Linux高性能編程-malloc原理
大家好,這里是物聯網心球。
談到高性能編程,我們繞不過一個問題高效內存分配,通常我們會使用malloc和free函數來申請和釋放內存。
那么我們習以為常的malloc和free函數,真的能滿足高性能編程的要求嗎?
帶著這個問題我們來深入理解malloc和free函數實現原理。
1.ptmalloc工作原理
malloc和free函數屬于glibc庫的ptmalloc模塊,我們得通過學習glibc源碼了解ptmalloc工作原理。源碼位置:glibc/malloc/malloc.c。
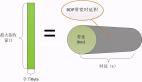
1.1 ptmalloc軟件架構
 圖片
圖片
ptmalloc內存池是一個比較復雜的軟件模塊,會涉及到malloc_state,malloc_chunk,mmap,brk等概念。
ptmalloc通過brk(堆內存)或者mmap(內存映射)系統調用從內核申請一大塊連續的內存,申請的內存由top chunk管理,用戶程序調用malloc函數從內存池申請內存(chunk),如果內存池有空閑的chunk,則從空閑的chunk返回給用戶程序,如果沒有空閑的chunk,則從top chunk裁剪出可用的chunk返回給用戶程序。
用戶程序調用free函數將會釋放chunk至空閑鏈表或top chunk。
我們將圍繞兩個比較重要的概念來進行講解:malloc_state和malloc_trunk。
1) malloc_state
ptmalloc由struct malloc_state統一管理,定義如下:
struct malloc_state
{
__libc_lock_define (, mutex); //互斥鎖
int flags; //標志
mfastbinptr fastbinsY[NFASTBINS]; //fastbins
mchunkptr top; //top chunk
mchunkptr bins[NBINS * 2 - 2]; //unsortedbins,smallbins,largebins
unsigned int binmap[BINMAPSIZE]; //bin位圖
struct malloc_state *next; //鏈表指針
......
};malloc_state有幾個重要成員:fastbinsY,top,bins,binmaps,next。
- fastbinsY數組:fastbins,用于存儲16-160字節chunk的空閑鏈表。
- bins數組:bins分為三個部分:unsortedbins,smallbins,largebins:
unsortedbins:chunk緩存區,用于存儲從fastbins合并的空閑chunk。
smallbins:空閑鏈表,用于存儲32-1024字節的chunk。
largebins:空閑鏈表,用于存儲大于1024字節的chunk。
- top chunk:超級chunk,ptmalloc內存池。
- binmap:可用bins位圖,用于快速查找可用bin。
- next:單向鏈表指針,用于連接不同的malloc_state。
進程通常會有多個malloc_state,進程啟動時,由主線程創建第一個malloc_state稱為主分配區(main_state),主分配區的內存通過brk(堆)或者malloc(內存映射)從內核申請而來,這也解釋了為什么malloc可以從堆區分配內存。
如果程序所有的線程都使用主分配區分配內存,那么多線程會存在競爭關系,為了解決這個問題,進程會根據實際情況動態創建非主分配區(thread_state),thread_state分配區內存池內存只能通過mmap從內核申請,當主分配區被使用或者沒有可用的分配區時,系統會創建一個新的分配區,這樣可以減少多線程競爭,提高內存分配效率。
當然malloc_state數量并不是沒有限制,通常malloc_state數量最多為CPU核心數的數倍,超過該閾值后將不能再創建新的分配區。如果一個程序線程數量太多,會加劇對分配區的競爭。
 圖片
圖片
2)malloc_chunk
ptmalloc以malloc_chunk為單位申請和釋放內存,struct malloc_chunk定義如下:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; //前一個chunk大小
INTERNAL_SIZE_T mchunk_size; //當前chunk大小,后三位為A,M,P
struct malloc_chunk* fd; //鏈表后驅指針
struct malloc_chunk* bk; //鏈表前驅指針
struct malloc_chunk* fd_nextsize; //largebins后驅指針
struct malloc_chunk* bk_nextsize; //largebins前驅指針
};chunk是ptmalloc最難理解的一個概念,只有理解了chunk才能真正理解ptmalloc。
 圖片
圖片
chunk是從內存池裁剪下來的內存塊,這個內存塊由malloc_chunk管理。
malloc_chunk對象mchunk_prev_size和mchunk_size成員為chunk頭部,chunk頭部將會伴隨chunk整個生命周期,用于記錄和識別chunk。
內存塊除了chunk頭部外就是內存區域,當chunk分配給用戶程序后,內存區域用于存儲用戶數據,如果chunk處于空閑狀態,將會借用內存區域前16個字節作為鏈表指針,將chunk插入空閑鏈表。
3)fastbins數組
 圖片
圖片
fastbins數組長度為10,每個數組元素都是一個chunk鏈表頭,10個鏈表分別存儲16-160字節的chunk,步長為16字節,malloc函數申請小于160字節的內存時,從fastbins空閑鏈表查找匹配的chunk進行分配。
4)bins數組
 圖片
圖片
bins數組長度為128,可以分為三部分:unsortedbins,smallbins,largebins。
unsortedbins:bins數組0號元素,unsortedbins是一個特殊的鏈表,該鏈表是一個chunk緩存區,用于存儲從fastbins合并的空閑chunk,目的是為了回收小塊內存,解決內存碎片問題。
smallbins:bins數組1-63號元素,和fastbins功能一樣,smallbins用于存儲32-1008字節的空閑chunk。
largebins:bins數組64-127號元素,用于存儲超過1024字節大小的空閑chunk。
5)top chunk
top chunk可以理解為超級chunk,當bins空閑鏈表中沒有匹配的chunk分配給用戶程序時,top chunk將會被裁剪,裁剪成用戶chunk和剩余chunk,用戶chunk分配給用戶程序,剩余chunk繼續由top chunk管理。
如果top chunk內存不足,調用brk或者mmap從內核申請內存對top chunk擴容,并將擴容后的內存塊裁剪分配給用戶程序。
1.2 malloc函數流程分析
 圖片
圖片
用戶程序調用malloc函數申請內存時,首先會去查詢空閑鏈表,如果空閑鏈表沒有足夠的chunk,則去查詢top chunk進行內存分配。
如果top chunk沒有足夠的內存,說明內存池內存不足,需要通過brk或者mmap擴容。
注意:內存池內存不夠,并不一定表示內存都被用完,也有可能是存在內存碎片。
1.3 free函數流程分析
 圖片
圖片
用戶程序調用free函數釋放內存,優先將內存釋放至空閑鏈表,如果釋放至空閑鏈表失敗,則釋放至top chunk,如果釋放的內存比較大,可能通過munmap或者brk回收至內核。
2.ptmalloc高并發測試
前一小節,我們花了比較多的精力去學習ptmalloc實現原理,對于很多項目來說,我們不需要花過多時間去研究ptmalloc實現原理,直接使用malloc和free函數即可,然而對于高并發項目,我們得深入理解ptmalloc實現原理,從而清楚地知道ptmalloc存在的問題,為后續優化打好基礎。
2.1 ptmalloc常見問題
通過學習ptmalloc實現原理,我們會發現ptmalloc存在兩個問題:鎖競爭問題和內存碎片問題。
- 鎖競爭問題
struct malloc_state結構定義了一個mutex成員,多線程想要通過分配區進行內存分配時需要加鎖,頻繁分配內存會導致頻繁加鎖。 - 內存碎片問題
 圖片
圖片
ptmalloc通過mmap或brk從內核申請一大塊連續的內存,調用malloc函數會將這塊大的內存裁剪成一塊塊小的內存,如果其中某些小的內存塊一直不釋放至內存池,將導致小的內存塊無法合并成大的內存塊,造成內存碎片,嚴重的情況會導致內存泄露,程序退出。
2.2 ptmalloc高并發測試
1)測試代碼
采用多個線程循環申請和釋放內存,每次隨機申請SIZE_THREHOLD范圍大小內存,如果申請的內存小于LEAK_THREHOLD大小,則申請的內存不釋放,人為制造內存泄露,并實時統計泄露內存總量。
測試項:頻繁加鎖測試,內存碎片測試。
- 頻繁加鎖測試方法:
通過:strace -tt -f -e trace=futex ./a.out命令執行測試程序,觀察是否調用futex系統調用加鎖。
- 內存碎片測試
通過:strace -tt -f -e trace=mprotect,brk ./a.out命令執行測試程序,觀察是否調用mprotect或者brk進行擴容。
統計程序已使用內存總量,內存泄露總量,計算內存碎片總量:
內存碎片總量=已使用內存總量-內存泄露總量。
測試代碼如下:
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
#include <pthread.h>
#include <stdatomic.h>
#define THREAD_NUM (8) //測試線程數量
#define SIZE_THREHOLD (1024) //申請內存閾值,每次申請的內存大小小于該閾值
#define LEAK_THREHOLD (64) //泄露內存閾值, 0:關閉內存泄露,大于0:每次泄露內存的不超過該閾值
atomic_int leak_size; //內存泄露統計值
int get_size() {
srand(time(0));
return rand() % SIZE_THREHOLD;
}
void *do_malloc(void *arg) {
while(1) {
int size = get_size();
//printf("size:%d\n", size);
char *p = malloc(size);
if (size >= LEAK_THREHOLD) {
free(p);
} else {
atomic_fetch_add(&leak_size, size); //統計泄露內存大小
printf("leak size:%d KB\n", leak_size / 1024);
}
}
return NULL;
}
int main(int argc, char *argv[]) {
atomic_init(&leak_size, 0);
pthread_t th[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; i++) {
pthread_create(&th[i], NULL, do_malloc, NULL);
}
do_malloc(NULL);
for (int i = 0; i < THREAD_NUM; i++) {
pthread_join(th[i], NULL);
}
return 0;
}2)測試結果
- 頻繁加鎖測試
通過strace -tt -f -e trace=futex ./a.out命令觀察到測試程序頻繁的調用futex系統調用,為了保證線程安全,malloc和free函數需要頻繁加鎖,頻繁加鎖會影響內存分配的效率。

- 內存碎片測試
1.程序剛啟動時,內存泄露總量為1.8MB,此時系統可用內存總量為2724MB。
 圖片
圖片
 圖片
圖片
2. 程序泄露內存總量至162MB時,此時系統可用內存總量為2474MB。
 圖片
圖片
 圖片
圖片
用戶程序使用內存總量為:2724 - 2474 = 250MB。泄露內存總量為162MB,內存碎片總量為88MB。
通過strace -tt -f -e trace=mprotect,brk ./a.out命令觀察到,ptmalloc頻繁的通過mprotect或者brk進行擴容。
 圖片
圖片
3.總結
- malloc和free函數不適用于多線程申請和釋放內存使用場景,存在頻繁加鎖的問題。
- malloc和free函數不適用于長期占用內存的使用場景,長期占用內存會導致內存碎片問題。
- 對并發要求不高的場景可以使用malloc和free函數,高并發場景需要使用更高效的內存池。