













讓大模型互聯網「沖浪」,通義實驗室WebWalker解鎖復雜信息檢索新技能
本文主要作者來自通義實驗室和東南大學,通訊作者是通義實驗室蔣勇和東南大學周德宇。其中第一作者吳家隆,東南大學碩士二年級,主要研究方向是 Agent 和 Efficient NLP,該工作在阿里巴巴通義實驗室 RAG 團隊科研實習完成。
在信息爆炸的時代,互聯網就像一座龐大的迷宮,藏著無數寶藏。但傳統搜索引擎往往只能觸及表面,對于復雜、多層級的信息檢索顯得力不從心。比如,你想知道某個學術會議的詳細議程、嘉賓介紹,還得自己手動點開一個個網頁點擊深挖,費時費力。
通義實驗室 RAG 團隊提出 WebWalker 幫你解決這一問題!
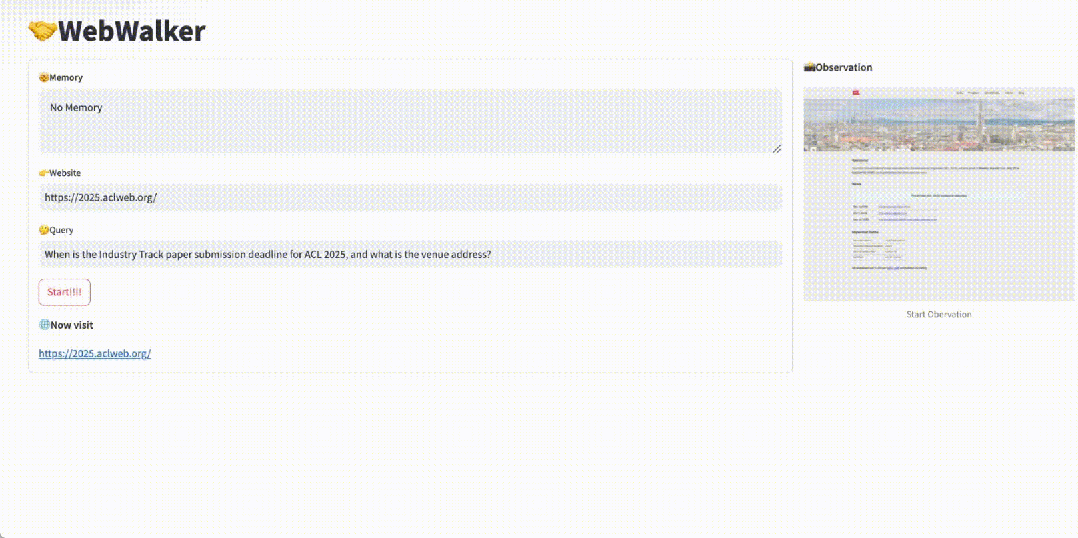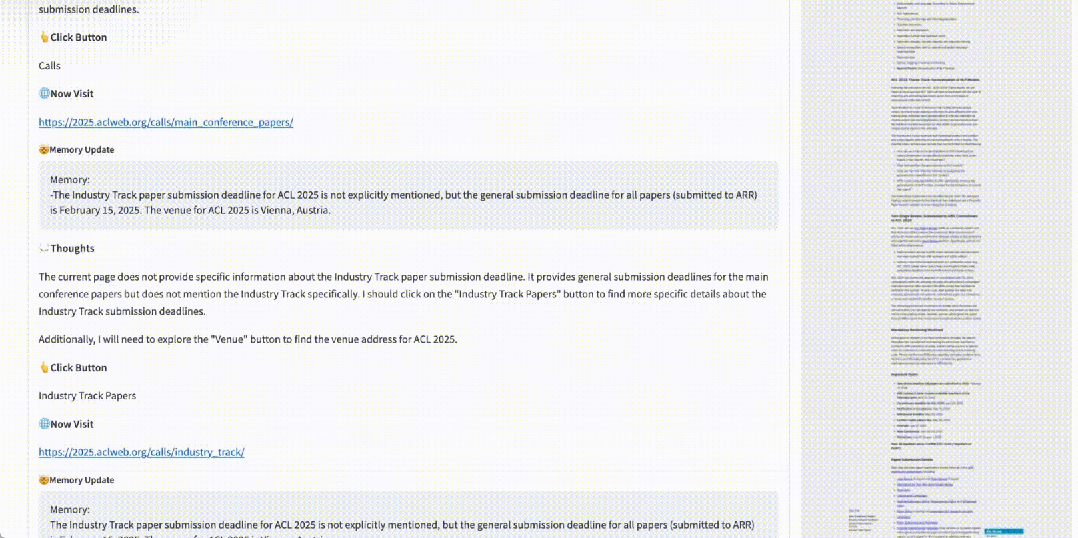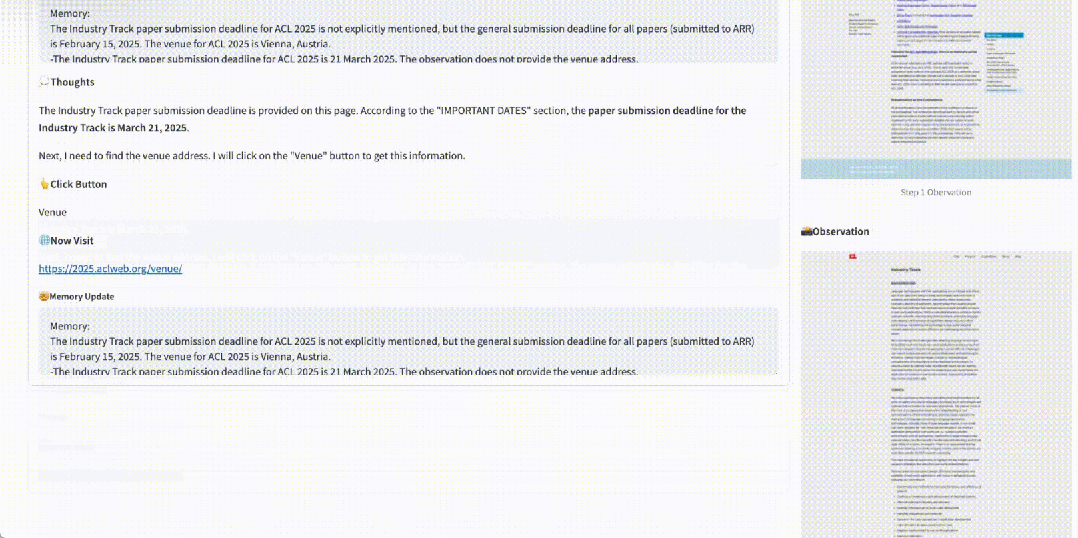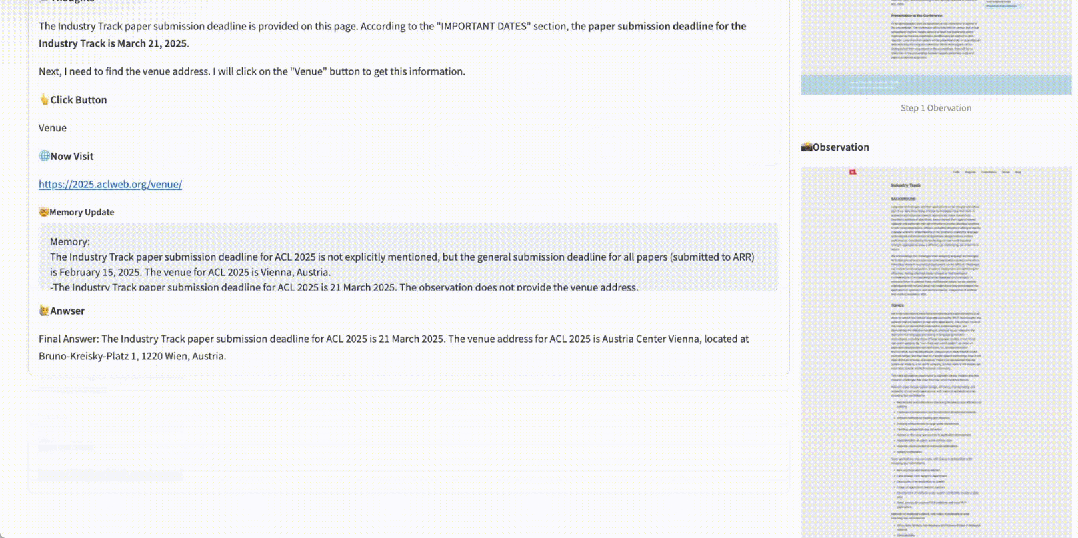
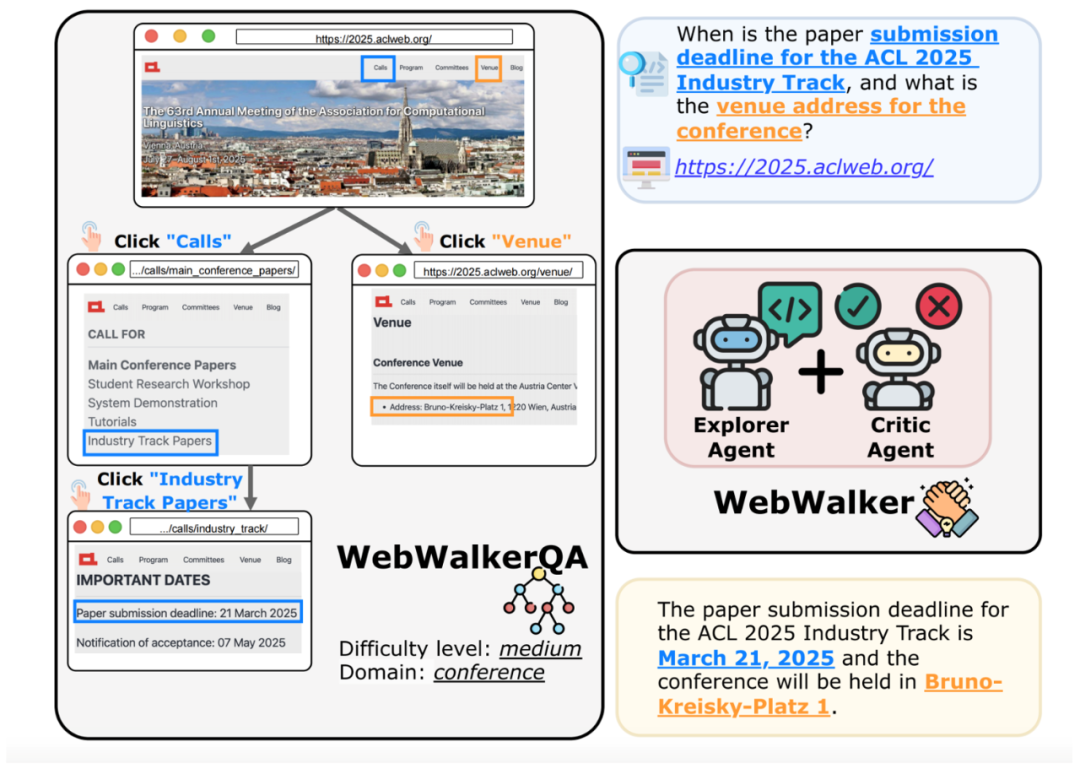
如 gif 所示,給定 ACL 2025 的網頁地址和問題:industry track 的截止日期和開會地址。WebWalker 通過一次又一次的 Click 點擊依次找到對應的信息,對網站進行充分的探索和挖掘。
就其應用場景來說,WebWalker 既可以作為獨立的網頁信息檢索助手,或無縫集成到 RAG 系統中,拓展其應用范圍,讓它們能夠處理更加復雜、多步驟的信息檢索任務。

- 論文標題:WebWalker: Benchmarking LLMs in Web Traversal
- 論文地址:https://arxiv.org/pdf/2501.07572
- Homepage 地址:
https://alibaba-nlp.github.io/WebWalker/ - Modelscope Demo 地址:
https://www.modelscope.cn/studios/jialongwu/WebWalker - Huggingface Demo 地址:
https://huggingface.co/spaces/callanwu/WebWalker - Dataset 地址:
https://huggingface.co/datasets/callanwu/WebWalkerQA - Leaderboard 地址: https://huggingface.co/spaces/callanwu/WebWalkerQALeadeboard
- Github 地址:
https://github.com/Alibaba-NLP/WebWalker
背景:大模型的「知識局限」與檢索瓶頸
大型語言模型(LLMs)在自然語言處理任務中大放異彩,但它們的「知識」 在訓練后就固定了。雖然通過檢索增強生成(RAG)能從網上獲取最新信息,傳統搜索引擎的橫向搜索方式,很難深入挖掘網站內部深層內容,導致大模型在處理復雜信息時「心有余而力不足」。
傳統搜索引擎如谷歌、必應等,它們的搜索方式,我們定義為對問題水平方向的搜索,難以深入到網站內部,挖掘那些深埋在網頁之下的深層內容,對于隱藏在網頁深層的有價值信息無能為力。無法像人類一樣通過點擊、輸入等操作,逐步深入探索網頁,獲取豐富的細節。
解決思路
研究者首先定義了 Web Traversal 任務,即給定一個與問題相關的初始網站,系統地遍歷網頁以揭露隱藏在其中的信息對問題進行回答。同時,WebWalkerQA 應運而生,專門設計來評估大模型處理復雜、多步驟網頁交互中嵌入查詢能力的基準測試。其聚焦于文本推理能力,采用問答格式來評估大模型在網頁場景中的問題解決能力,并且將動作限制為「Click 點擊」,以更精準地評估智能體的導航和信息尋求能力,這種范式更加貼合實際應用場景。
同時,研究者提出了一個基于 Multi-Agent 框架搭建的 WebWalker 框架,進行網頁的游走,獲取需要的信息。
WebWalkerQA 基準
WebWalkerQA 通過兩階段漏斗式標注策略構建數據,先用 GPT-4o 進行初步標注,再由眾包標注者進行質量控制和篩選,最終獲得高質量的 680 個問答對,覆蓋 1373 個網頁,其中涉及到的領域有教育、會議、組織和游戲,貼近現實真實場景,并且分為多源和單源問答兩種類型,模擬人類不同網頁探索行為。
同時,團隊了開源了 14k 條 silver data,包含了詳細的頁面點擊的 trajectory,以供后續研究者研究使用。
WebWalker 框架
WebWalker 框架由 Explorer Agent 和 Critic Agent 組成。Explorer Agent 基于遵循思考 - 行動 - 觀察范式,負責在網頁中點擊按鈕、跳轉頁面;Critic Agent 則負責記憶,維護一個 Memory 來保存對問題回答有幫助的信息和判斷當前 Memory 中的信息能否對問題進行回答。
這種分工協作讓大模型更高效地管理記憶,應對長文本和復雜邏輯。WebWalker 讓大模型在網頁導航任務中能夠更加高效地處理長文本信息,深入網頁挖掘有價值的內容。

實驗結果
研究者分別在兩種設置下測試了 WebWalkerQA 的性能。第一種是 Agent 在 Web Traversal 任務下的性能,即輸入給定的網頁和問題,讓 Agent 在網頁內游走,獲取信息進行回答。
另外,研究者分別在兩種最主流的 Single-Agent 框架 ReAct 和 Reflexion 以及他們提出的 WebWalker 上進行了測試。測試指標分別是問答的正確率和正確回答的情況下 Agent 執行點擊的次數 Action Count。
在 Agent 上的性能
從下圖可以看出,數據集深度越深,考察內容越多,需要挖掘的信息越難找到,性能越低,這與論文構造 WebWalkerQA 想要考察的內容是一致的。
相比于 ReAct 和 Reflexion 框架,引入 Multi-Agent 的 WebWalker 框架對于長上下文理解的網頁探索任務很有作用。
總體來說,WebWalkerQA 對現有 Agent 來說是仍有挑戰,即使是性能最強的基于 GPT-4o 的 WebWalker,其表現也未達理想狀態,僅僅只有 40,凸顯了該基準的難度。

詳細分析
如下左圖是基于不同基座 LLM 在不同 Agent 正確率和執行次數的分布;右圖是預測分布,研究者對錯誤類型進行了細致的劃分,包括超過給定的最大執行次數 K,拒答或定位錯誤(沒有找到正確的頁面就進行了回答)以及推理錯誤(這里指找到了正確的頁面但是仍回答錯誤)。
綜合來看,在 ReAct 框架下,參數相對較小的模型由于缺乏深入挖掘信息的能力,無論是否找到了相關信息,在進行幾次操作迭代后便開始進行回答判斷,常常表現出「擺爛」或者不耐煩的特性。通過引入記憶機制來管理長上下文,或者隨著模型參數的增強這種現象有所緩解,說明這種現象源于長上下文中噪聲信息的干擾以及模型自身能力的局限性。

在 RAG 系統上的性能
另一種設置是直接端到端測試 RAG 系統下 QA 的性能,研究者分別測試了在 Close Book 和一些開源、商用 RAG 系統上的性能。結果顯示,Close Book 在 WebWalkerQA 上結果很差,因為研究者收集頁面信息具有高度的時效性。
同樣地,WebWalkerQA 需要搜索引擎搜到比較深的頁面內容,或者需要拆解 Query 進行搜索,這給 RAG 系統帶來了挑戰,最好的結果也是 40 左右。

二維 RAG 的探索
值得注意的是,WebWalker 中的 memory 對于回答 query 是非常重要的。如果 rag 鏈路中的搜索引擎可以當作對 query 進行橫向搜索,WebWalker 是對頁面的縱向深度探索,這是完全可以互補的。
因此,如果把 WebWalker 中的 memory 拼接到 rag 鏈路上,這種橫向和縱向整合表現出色,在所有類別和難度的數據集上效果均有提升,證明了垂直探索頁面對于提升 RAG 性能的潛力。這是對 RAG 二維探索的首次嘗試!
此外,研究者對 WebWalker 的挖掘點擊次數進行 scale up,看是否能得到更好、更多的 memory 信息。隨著挖掘點擊次數的增大,不僅在 WebWalker 上有較大提升,把 memory 加入到 rag 系統之后,性能也隨之提升。這給 rag 系統進行 test-time 的拓展提供了新的角度。

突出 Insight
- 網頁導航尋找信息仍比較困難:在需要規劃和推理的任務中,網頁導航任務仍需進行進一步的研究和探索。
- 結合 RAG 有效:RAG 與 WebWalker 的結合,在信息檢索問答任務中展現出強大效果。這種協同作用不僅提升了信息檢索的效率,還為處理復雜任務提供了強大的支持。Agentic 的二維 RAG 會很有幫助。
- 垂直探索有潛力:頁面的垂直探索為 RAG 系統 test-time 的擴展提供了新思路。突破迭代搜索的范式,對頁面進行垂直探索。
總之,WebWalkerQA 和 WebWalker 的出現,為大模型在復雜、多步驟信息檢索任務中的網頁遍歷能力評估提供了新標準和工具。它們強調了網頁信息獲取任務中深度、垂直探索的重要性,是可能一直 Agentic RAG 的新方向。
局限與改進方向
- 數據規模:目前 WebWalkerQA 僅包含 680 個高質量問答對,規模有限,還有拓展空間。
- 多模態拓展:目前僅基于 HTML-DOM 解析,未來可結合視覺模態如截圖,提供更直觀的交互體驗。
- Agent 微調:WebWalker 目前僅靠提示驅動,后續可通過精細調優,讓大模型更好地掌握網頁瀏覽技巧。
- Momory 與 rag 結合:目前是給定了 webwalker 頁面進行了挖掘,如果想與 rag 鏈路進行更好的結合,可以對 query 進行改寫到官網定位,再進行挖掘,把 memory 和正常檢索到的知識一起作為檢索增強的知識,這樣結合更自然。
















