深入解讀 MySQL 的 MVCC 與事務隔離級別
在當今的數據庫世界中,MySQL 以其強大的功能和廣泛的應用備受矚目。而其中的 MVCC(多版本并發控制)和事務隔離級別更是關鍵且核心的概念,它們猶如數據庫運行的精密齒輪,協同作用確保著數據的完整性、一致性和高效的并發處理。
當我們深入探究 MySQL 的內部機制時,MVCC 展現出其獨特的魅力,它巧妙地解決了并發操作中可能產生的諸多問題。與此同時,事務隔離級別則為不同場景下的數據處理提供了靈活而精準的規則框架。理解這兩者,不僅是對 MySQL 技術精髓的把握,更是開啟高效數據庫應用和系統開發的關鍵鑰匙。在接下來的篇章中,我們將一同踏上這場解析 MySQL MVCC 和事務隔離級別的精彩之旅,逐步揭開它們神秘的面紗,探尋其背后蘊含的深刻原理和實際應用價值。

一、詳解事務的基本概念
1. 什么是事務
現在我們開發的一個功能需要進行操作多張表,假如我們遇到以下幾種情況:
- 某個邏輯報錯
- 數據庫連接中斷
- 某臺服務器突然宕機
- .......
這時候我們數據庫執行的操作可能才到一半,所以為了避免這種一半一半的情況,我們就需要事務來保證數據一致性。 所以事務就是當作一個原子的邏輯組操作,要么全都成功執行,要么全部都失敗。事務有分分布式事務和數據庫事務,如果沒有特指,我們平時所說的事務都是數據庫事務,也就是本文探討的話題。
2. 事務的四大特性
- 原子性(Atomicity):一組操作要構成一個原子,原子可以看作事務的最小單位,不可在進行分割了,要么都執行,要么都不執行。
- 一致性(Consistency):經過一個事務的操作后,前后要保持數據一致性,例如我們要用數據庫記錄一次轉賬操作,那么兩個數據經過轉賬邏輯之后總額還是保持不變。
- 隔離性(Isolation):在并發場景下,每個事務之間的操作互不干擾。
- 持久性(Durability):存儲到數據庫中的數據永不丟失,及時數據庫發生故障,當然機器被破壞了那就另說了。
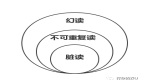
3. 并發事務帶來那些問題
這里筆者先說一個概念,具體會在后文示例中詳盡介紹。
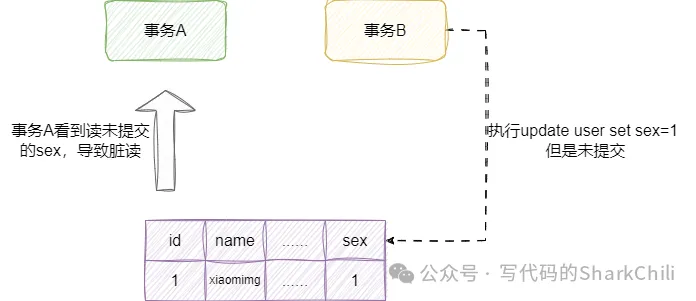
臟讀:我們舉個例子:
- 我們開啟一個事務A,準備讀取user表的數據。
- 此時,事務B將事務A要讀取的數據修改了,但事務還沒提交.
- A卻能看到這個未提交的結果即sex為1(而且這個結果后續還不一定提交)。
這種其他事務還沒提交的結果能被另一個事務看到的情況就屬于臟讀。
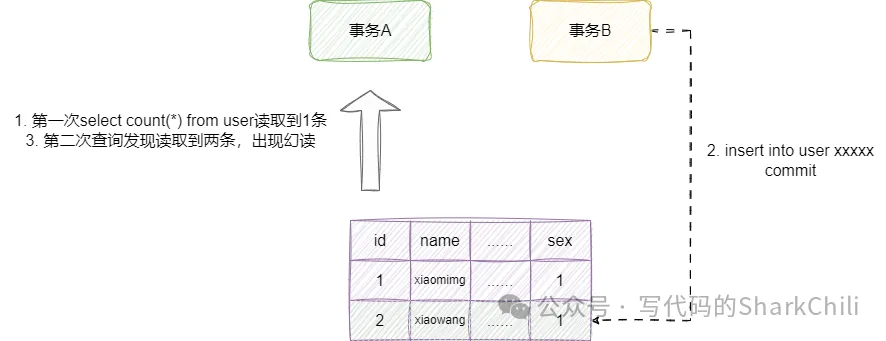
幻讀:我們再舉個例子:
- 事務A查詢user表,此時表中有10條數據。
- 在此期間,事務B插入5條數據。
- 事務A再次查發現有15條事務。
這種同一次事務兩次查詢結果不一致的情況是幻讀:
不可重復讀,仍然舉一個例子:
- 事務A讀取id為1的數據,name為xiaoming。
- 事務B在此期間更新id為1的數據并提交這個事務
- 結果事務A再次讀取時發現name變了。 這就是不可重復讀。
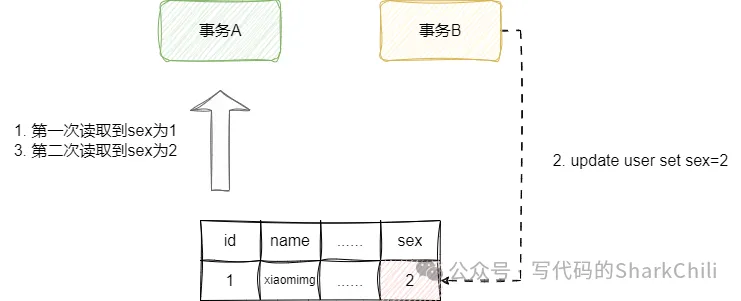
你可能會問了,這和幻讀聽起來是一個概念啊,他倆有什么區別? 幻讀說是針對插入或者刪除操作后導致數據前后不一致的情況,而不可重復讀是針對兩次相同查詢操作出現數據不一致。
數據丟失:這個就很好理解了,高并發場景下,事務A修改id為1的money+100,事務B修改id為1的money+200,他們統一時間讀取,先后寫入,這就導致如果事務A后寫入,那么money最后只加了100,如果事務B后寫入,那么money就少了100。
二、詳解事務的隔離級別
1. 讀未提交(READ UNCOMMITTED)
在這個級別下,任何事務的修改操作即使沒有提交,其他事務也能看到,造成我們上述所說的臟讀,對此我們不妨用下面這段SQL來驗證一下:
首先我們先建個測試表:
create table test2 (id int,name varchar(10),money int);
insert into test2 values(1,'xiaoming',100);
insert into test2 values(2,'xiaowang',100);事務A開啟事務,進行test2 的更新操作,不提交
start transaction;
-- 小明+100元
update test2 set money = money +100 where name ='xiaoming';
-- 小王減100元
update test2 set money =money -100 where name ='xiaowang';事務B設置為讀未提交的隔離級別:
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
select * from test2 t ;查詢結果是事務B看到了事務A的更新操作,造成臟讀。
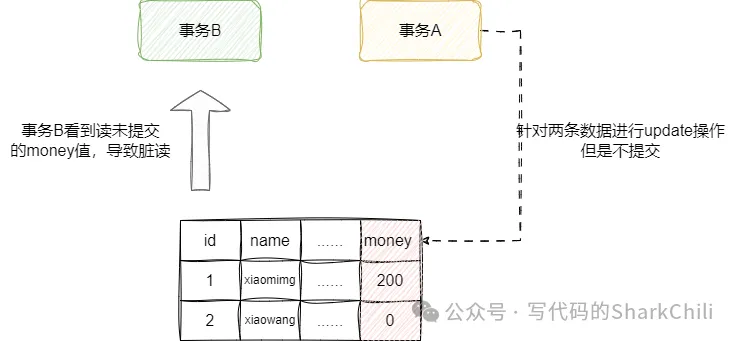
對應結果如下:
id|name |money|
--+--------+-----+
1|xiaoming| 200|
2|xiaowang| 0|同理這個讀未提交,也會造成:
- 幻讀(同一個事務同一次查詢記錄數不一樣)
- 不可重復讀(同一個事務下查詢記錄的值不一樣)
2. 讀已提交(READ COMMITTED)
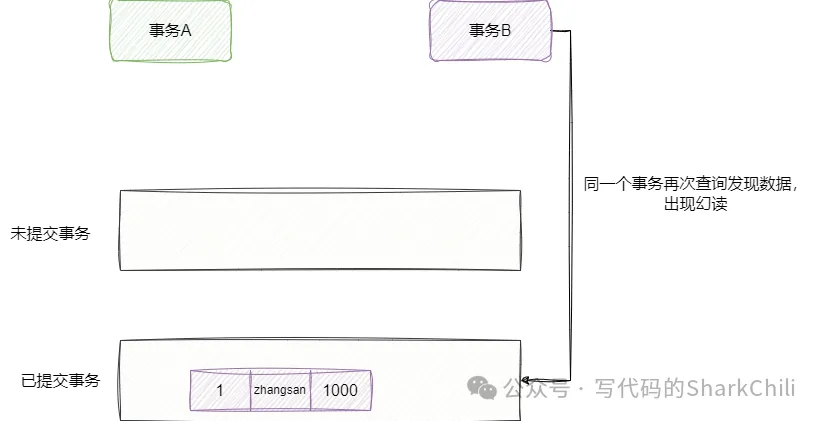
這個概念也很好理解,每個事務只能看到其他事務提交后的數據。避免了臟讀,但是無法避免幻讀和不可重復讀。 我們就以幻讀為例,如下圖,事務B首先查詢到數據表中沒有id為1的用戶,在這個查詢結束后,事務A進行一次插入操作但是事務還未提交。

然后事務A將數據提交,事務B再次查詢就發現了數據,出現幻讀:
了解流程之后,我們拿SQL印證一下,首先創建數據表:
drop table if exists account1;
CREATE TABLE `account1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `account1_un` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=UTF8MB4;事務B查詢,沒數據:
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
START TRANSACTION;
-- 查詢表,此時沒有數據
SELECT * from account1;事務A在此期間插入,事務不提交:
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
START TRANSACTION;
-- 在上一個事務查詢后,插入一條事務但是不提交
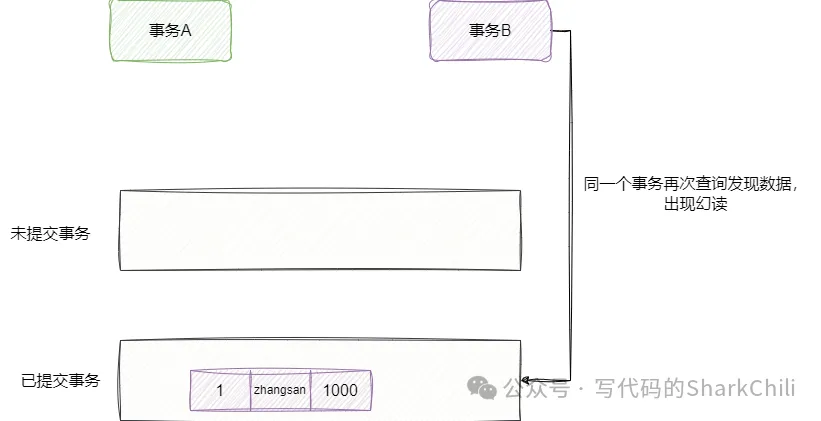
insert into account1(id,name,balance) values(1,'zhangsan',1000);此時事務B還是沒看到數據,然后我們將上述的事務A數據commit,事務B看到這條數據出現幻讀:
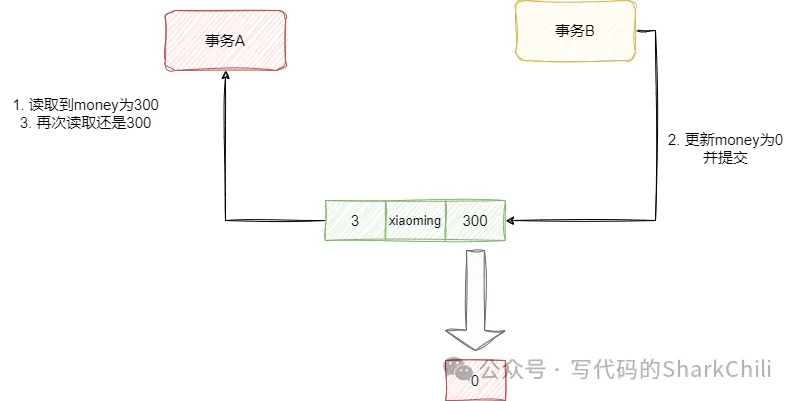
3. 可重復讀(REPEATABLE READ)
這個隔離級別,也很好理解,同一個事務內,多次查詢的數據都是一樣的。我們不妨基于上面的例子實驗一下
首先事務B查詢,沒有任何數據:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
select * from account1 a where id=3;此時xiaoming的數據為300:
id|name |balance|
--+--------+-------+
3|xiaoming| 100|事務A執行更新并提交:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
update account1 set balance=0 where id=3;
commit;事務B再查數據還是不變,還是300:
id|name |balance|
--+--------+-------+
3|xiaoming| 100|總的來說可重復讀避免了臟讀和不可重復讀,但是幻讀還是無法避免:
4. 串行化(SERIALIZABLE)
事務隔離最高級別,通過鎖的方式控制并發流程,解決上述一切問題。
三、詳解多版本并發控制MVCC
1. 當前讀和快照讀
快照讀:即讀取數據是從快照中獲取的,事務在進行事務讀取時不上鎖,這就是mysql并發讀寫性能高的原因之一。 而當前讀反之,讀取數據時會上鎖,這也就意味著即使你的隔離級別是可重復讀,你用當前讀也能讀取到其他事務的最新結果,造成不可重復讀。
我們舉個例子,首先事務A讀取數據,假設數據值是100:
begin;
-- 讀取到a的money為100
select * from account1 a ;事務B更新事務并提交:
update account1 set money=1000 where id=1;事務A使用快照讀,數據還是100:
select * from account1 a ; --快照讀 舊數據一旦使用當前讀,就是其他事務提交的新數據了:
--兩個都是當前讀,得到最新結果
select * from account1 a for update;
select * from account1 a lock in share mode;2. undo.log概念掃盲
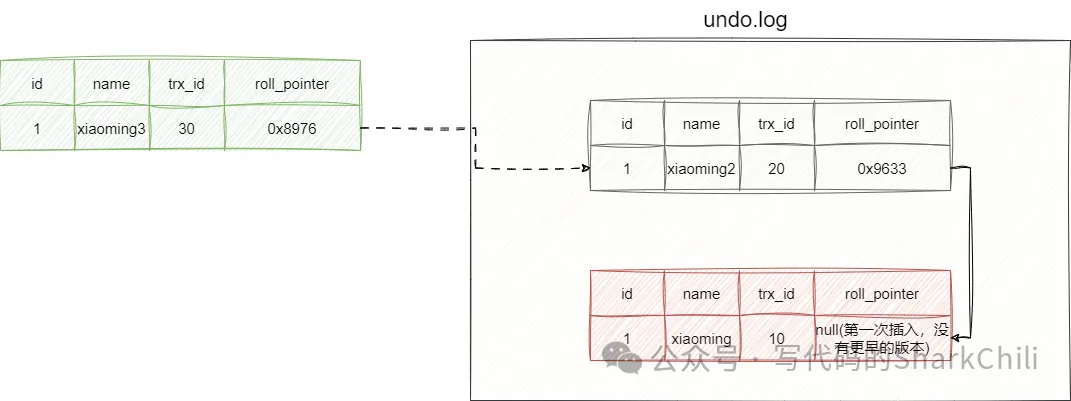
首先說說undo log,在innoDB的聚簇索引中,每一條記錄除了我們表中的數據以外,還會額外記錄名為事務id(transaction id)的隱藏列。每當用戶對當前數據進行修改操作后,新值的數據的事務id就會遞增。 同時每行數據還有一個回滾指針(roll_pointer),如下圖所示,每當用戶對索引進行更新之后,舊的數據就會被存放到undo log中,新的數據的回滾指針指向這條最新的舊數據(就是剛剛存到undo log中的數據,通俗的說是最新的垃圾),用于后續可能需要的回滾操作:
3. readView概念掃盲
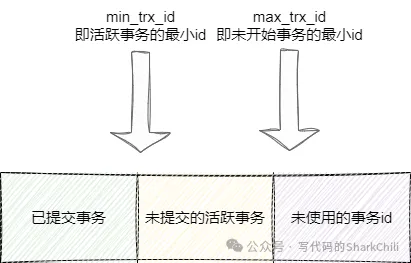
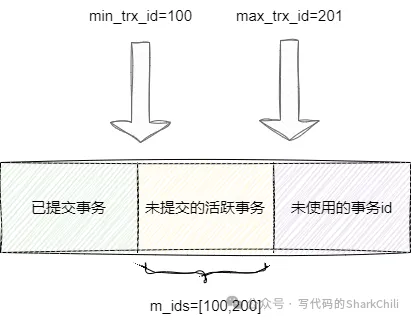
接下來就說說readView,readView就是真正用到undo log的東西,如下圖所示,它由三個部分組成,分別是:
- 已提交事務:已提交事務中記錄的則是已經被提交的事務id集合。
- 活躍事務:這個則記錄那些還能活動且還沒被提交的事務,其中min_trx_id指向活躍事務的最小值。
- 未開始事務:這里面則是存放待使用的事務id值,其中max_trx_id就是記錄這一塊的最小值。
4. 基于可重復讀版本理解SQL的MVCC工作機制
了解了undo.log和readView,我們就可以了解mvcc的工作機制了。就先以可重復讀RR為例,我們來了解一下如何結合undo.log和readView實現可重復讀的。
可重復讀這個級別的readView只會在事務剛剛開始時創建,這也就意味著后續數據無論怎么變化,readView都以第一次創建的為主:
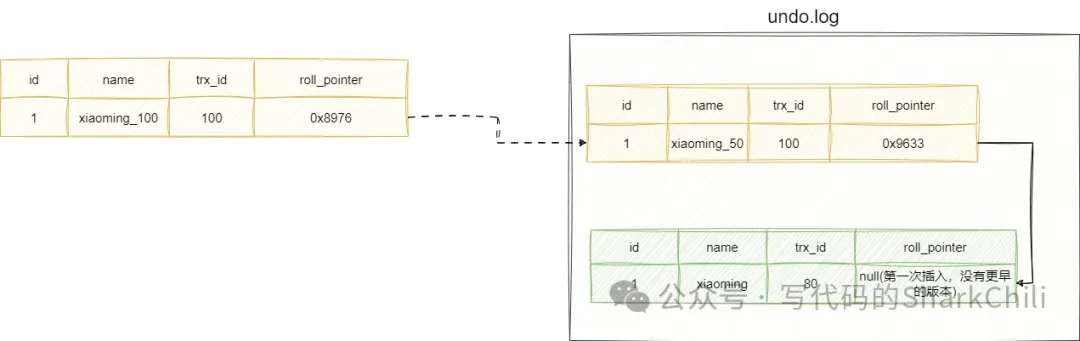
假設我們現在account表數據存在一條id為1的數據xiaoming,然后事務trx_id為100的事務基于RR級別將name先更新為xiaoming_50然后再更新為xiaoming_100,但是事務還沒提交,此時對應的版本鏈如下所示:
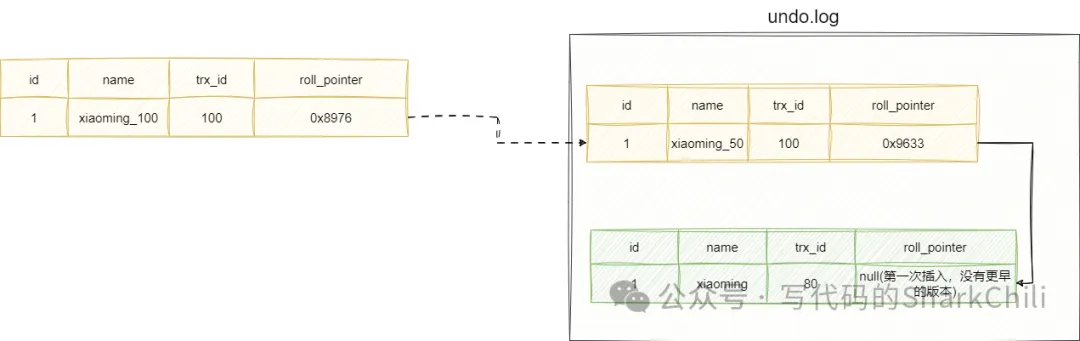
需要注意的是,只有進行SQL修改操作即insert、update、delete才會分配一個事務id,所以我們本在進行查詢之前執行一些無關緊要的update操作,生成一個事務200開始查詢執行下面這條sql查詢,即查詢id為1的數據:
-- 執行一些無關緊要的update
select * from account1 a where id=1;然后事務啟動創建readView,結合版本鏈記錄來看,活躍但是未提交事務值為100,即min_trx_id為100,而我們的事務為200,這也就意味著max_trx_id為201,由此可得活躍的讀寫事務m_ids列表有100、200之間。
所以事務200生成readView如下,然后順著版本鏈開始獲取數據首先看到xiaoming_100事務id為100處于活躍事務列表不符合要求繼續順著指針往下走,看到xiaoming_50也不符合要求,繼續順著指針往下走,看到xiaoming事務id值為80小于min_trx_id即已提交的事務中的值,所以我們事務200查詢結果就是xiaoming:
此時事務100將更新結果提交,因為可重復讀生成readView永遠是以第一次創建時候為主,這也就意味著查詢的思路還是和上述步驟一樣,查詢結果仍然是xiaoming,這里就不多做贅述了。
5. 基于讀已提交版本readView理解SQL的MVCC工作機制
讀已提交版本會在每次執行查詢時生成一個readView,我們還是以上面的例子進行演示,還是事務100觸發修改但是還沒提交,對應生成的版本鏈如下:
還是同理,執行一些無關緊要的修改操作生成本次的事務id為200然后開始查詢,因為事務100沒有提交,所以活躍的事務列表數據為100、200生成readView如下:
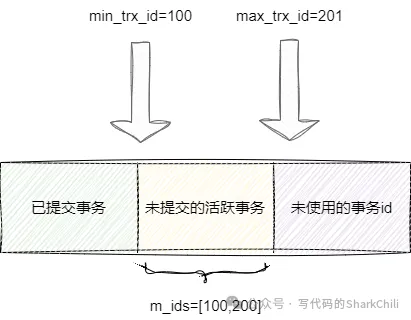
所以順著版本鏈查詢到結果也是小于min_trx_id最大值為80,最終查詢結果為xiaoming。
然后事務100將結果提交,此時我們的事務200再次進行查詢,由讀已提交生成readView為每次查詢時可得,事務100已提交所以該事務處于已提交事務范圍,然后我們的事務200還未提交,所以處于活躍事務列表中,所以活躍事務列表只有我們的事務200:
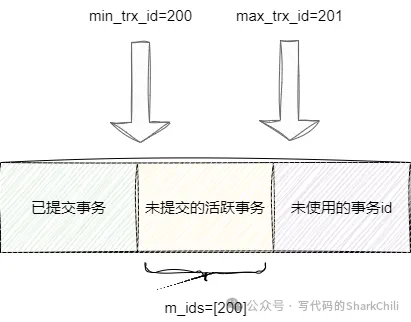
由此順著版本鏈定位到小于min_trx_id的最大值為100,順著版本鏈定位到的第一個trx_id為100的結果是xiaoming_100,所以事務200查詢結果就是xiaoming_100。
6. MySQL 的隔離級別是基于鎖實現的嗎
是基于鎖和mvcc共同實現的,SERIALIZABLE 這個隔離級別就是基于鎖實現的,其他隔離級別都是基于mvcc,需要補充的是REPEATABLE-READ 如果使用當前讀也是基于鎖實現。
7. MySQL 的默認隔離級別是什么
以筆者使用的MySQL8來說使用如下命令可以看到默認級別為可重復讀:
select @@transaction_isolation;對應輸出結果如下:
@@transaction_isolation|
-----------------------+
REPEATABLE-READ |四、小結
MySQL 的 MVCC(多版本并發控制)是其實現高效并發處理的關鍵機制。
通過 MVCC,在并發讀寫操作時,讀操作不會阻塞寫操作,寫操作也不會阻塞讀操作,極大地提高了數據庫的并發性和性能。
它允許事務讀取到特定版本的數據,實現了事務隔離級別的靈活控制。使得不同的事務可以看到符合其隔離級別要求的數據視圖。
在 MVCC 中,每行數據都有多個版本,記錄了不同事務對其的修改歷史。這種方式有效地避免了鎖競爭帶來的性能開銷和潛在的死鎖問題。
對于理解和優化數據庫的并發操作,MVCC 是一個至關重要的概念。深入研究和掌握它,有助于更好地設計和管理數據庫系統,確保數據的一致性和高效性。