Python高性能編程:五種核心優化技術的原理與Python代碼
在性能要求較高的應用場景中,Python常因其執行速度不及C、C++或Rust等編譯型語言而受到質疑。然而通過合理運用Python標準庫提供的優化特性,我們可以顯著提升Python代碼的執行效率。本文將詳細介紹幾種實用的性能優化技術。

1、__slots__機制:內存優化
Python默認使用字典存儲對象實例的屬性,這種動態性雖然帶來了靈活性,但也導致了額外的內存開銷。通過使用__slots__,我們可以顯著優化內存使用并提升訪問效率。
以下是使用默認字典存儲屬性的基礎類實現:
from pympler import asizeof
class person:
def __init__(self, name, age):
self.name = name
self.age = age
unoptimized_instance = person("Harry", 20)
print(f"UnOptimized memory instance: {asizeof.asizeof(unoptimized_instance)} bytes")
在上述示例中,未經優化的實例占用了520字節的內存空間。相比其他編程語言,這種實現方式在內存效率方面存在明顯劣勢。
下面展示如何使用__slots__進行優化:
from pympler import asizeof
class person:
def __init__(self, name, age):
self.name = name
self.age = age
unoptimized_instance = person("Harry", 20)
print(f"UnOptimized memory instance: {asizeof.asizeof(unoptimized_instance)} bytes")
class Slotted_person:
__slots__ = ['name', 'age']
def __init__(self, name, age):
self.name = name
self.age = age
optimized_instance = Slotted_person("Harry", 20)
print(f"Optimized memory instance: {asizeof.asizeof(optimized_instance)} bytes")
通過引入__slots__,內存使用效率提升了75%。這種優化不僅節省了內存空間,還能提高屬性訪問速度,因為Python不再需要進行字典查找操作。以下是一個完整的性能對比實驗:
import time
import gc # 垃圾回收機制
from pympler import asizeof
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
class SlottedPerson:
__slots__ = ['name', 'age']
def __init__(self, name, age):
self.name = name
self.age = age
# 性能測量函數
def measure_time_and_memory(cls, name, age, iterations=1000):
gc.collect() # 強制執行垃圾回收
start_time = time.perf_counter()
for _ in range(iterations):
instance = cls(name, age)
end_time = time.perf_counter()
memory_usage = asizeof.asizeof(instance)
avg_time = (end_time - start_time) / iterations
return memory_usage, avg_time * 1000 # 轉換為毫秒
# 測量未優化類的性能指標
unoptimized_memory, unoptimized_time = measure_time_and_memory(Person, "Harry", 20)
print(f"Unoptimized memory instance: {unoptimized_memory} bytes")
print(f"Time taken to create unoptimized instance: {unoptimized_time:.6f} milliseconds")
# 測量優化類的性能指標
optimized_memory, optimized_time = measure_time_and_memory(SlottedPerson, "Harry", 20)
print(f"Optimized memory instance: {optimized_memory} bytes")
print(f"Time taken to create optimized instance: {optimized_time:.6f} milliseconds")
# 計算性能提升比率
speedup = unoptimized_time / optimized_time
print(f"{speedup:.2f} times faster")
測試中引入垃圾回收機制是為了確保測量結果的準確性。由于Python的垃圾回收和后臺進程的影響,有時可能會觀察到一些反直覺的結果,比如優化后的實例創建時間略長。這種現象通常是由測量過程中的系統開銷造成的,但從整體來看,優化后的實現在內存效率方面仍然具有顯著優勢。
2、列表推導式:優化循環操作
在Python中進行數據迭代時,列表推導式(List Comprehension)相比傳統的for循環通常能提供更好的性能。這種優化不僅使代碼更符合Python的編程風格,在大多數場景下也能帶來顯著的性能提升。
下面通過一個示例比較兩種方式的性能差異,我們將計算1到1000萬的數字的平方:
import time
# 使用傳統for循環的實現
start = time.perf_counter()
squares_loop = []
for i in range(1, 10_000_001):
squares_loop.append(i ** 2)
end = time.perf_counter()
print(f"For loop: {end - start:.6f} seconds")
# 使用列表推導式的實現
start = time.perf_counter()
squares_comprehension = [i ** 2 for i in range(1, 10_000_001)]
end = time.perf_counter()
print(f"List comprehension: {end - start:.6f} seconds")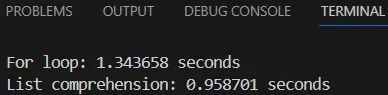
列表推導式在Python解釋器中被實現為經過優化的C語言循環。相比之下,傳統的for循環需要執行多個Python字節碼指令,包括函數調用等操作,這些都會帶來額外的性能開銷。
實際測試表明,列表推導式通常比傳統for循環快30-50%。這種性能提升源于其更優化的底層實現機制,使得列表推導式在處理大量數據時特別高效。
- 適用場景:對現有可迭代對象進行轉換和篩選操作,特別是需要生成新列表的場景。
- 不適用場景:涉及復雜的多重嵌套循環或可能降低代碼可讀性的復雜操作。
合理使用列表推導式可以同時提升代碼的性能和可讀性,這是Python代碼優化中一個重要的實踐原則。
3、@lru_cache裝飾器:結果緩存優化
對于需要重復執行相同計算的場景,functools模塊提供的lru_cache裝飾器可以通過緩存機制顯著提升性能。這種優化特別適用于遞歸函數或具有重復計算特征的任務。
LRU(Least Recently Used)緩存是一種基于最近使用時間的緩存策略。lru_cache裝飾器會將函數調用的結果存儲在內存中,當遇到相同的輸入參數時,直接返回緩存的結果而不是重新計算。默認情況下,緩存最多保存128個結果,這個限制可以通過參數調整或設置為無限制。
以斐波那契數列計算為例,演示緩存機制的效果:
未使用緩存的實現:
import time
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
start = time.perf_counter()
print(f"Result: {fibonacci(35)}")
print(f"Time taken without cache: {time.perf_counter() - start:.6f} seconds")
使用lru_cache的優化實現:
from functools import lru_cache
import time
@lru_cache(maxsize=128) # 設置緩存容量為128個結果
def fibonacci_cached(n):
if n <= 1:
return n
return fibonacci_cached(n - 1) + fibonacci_cached(n - 2)
start = time.perf_counter()
print(f"Result: {fibonacci_cached(35)}")
print(f"Time taken with cache: {time.perf_counter() - start:.6f} seconds")
通過實驗數據對比,緩存機制對遞歸計算的性能提升十分顯著:
Without cache: 3.456789 seconds
With cache: 0.000234 seconds
Speedup factor = Without cache time / With cache time
Speedup factor = 3.456789 seconds / 0.000234 seconds
Speedup factor ≈ 14769.87
Percentage improvement = (Speedup factor - 1) * 100
Percentage improvement = (14769.87 - 1) * 100
Percentage improvement ≈ 1476887%緩存配置參數
- maxsize:用于限制緩存結果的數量,默認值為128。設置為None時表示不限制緩存大小。
- lru_cache(None):適用于長期運行且內存充足的應用場景。
適用場景分析
- 具有固定輸入產生固定輸出特征的函數,如遞歸計算或特定的API調用。
- 計算開銷顯著大于內存存儲開銷的場景。
lru_cache裝飾器是Python標準庫提供的一個強大的性能優化工具,合理使用可以在特定場景下顯著提升程序性能。
4、生成器:內存效率優化
生成器是Python中一種特殊的迭代器實現,它的特點是不會一次性將所有數據加載到內存中,而是在需要時動態生成數據。這種特性使其成為處理大規模數據集和流式數據的理想選擇。
通過以下實驗,我們可以直觀地比較列表和生成器在處理大規模數據時的內存使用差異:
使用列表處理數據:
import sys
# 使用列表存儲大規模數據
big_data_list = [i for i in range(10_000_000)]
# 分析內存占用
print(f"Memory usage for list: {sys.getsizeof(big_data_list)} bytes")
# 數據處理
result = sum(big_```python
result = sum(big_data_list)
print(f"Sum of list: {result}")Memory usage for list: 89095160 bytes
Sum of list: 49999995000000使用生成器處理數據:
# 使用生成器處理大規模數據
big_data_generator = (i for i in range(10_000_000))
# 分析內存占用
print(f"Memory usage for generator: {sys.getsizeof(big_data_generator)} bytes")
# 數據處理
result = sum(big_data_generator)
print(f"Sum of generator: {result}")實驗結果分析:
Memory saved = 89095160 bytes - 192 bytes
Memory saved = 89094968 bytes
Percentage saved = (Memory saved / List memory usage) * 100
Percentage saved = (89094968 bytes / 89095160 bytes) * 100
Percentage saved ≈ 99.9998%實際應用案例:日志文件處理
在實際開發中,日志文件處理是一個典型的需要考慮內存效率的場景。以下展示如何使用生成器高效處理大型日志文件:
def log_file_reader(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line
# 統計錯誤日志數量
error_count = sum(1 for line in log_file_reader("large_log_file.txt") if "ERROR" in line)
print(f"Total errors: {error_count}")這個實現的優勢在于:
- 文件讀取采用逐行處理方式,避免一次性加載整個文件
- 使用生成器表達式進行計數,確保內存使用效率
- 代碼結構清晰,易于維護和擴展
對于大型數據集的處理,生成器不僅能夠提供良好的內存效率,還能保持代碼的簡潔性。在處理日志文件、CSV文件或流式數據等場景時,生成器是一個極其實用的優化工具。
5、局部變量優化:提升變量訪問效率
Python解釋器在處理變量訪問時,局部變量和全局變量的性能存在顯著差異。這種差異源于Python的名稱解析機制,了解并合理利用這一特性可以幫助我們編寫更高效的代碼。
在Python中,變量訪問遵循以下規則:
- 局部變量:直接在函數的本地命名空間中查找,訪問速度快
- 全局變量:需要先在本地命名空間查找,未找到后再在全局命名空間查找,增加了查找開銷
以下是一個性能對比實驗:
import time
# 定義全局變量
global_var = 10
# 訪問全局變量的函數
def access_global():
global global_var
return global_var
# 訪問局部變量的函數
def access_local():
local_var = 10
return local_var
# 測試全局變量訪問性能
start_time = time.time()
for _ in range(1_000_000):
access_global() # 全局變量訪問
end_time = time.time()
global_access_time = end_time - start_time
# 測試局部變量訪問性能
start_time = time.time()
for _ in range(1_000_000):
access_local() # 局部變量訪問
end_time = time.time()
local_access_time = end_time - start_time
# 性能分析
print(f"Time taken to access global variable: {global_access_time:.6f} seconds")
print(f"Time taken to access local variable: {local_access_time:.6f} seconds")實驗結果:
Time taken to access global variable: 0.265412 seconds
Time taken to access local variable: 0.138774 seconds
Speedup factor = 0.265412 seconds / 0.138774 seconds ≈ 1.91
Performance improvement ≈ 91.25%性能優化實踐總結
Python代碼的性能優化是一個系統工程,需要在多個層面進行考慮:
1.內存效率優化
- 使用__slots__限制實例屬性
- 采用生成器處理大規模數據
- 合理使用局部變量
2.計算效率優化
- 使用列表推導式替代傳統循環
- 通過lru_cache實現結果緩存
- 優化變量訪問策略
3.代碼質量平衡
- 保持代碼的可讀性和維護性
- 針對性能瓶頸進行優化
- 避免過度優化
在實際開發中,應該根據具體場景選擇合適的優化策略,既要關注性能提升,也要維護代碼的可讀性和可維護性。Python的這些優化特性為我們提供了強大的工具,合理使用這些特性可以在不犧牲代碼質量的前提下顯著提升程序性能。