快手發布DragAnything,拖動錨點精準控制視頻物體和鏡頭運動,視頻運動控制技術革命性更新
快手聯合浙江大學、新加坡國立大學發布了DragAnything ,利用實體表示實現對任何物體的運動控制。該技術可以精確控制物體的運動,包括前景、背景和相機等不同元素。
該項目提供了對實體級別運動控制的新見解,通過實體表示揭示了像素級運動和實體級運動之間的差異。與拖動像素范式不同,
DragAnything能夠使用實體表示實現真正的實體級別運動控制。用戶可以通過繪制軌跡與SAM進行互動。該項目能夠精確控制物體的運動,生成高質量的視頻。用戶軌跡與SAM的交互
論文閱讀

- 基于軌跡的可控生成的新見解揭示了像素級運動和實體級運動之間的差異。
- DragAnything與拖動像素范例不同,它可以通過實體表示實現真正的實體級運動控制。
與DragNUWA的比較
DragNUWA導致第一排外觀失真,第三排失控的天空和船,不正確的鏡頭運動(第五排),而DragAnthing可以精確控制運動。
更多的可視化拖動任何東西
提出的DragAnything可以在實體級精確控制物體的運動,產生高質量的視頻。利用Co-Track實現了第20幀像素運動的可視化。
各種各樣的運動控制
提出的DragAnything可以實現多種運動控制,如控制前景、背景和相機。
Badcase for DragNUWA
當前模型受到基礎模型(穩定視頻擴散)的性能限制,無法生成具有非常大運動的場景。這可能是由于運動過度,超過了基礎模型的生成能力,導致視頻質量崩潰。
摘要
我們提出了DragAnything,它利用實體表示來實現可控視頻生成中任何對象的運動控制。與現有的運動控制方法相比,DragAnything具有幾個優勢。首先,基于軌跡的交互更人性化,當獲取其他指導信號(例如,掩碼、深度圖)是勞動密集型時。用戶只需要在交互過程中畫一條線(軌跡)。其次,我們的實體表示作為一個開放域嵌入,能夠表示任何對象,使包括背景在內的各種實體的運動控制成為可能。最后,我們的實體表示允許對多個對象進行同時和不同的運動控制。廣泛的實驗表明,我們的方法在FVD、FID和用戶研究方面取得了最先進的性能,特別是在對象運動控制方面,我們的方法在人工投票中超過了以前的方法(例如,DragNUWA)26%。
動機

啟示1
物體上的軌跡點不能代表實體。從DragUNWA的像素運動軌跡可以看出,拖動云的像素點并不會導致云移動,相反,它會導致攝像機向上移動。這表明模型無法感知我們控制云的意圖,這意味著單個點不能代表云。
啟示2
對于軌跡點表示范式,靠近拖動點的像素受到的影響更大,導致更大的運動。通過比較,我們觀察到在DragNUWA合成的視頻中,靠近拖動點的像素表現出更大的運動。然而,我們期望的是物體按照提供的軌跡作為一個整體移動,而不是單個像素的運動。

方法
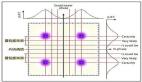
 該體系結構包括兩個部分:
該體系結構包括兩個部分:
- 實體語義表示抽取。基于實體掩碼指標提取擴散模型的潛在特征作為對應的實體表示。
- DragAnything的主框架。利用相應的實體表示和二維高斯表示來控制實體的運動。