













盤一盤 Python 的 itertools:數(shù)據(jù)分組
分組處理數(shù)據(jù),你只會(huì)使用 pandas? 那你就錯(cuò)了。其實(shí)不借助第三方庫,我們也可以輕松實(shí)現(xiàn)數(shù)據(jù)分組。
今天內(nèi)容:
- 使用字典做數(shù)據(jù)分組
- 使用 itertools 的 groupby 實(shí)現(xiàn)數(shù)據(jù)分組
- 如何封裝函數(shù),使其更具通用性

分組
字典是python中非常常用的一種數(shù)據(jù)結(jié)構(gòu)。我們可以用字典來實(shí)現(xiàn)數(shù)據(jù)分組。
比如,我們有這樣一個(gè)列表:
people_list = [
{'姓名': '張三', '性別': '男', '年齡': '25'},
{'姓名': '李四', '性別': '女', '年齡': '30'},
{'姓名': '王五', '性別': '男', '年齡': '22'},
{'姓名': '趙六', '性別': '女', '年齡': '28'},
{'姓名': '周六', '性別': '女', '年齡': '26'},
{'姓名': '陳七', '性別': '男', '年齡': '24'},
{'姓名': '楊八', '性別': '女', '年齡': '27'},
]我們想按照性別分組,統(tǒng)計(jì)平級(jí)年齡和人數(shù)。
使用字典的實(shí)現(xiàn)方式:
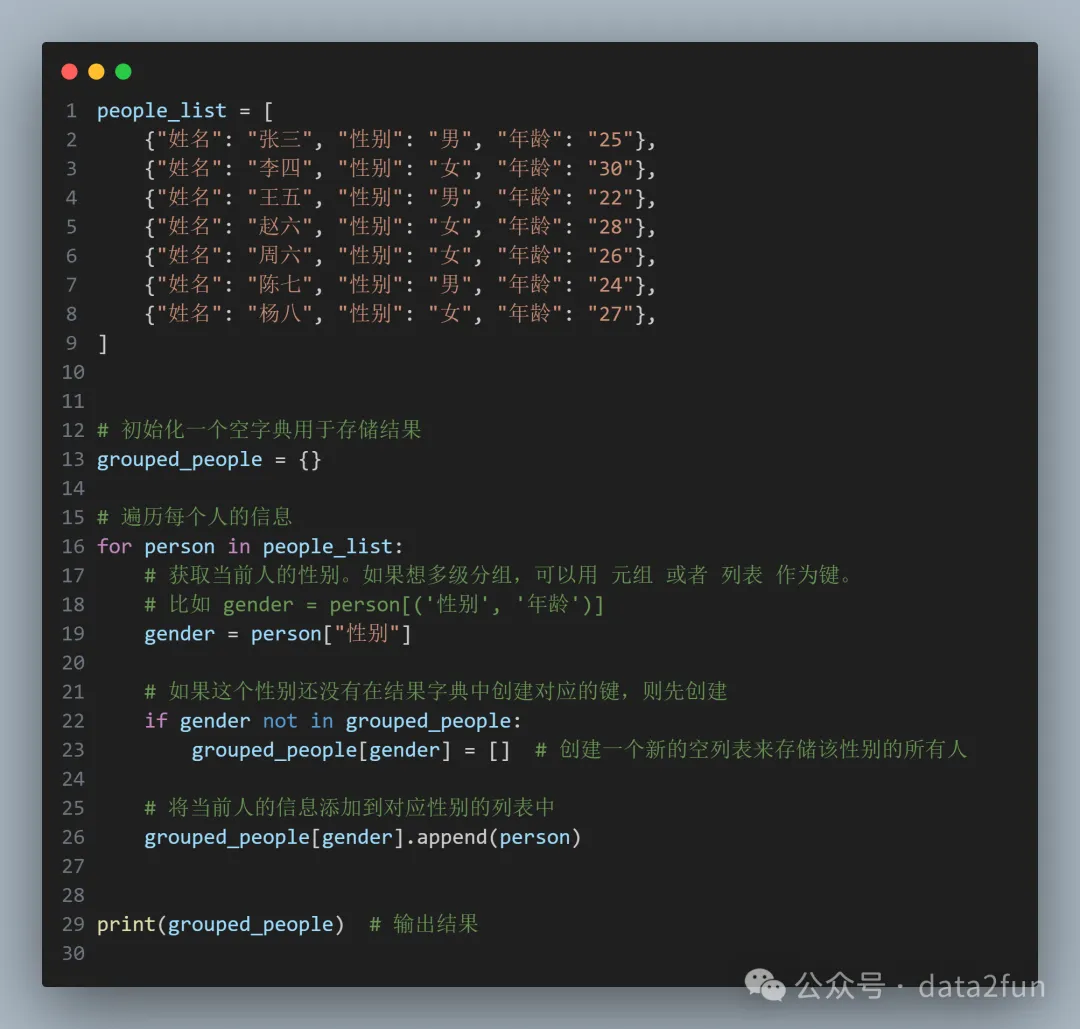
結(jié)果:
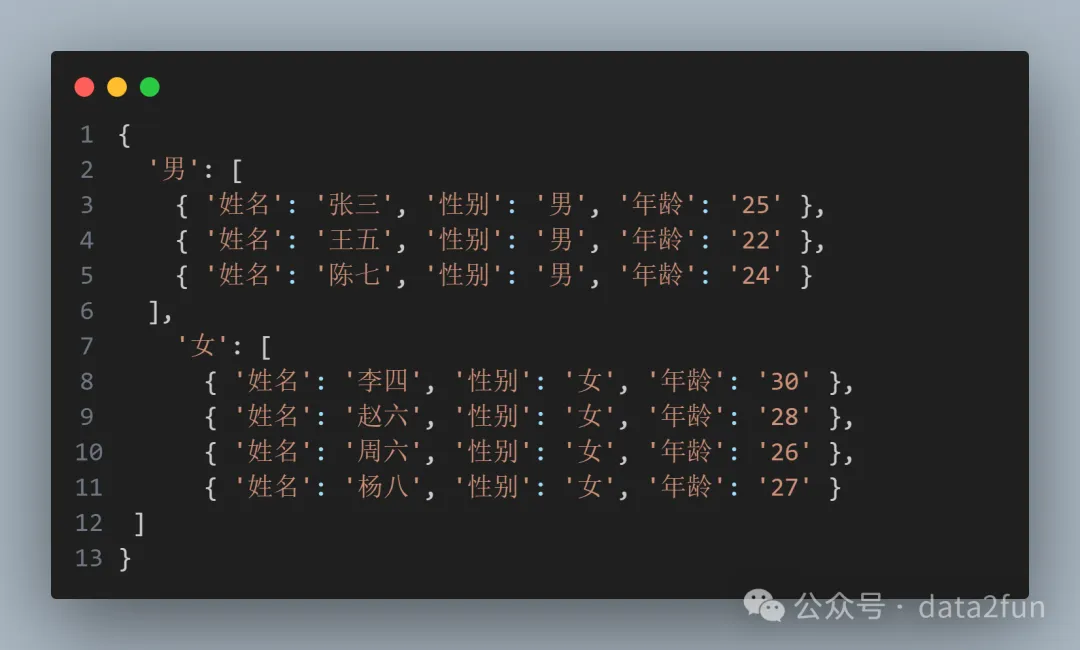
現(xiàn)在結(jié)果字典有兩項(xiàng)數(shù)據(jù)(男性和女性),分別對(duì)應(yīng)著兩個(gè)列表(里面就是該性別的數(shù)據(jù),是一個(gè)個(gè)字典)。
上面代碼,可以使用 defaultdict 改進(jìn):
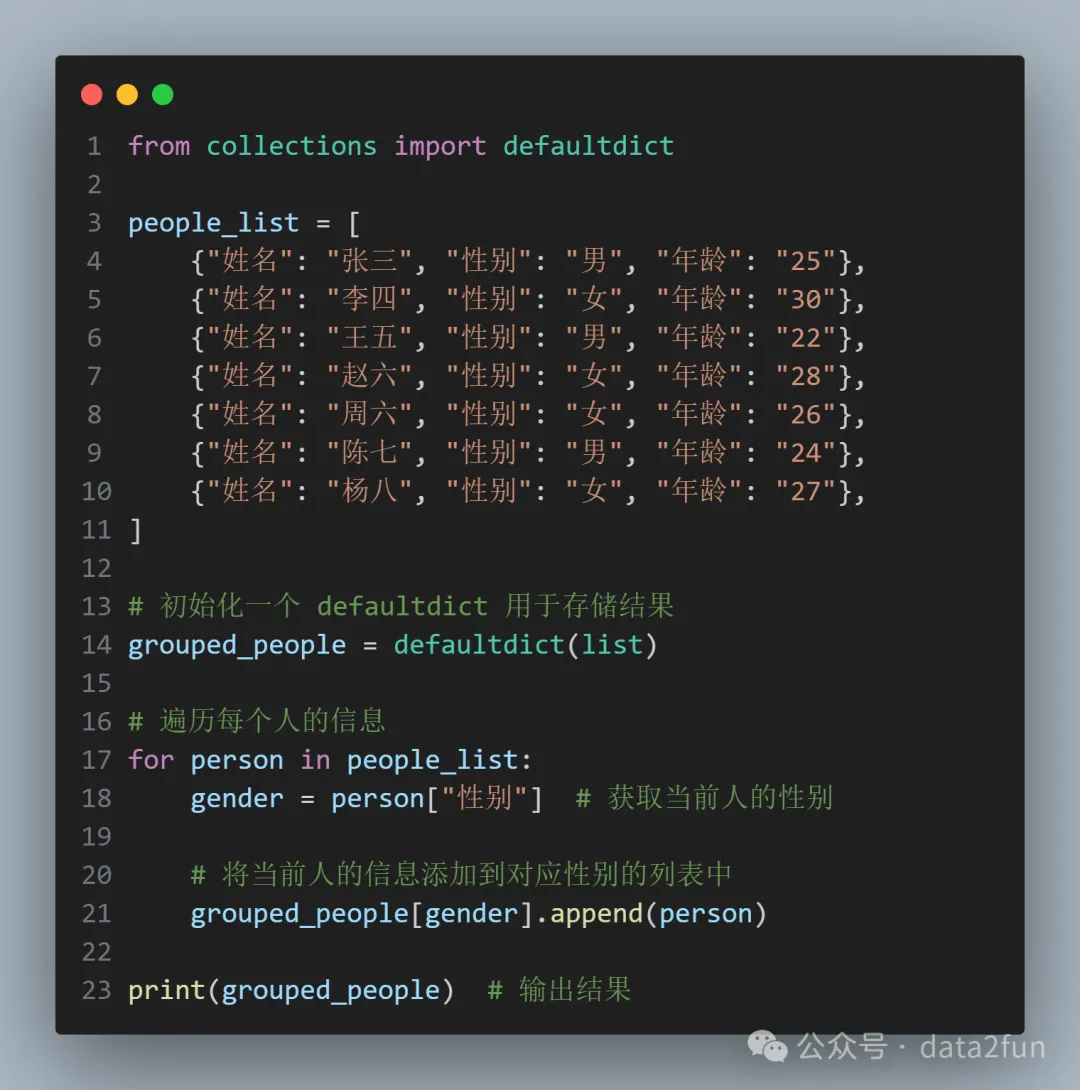
行21: 當(dāng)訪問一個(gè)不存在的鍵時(shí),defaultdict 會(huì)自動(dòng)創(chuàng)建一個(gè)空列表,并返回它。
如果不想使用字典,而是想使用 itertools 的 groupby 實(shí)現(xiàn),可以這樣:
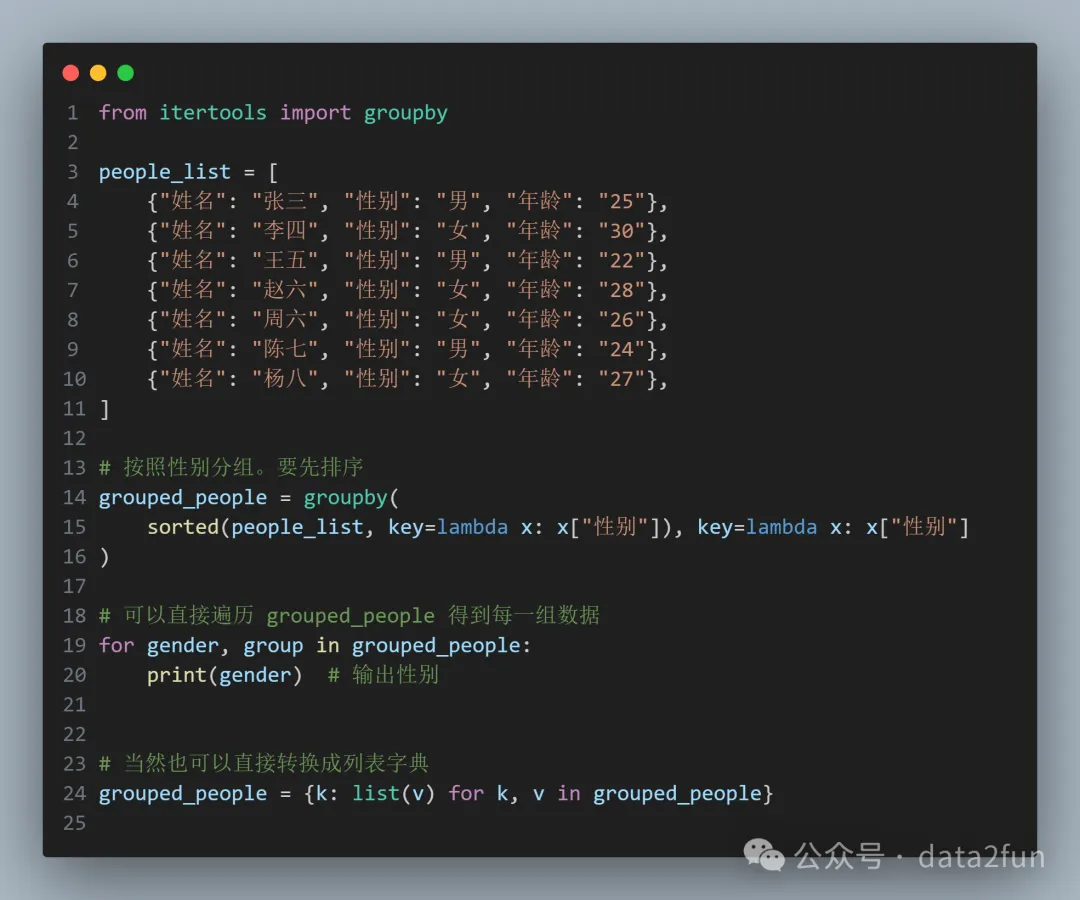
行15:分組前對(duì)數(shù)據(jù)做排序才行
封裝函數(shù)
現(xiàn)在已經(jīng)對(duì)數(shù)據(jù)進(jìn)行了分組,所謂的分組統(tǒng)計(jì)(平級(jí)年齡和人數(shù)),只不過是對(duì)每個(gè)性別的列表進(jìn)行遍歷,統(tǒng)計(jì)每個(gè)人的年齡,然后求和。
但統(tǒng)計(jì)處理多種多樣,為此我們可以封裝成通用的函數(shù)。
假設(shè)封裝的函數(shù)叫 group_by ,看看我們期待的使用方式:
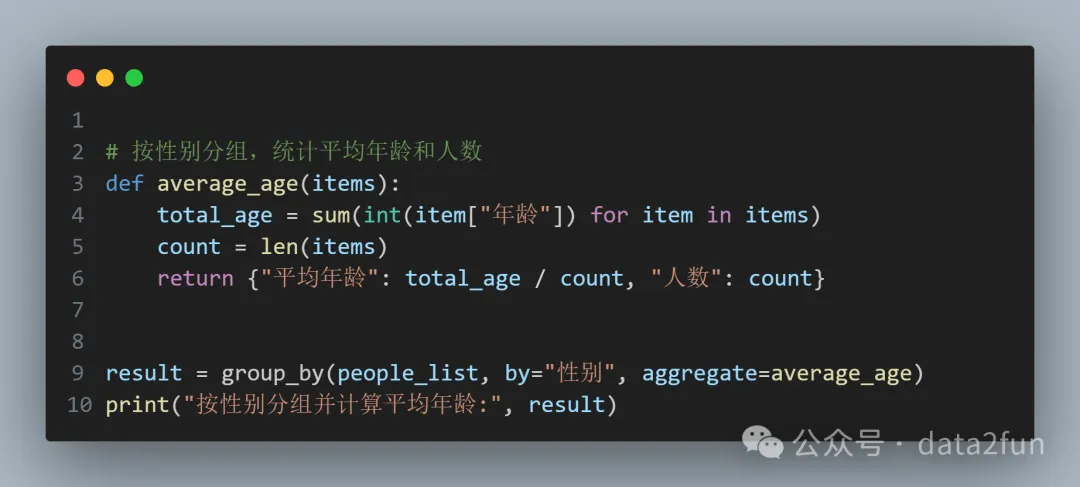
- 行9:參數(shù) by :指定分組的字段,也可以指定多個(gè)字段,比如 by=["性別", "年齡"] 。
- 行9:參數(shù) aggregate :指定聚合函數(shù)。
確定了使用方式,那么我們可以開始封裝函數(shù):
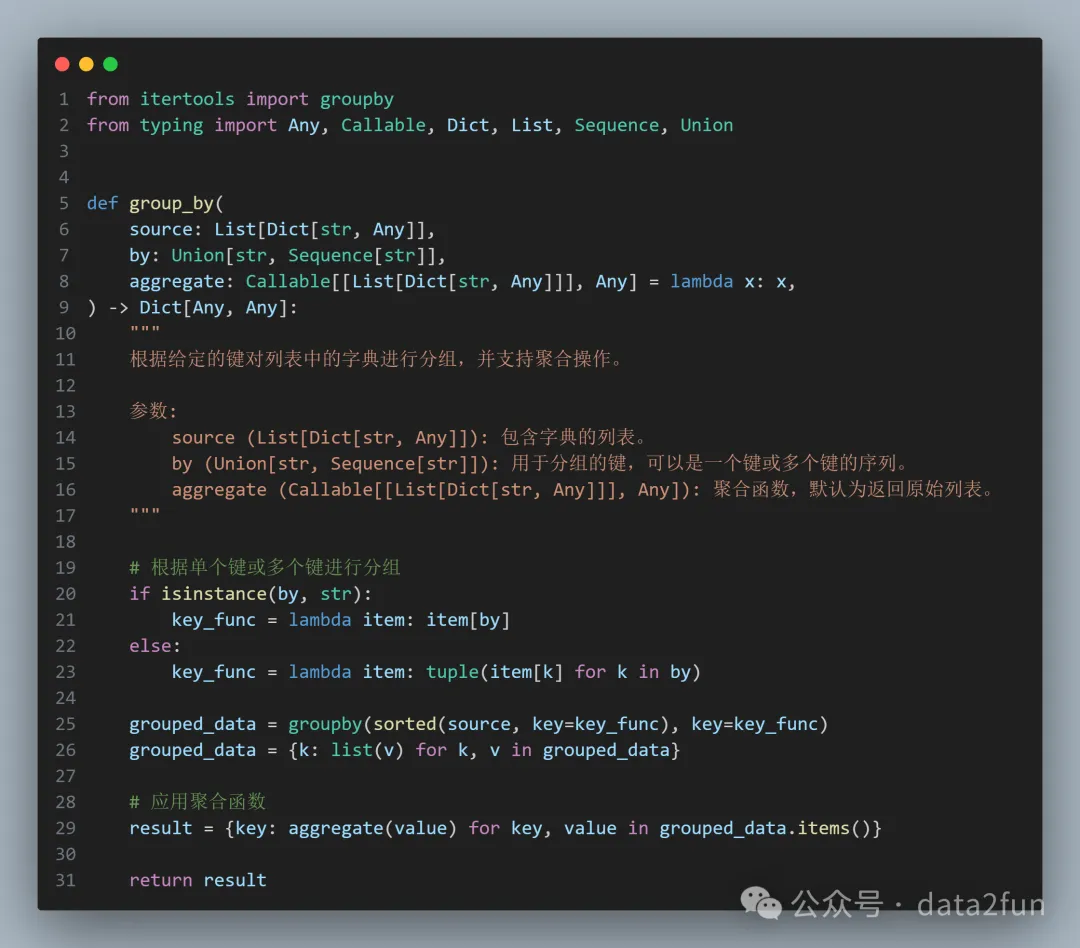
- 行20-23:讓參數(shù) by 支持單個(gè)字符串或多列分組
- 行29:再次遍歷分組的結(jié)果,然后應(yīng)用聚合函數(shù)


















