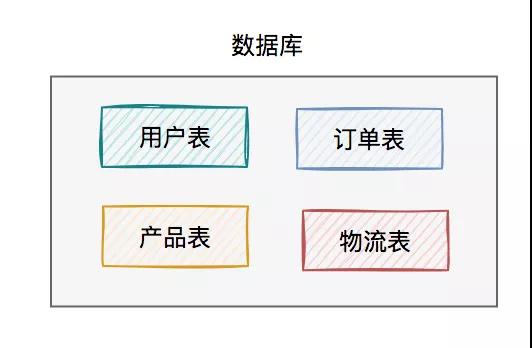
此時,使用的數據庫方案是:一個數據庫包含多張業務表。用戶讀數據請求和寫數據請求,都是操作的同一個數據庫
1.2 分表
系統上線之后,隨著業務的發展,不斷的添加新功能。導致單表中的字段越來越多,開始變得有點不太好維護了。
一個用戶表就包含了幾十甚至上百個字段,管理起來有點混亂。
這時候該怎么辦呢?
答:分表。
將用戶表拆分為:用戶基本信息表 和 用戶擴展表。
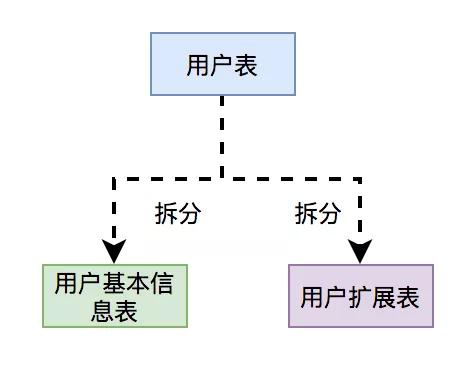
用戶基本信息表中存的是用戶最主要的信息,比如:用戶名、密碼、別名、手機號、郵箱、年齡、性別等核心數據。
這些信息跟用戶息息相關,查詢的頻次非常高。
而用戶擴展表中存的是用戶的擴展信息,比如:所屬單位、戶口所在地、所在城市等等,非核心數據。
這些信息只有在特定的業務場景才需要查詢,而絕大數業務場景是不需要的。
所以通過分表把核心數據和非核心數據分開,讓表的結構更清晰,職責更單一,更便于維護。
除了按實際業務分表之外,我們還有一個常用的分表原則是:把調用頻次高的放在一張表,調用頻次低的放在另一張表。
有個非常經典的例子就是:訂單表和訂單詳情表。
1.3 分庫
不知不覺,系統已經上線了一年多的時間了。經歷了N個迭代的需求開發,功能已經非常完善。
系統功能完善,意味著系統各種關聯關系,錯綜復雜。
此時,如果不趕快梳理業務邏輯,后面會帶來很多隱藏問題,會把自己坑死。
這就需要按業務功能,劃分不同領域了。把相同領域的表放到同一個數據庫,不同領域的表,放在另外的數據庫。
具體拆分過程如下:
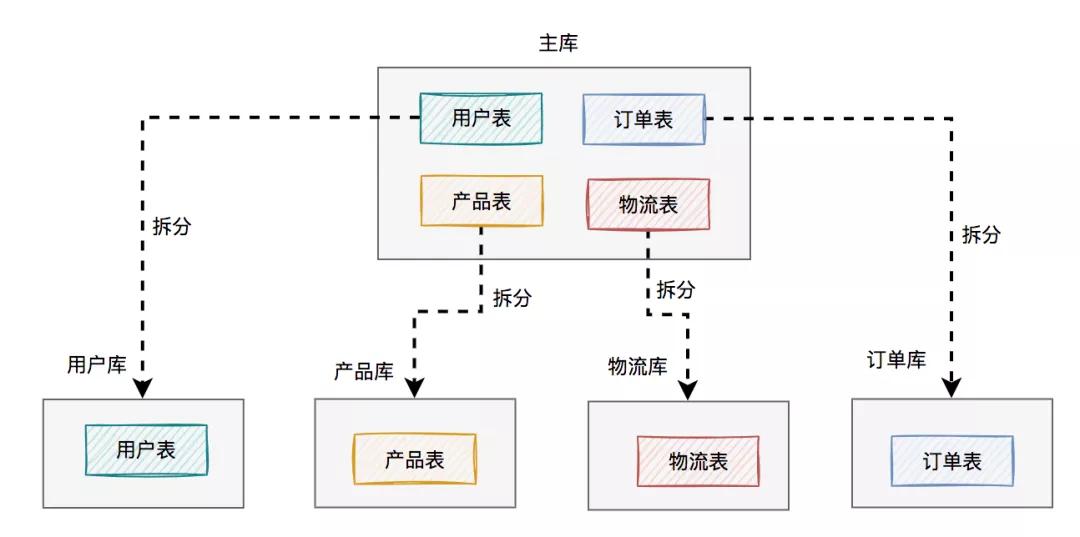
將用戶、產品、物流、訂單相關的表,從原來一個數據庫中,拆分成單獨的用戶庫、產品庫、物流庫和訂單庫,一共四個數據庫。
在這里為了看起來更直觀,每個庫我只畫了一張表,實際場景可能有多張表。
這樣按領域拆分之后,每個領域只用關注自己相關的表,職責更單一了,一下子變得更好維護了。
1.4 分庫分表
有時候按業務,只分庫,或者只分表是不夠的。比如:有些財務系統,需要按月份和年份匯總,所有用戶的資金。
這就需要做:分庫分表了。
每年都有個單獨的數據庫,每個數據庫中,都有12張表,每張表存儲一個月的用戶資金數據。
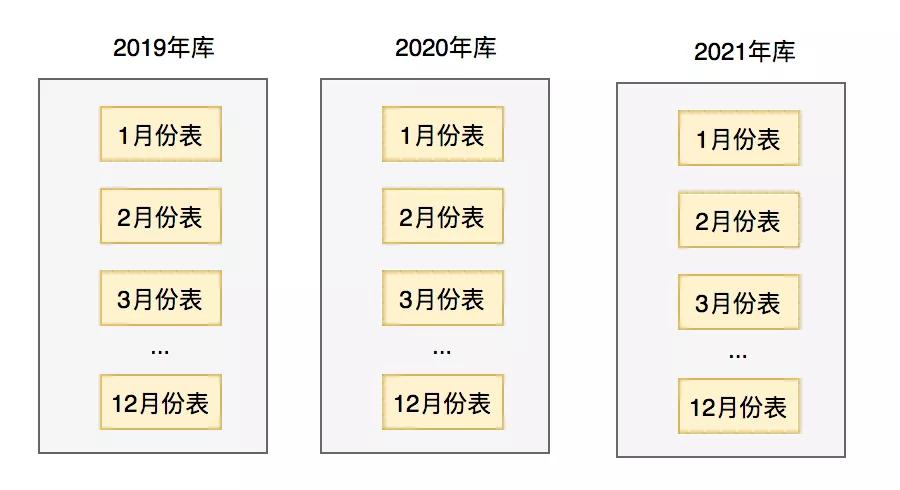
這樣分庫分表之后,就能非常高效的查詢出某個用戶每個月,或者每年的資金了。
此外,還有些比較特殊的需求,比如需要按照地域分庫,比如:華中、華北、華南等區,每個區都有一個單獨的數據庫。
甚至有些游戲平臺,按接入的游戲廠商來做分庫分表。
2 水平方向
水分方向主要針對的是數據,下面聊聊數據跟分庫分表又有什么關系。
2.1 單庫
在系統初期,由于用戶非常少,所以系統并發量很小。并且存在表中的數據量也非常少。
這時的數據庫架構如下:
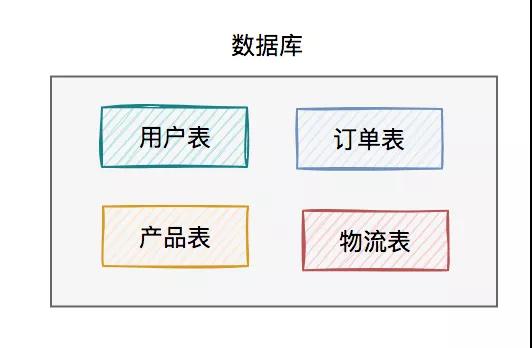
此時,使用的數據庫方案同樣是:一個master數據庫包含多張業務表。
用戶讀數據請求和寫數據請求,都是操作的同一個數據庫,該方案比較適合于并發量很低的業務場景。
2.2 主從讀寫分離
系統上線一段時間后,用戶數量增加了。
此時,你會發現用戶的請求當中,讀數據的請求占據了大部分,真正寫數據的請求占比很少。
眾所周知,數據庫連接是有限的,它是非常寶貴的資源。而每次數據庫的讀或寫請求,都需要占用至少一個數據庫連接。
如果寫數據請求需要的數據庫連接,被讀數據請求占用完了,不就寫不了數據了?
這樣問題就嚴重了。
為了解決該問題,我們需要把讀庫和寫庫分開。
于是,就出現了主從讀寫分離架構:
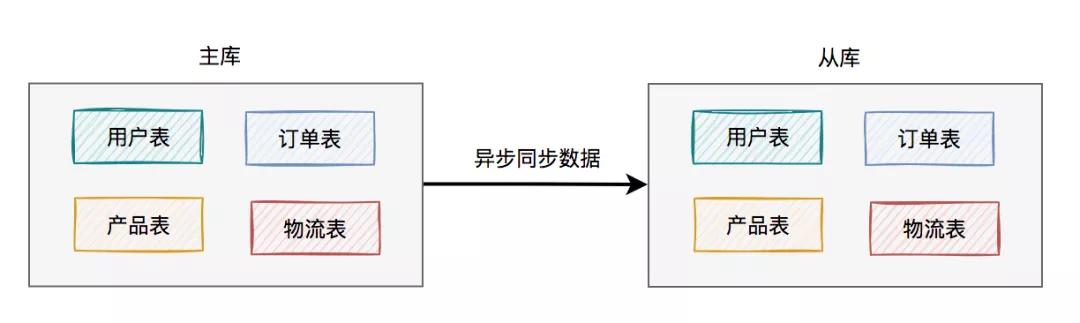
考慮剛開始用戶量還沒那么大,選擇的是一主一從的架構,也就是常說的一個master一個slave。
所有的寫數據請求,都指向主庫。一旦主庫寫完數據之后,立馬異步同步給從庫。這樣所有的讀數據請求,就能及時從從庫中獲取到數據了(除非網絡有延遲)。
讀寫分離方案可以解決上面提到的單節點問題,相對于單庫的方案,能夠更好的保證系統的穩定性。
因為如果主庫掛了,可以升級從庫為主庫,將所有讀寫請求都指向新主庫,系統又能正常運行了。
讀寫分離方案其實也是分庫的一種,它相對于為數據做了備份,它已經成為了系統初期的首先方案。
但這里有個問題就是:如果用戶量確實有些大,如果master掛了,升級slave為master,將所有讀寫請求都指向新master。
但此時,如果這個新master根本扛不住所有的讀寫請求,該怎么辦?
這就需要一主多從的架構了:
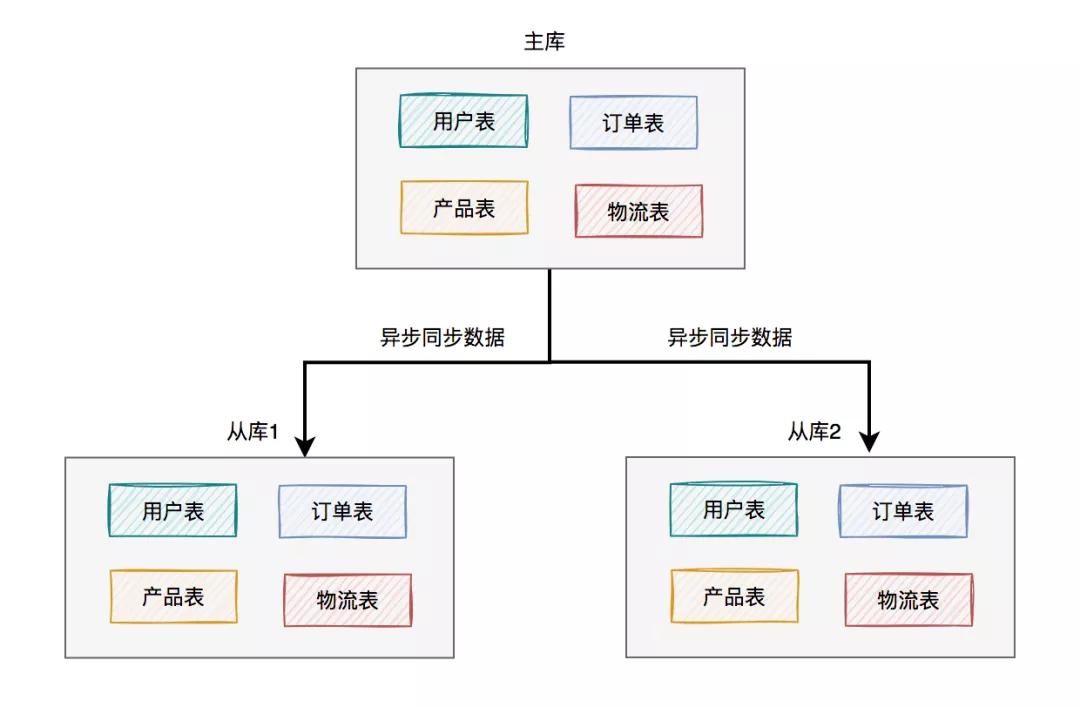
上圖中我列的是一主兩從,如果master掛了,可以選擇從庫1或從庫2中的一個,升級為新master。假如我們在這里升級從庫1為新master,則原來的從庫2就變成了新master的的slave了。
調整之后的架構圖如下:
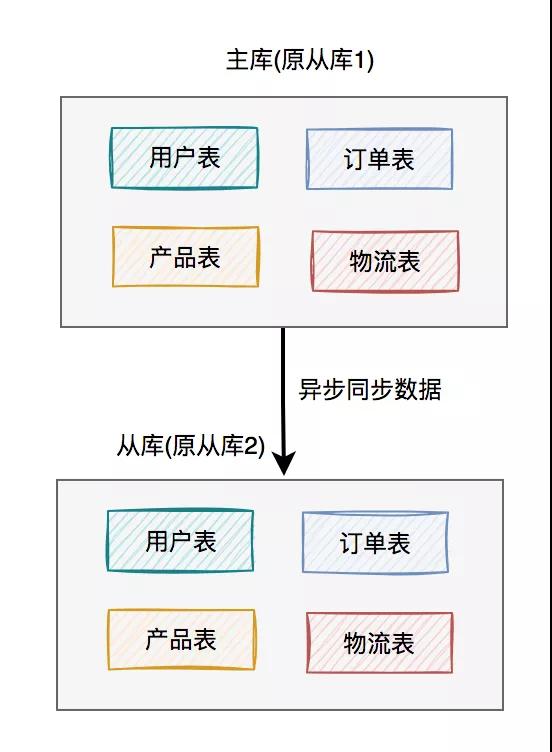
這樣就能解決上面的問題了。
除此之外,如果查詢請求量再增大,我們還可以將架構升級為一主三從、一主四從...一主N從等。
2.3 分庫
上面的讀寫分離方案確實可以解決讀請求大于寫請求時,導致master節點扛不住的問題。但如果某個領域,比如:用戶庫。如果注冊用戶的請求量非常大,即寫請求本身的請求量就很大,一個master庫根本無法承受住這么大的壓力。
這時該怎么辦呢?
答:建立多個用戶庫。
用戶庫的拆分過程如下:
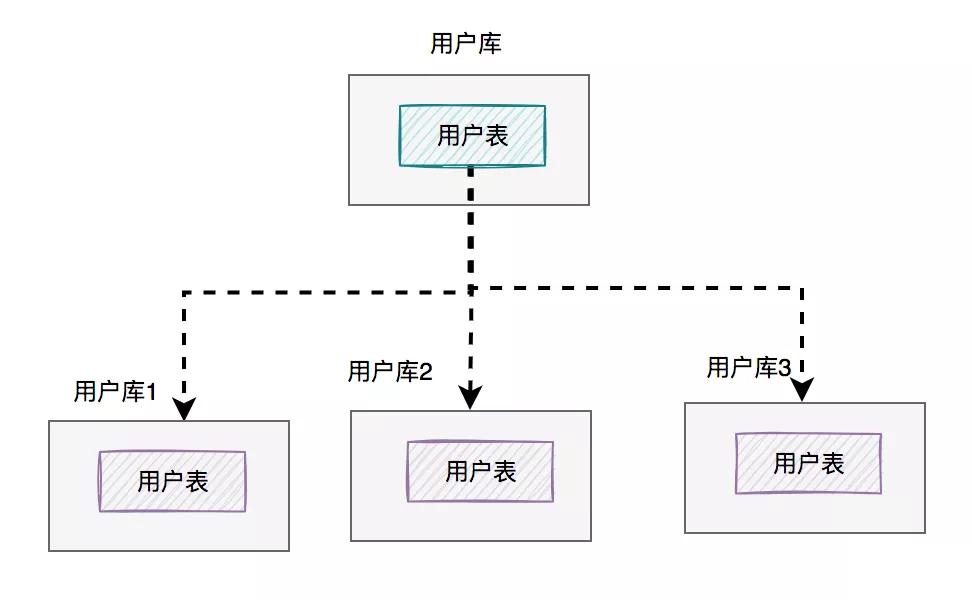
在這里我將用戶庫拆分成了三個庫(真實場景不一定是這樣的),每個庫的表結構是一模一樣的,只有存儲的數據不一樣。
2.4 分表
用戶請求量上來了,帶來的勢必是數據量的成本上升。即使做了分庫,但有可能單個庫,比如:用戶庫,出現了5000萬的數據。
根據經驗值,單表的數據量應該盡量控制在1000萬以內,性能是最佳的。如果有幾千萬級的數據量,用單表來存,性能會變得很差。
如果數據量太大了,需要建立的索引也會很大,從小到大檢索一次數據,會非常耗時,而且非常消耗cpu資源。
這時該怎么辦呢?
答:分表,這樣可以控制每張表的數據量,和索引大小。
表拆分過程如下:
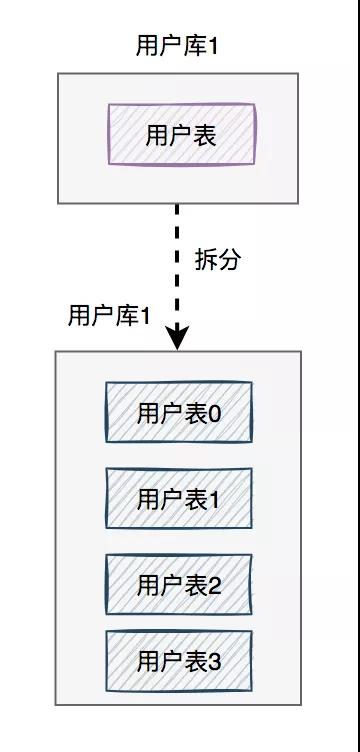
我在這里將用戶庫中的用戶表,拆分成了四張表(真實場景不一定是這樣的),每張表的表結構是一模一樣的,只是存儲的數據不一樣。
如果以后用戶數據量越來越大,只需再多分幾張用戶表即可。
2.5 分庫分表
當系統發展到一定的階段,用戶并發量大,而且需要存儲的數據量也很多。這時該怎么辦呢?
答:需要做分庫分表。
如下圖所示:
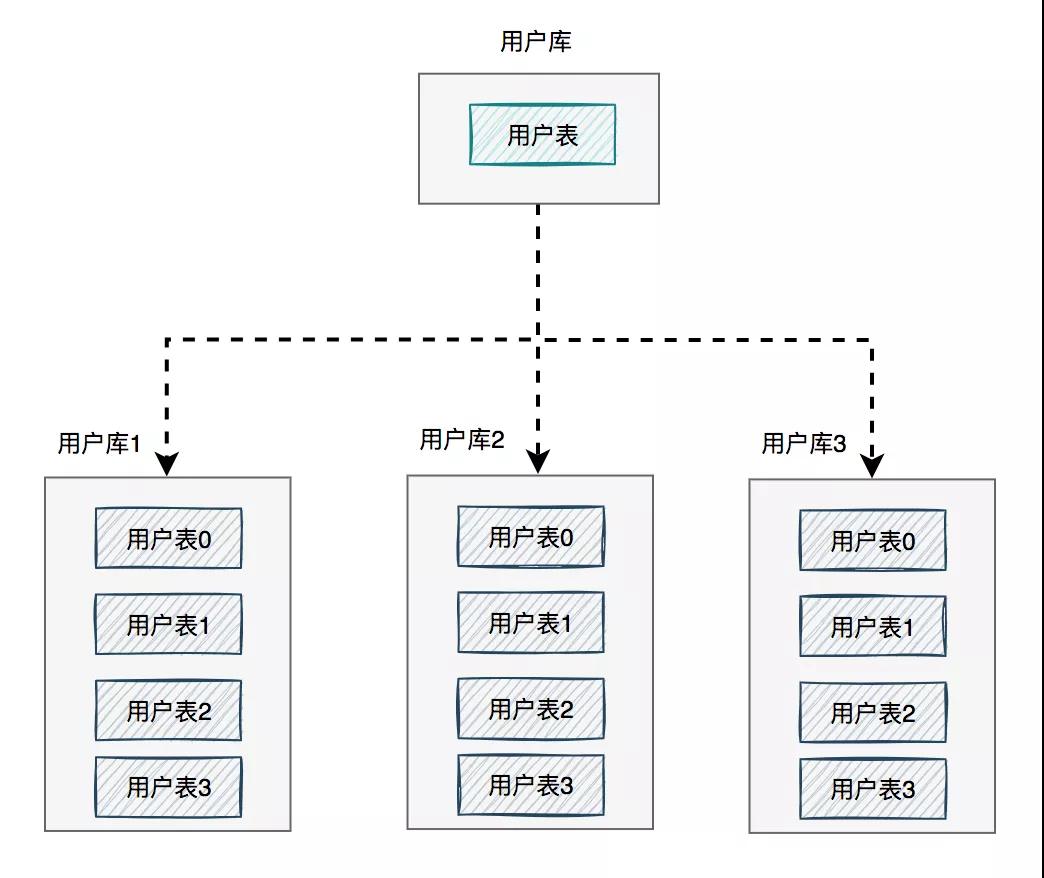
圖中將用戶庫拆分成了三個庫,每個庫都包含了四張用戶表。
如果有用戶請求過來的時候,先根據用戶id路由到其中一個用戶庫,然后再定位到某張表。
路由的算法挺多的:
- 根據id取模,比如:id=7,有4張表,則7%4=3,模為3,路由到用戶表3。
- 給id指定一個區間范圍,比如:id的值是0-10萬,則數據存在用戶表0,id的值是10-20萬,則數據存在用戶表1。
- 一致性hash算法
這篇文章就不過多介紹了,后面會有文章專門介紹這些路由算法的。
3 真實案例
接下來,廢話不多說,給大家分享三個我參與過的分庫分表項目經歷,給有需要的朋友一個參考。
3.1 分庫
我之前待過一家公司,我們團隊是做游戲運營的,我們公司提供平臺,游戲廠商接入我們平臺,推廣他們的游戲。
游戲玩家通過我們平臺登錄,成功之后跳轉到游戲廠商的指定游戲頁面,該玩家就能正常玩游戲了,還可以充值游戲幣。
這就需要建立我們的賬號體系和游戲廠商的賬號的映射關系,游戲玩家通過登錄我們平臺的游戲賬號,成功之后轉換成游戲廠商自己平臺的賬號。
這里有兩個問題:
- 每個游戲廠商的接入方式可能都不一樣,賬號體系映射關系也有差異。
- 用戶都從我們平臺登錄,成功之后跳轉到游戲廠商的游戲頁面。當時有N個游戲廠商接入了,活躍的游戲玩家比較多,登錄接口的并發量不容小覷。
為了解決這兩個問題,我們當時采用的方案是:分庫。即針對每一個游戲都單獨建一個數據庫,數據庫中的表結構允許存在差異。
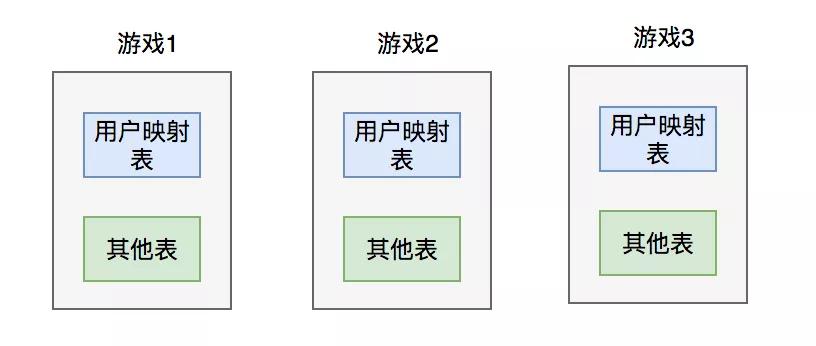
我們當時沒有進一步分表,是因為當時考慮每種游戲的用戶量,還沒到大到離譜的地步。不像王者榮耀這種現象級的游戲,有上億的玩家。
其中有個比較關鍵的地方是:登錄接口中需要傳入游戲id字段,通過該字段,系統就知道要操作哪個庫,因為庫名中就包含了游戲id的信息。
3.2 分表
還是在那家游戲平臺公司,我們還有另外一個業務就是:金鉆會員。
說白了就是打造了一套跟游戲相關的會員體系,為了保持用戶的活躍度,開通會員有很多福利,比如:送游戲幣、充值有折扣、積分兌換、抽獎、專屬客服等等。
在這套會員體系當中,有個非常重要的功能就是:積分。
用戶有很多種途徑可以獲取積分,比如:簽到、充值、玩游戲、抽獎、推廣、參加活動等等。
積分用什么用途呢?
- 退換實物禮物
- 兌換游戲幣
- 抽獎
說了這么多,其實就是想說,一個用戶一天當中,獲取積分或消費積分都可能有很多次,那么,一個用戶一天就可能會產生幾十條記錄。
如果用戶多了的話,積分相關的數據量其實挺驚人的。
我們當時考慮了,水平方向的數據量可能會很大,但是用戶并發量并不大,不像登錄接口那樣。
所以采用的方案是:分表。
當時使用一個積分數據庫就夠了,但是分了128張表。然后根據用戶id,進行hash除以128取模。
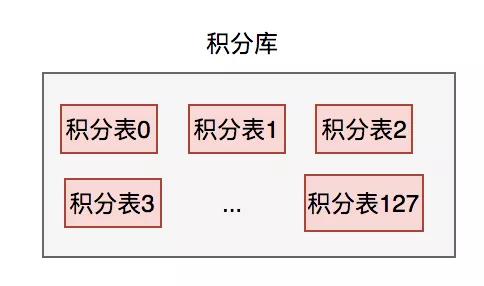
需要特別注意的是,分表的數量最好是2的冪次方,方便以后擴容。
3.3 分庫分表
后來我去了一家從事餐飲軟件開發的公司。這個公司有個特點是在每天的中午和晚上的就餐高峰期,用戶的并發量很大。
用戶吃飯前需要通過我們系統點餐,然后下單,然后結賬。當時點餐和下單的并發量挺大的。
餐廳可能會有很多人,每個人都可能下多個訂單。這樣就會導致用戶的并發量高,并且數據量也很大。
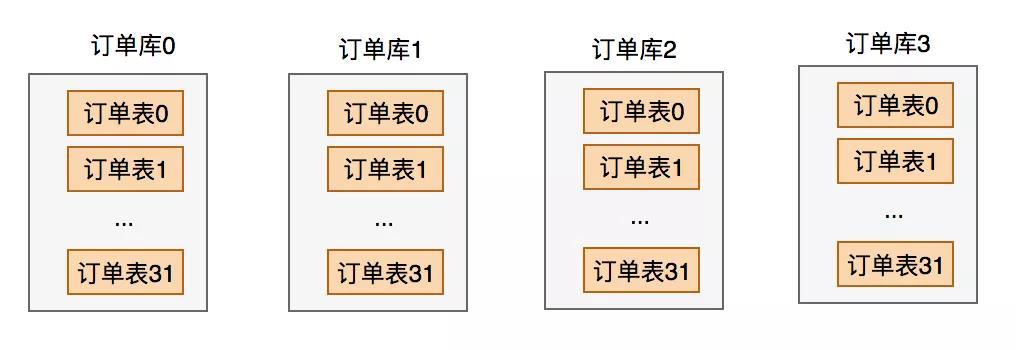
所以,綜合考慮了一下,當時我們采用的技術方案是:分庫分表。
經過調研之后,覺得使用了當當網開源的基于jdbc的中間件框架:sharding-jdbc。
當時分了4個庫,每個庫有32張表。
4 總結
上面主要從:垂直和水平,兩個方向介紹了我們的系統為什么要分庫分表。
說實話垂直方向(即業務方向)更簡單。
在水平方向(即數據方向)上,分庫和分表的作用,其實是有區別的,不能混為一談。
- 分庫:是為了解決數據庫連接資源不足問題,和磁盤IO的性能瓶頸問題。
- 分表:是為了解決單表數據量太大,sql語句查詢數據時,即使走了索引也非常耗時問題。此外還可以解決消耗cpu資源問題。
- 分庫分表:可以解決 數據庫連接資源不足、磁盤IO的性能瓶頸、檢索數據耗時 和 消耗cpu資源等問題。
如果在有些業務場景中,用戶并發量很大,但是需要保存的數據量很少,這時可以只分庫,不分表。
如果在有些業務場景中,用戶并發量不大,但是需要保存的數量很多,這時可以只分表,不分庫。
如果在有些業務場景中,用戶并發量大,并且需要保存的數量也很多時,可以分庫分表。
好了,今天的內容就先到這里。
是不是有點意猶未盡?
沒關系,其實分庫分表相關內容挺多的,本文作為分庫分表系列的第一彈,作為一個開胃小菜吧,分享給大家。
在文章末尾順便提幾個問題:
- 分庫分表的具體實現方案有哪些?
- 分庫分表后如何平滑擴容?
- 分庫分表后帶來了哪些問題?
- 如何在項目中實現分庫分表功能?