貨拉拉Flink CDC實踐:穩(wěn)定性建設(shè)與數(shù)據(jù)入湖新探索
一、貨拉拉業(yè)務(wù)背景介紹
1. 貨拉拉背景介紹
貨拉拉是一家拉貨搬家跑腿發(fā)長途平臺,創(chuàng)立于 2013 年,成長于粵港澳大灣區(qū),是從事同城/跨城貨運、企業(yè)版物流服務(wù)、搬家、零擔、跑腿、冷運、汽車租售及車后市場服務(wù)的互聯(lián)網(wǎng)物流商城。通過共享模式整合社會運力資源,完成海量運力儲備,并依托移動互聯(lián)、大數(shù)據(jù)和人工智能技術(shù),搭建“方便、科技、可靠”的貨運平臺,實現(xiàn)多種車型的即時智能調(diào)度,為個人、商戶及企業(yè)提供高效的物流解決方案。
2. 業(yè)務(wù)整體增長情況

截至 2023 年 12 月,貨拉拉業(yè)務(wù)范圍覆蓋全球 11 個市場,包括中國及東南亞、南亞、南美洲等地區(qū),其中中國內(nèi)地總共覆蓋 363 座城市,月活司機達 90 萬,月活用戶達 1200 萬,每天產(chǎn)生訂單、司機、汽車物聯(lián)網(wǎng)數(shù)據(jù)量達到 PB 級別。如何穩(wěn)定、高效、快速采集到這些數(shù)據(jù),挖掘業(yè)務(wù)數(shù)據(jù)價值,釋放新質(zhì)生產(chǎn)力成為公司運營和決策的關(guān)鍵。
3. 業(yè)務(wù)攀升的穩(wěn)定性挑戰(zhàn)

隨著企業(yè)業(yè)務(wù)量的急速攀升,逐漸遇到新的挑戰(zhàn),首先是實時抽數(shù)延遲嚴重,導致下游 Flink 的雙流 Join 產(chǎn)生問題,并帶來數(shù)據(jù)時效性、數(shù)據(jù)鏈路穩(wěn)定性等問題。早期使用 Canal 作為實時數(shù)采集主要存在以下問題:
- 架構(gòu)陳舊:單節(jié)點部且非分布式運行,維護頻率低。
- Canal 維護性差:可維護性差,Canal 社區(qū)的整體上下游處于不活躍,導致維護性成本特別高。
- 上游數(shù)據(jù)采集穩(wěn)定性差,結(jié)合歷史故障以及冒煙測試,發(fā)現(xiàn)實時數(shù)據(jù)采集穩(wěn)定性主要集中在上游數(shù)據(jù)采集端。
接下來將介紹貨拉拉實時數(shù)據(jù)采集改造為什么選擇 Flink CDC 作為新的實時數(shù)據(jù)采集和同步框架。
二、貨拉拉為何選擇 Flink CDC
1. 選擇四象限作為思考切入點

首先我們會從上述四點去考慮到底需要一款什么工具作為貨拉拉的實時數(shù)據(jù)同步工具。
- 功能性:實時數(shù)據(jù)平臺首先考慮完善的功能性,F(xiàn)link SQL 目前開源版本僅支持單表單庫同步,如果業(yè)務(wù)方想完成其同步作業(yè)的話,必須使用 SQL 或 Flink CDC3.0 的 yaml 配置化方式才能完成整庫同步開發(fā)。
- 對標 Canal 兼容性:歷史業(yè)務(wù)方使用 Canal 進行數(shù)據(jù)采集,以及下游不限于大數(shù)據(jù)團隊的消費方均使用 Canal,因此要對部分 Canal 功能進行兼容性對標,已實現(xiàn)業(yè)務(wù)感知和改動最小化。
- 鏈路穩(wěn)定性保障:涉及下游任務(wù)方的改造,當前只能通過 Kafka 消費組獲取下游消費方,因此希望下游消費方無需做過多改動,如 SQL 任務(wù)下游僅需切換 CDC 數(shù)據(jù)源即可;同時包裝了一個消費 CDC 的 SDK 供業(yè)務(wù)使用,依據(jù)相關(guān) topic 命名規(guī)則即可完成整個鏈路切換,保障鏈路切換的穩(wěn)定性。
- 保障數(shù)據(jù)一致性:鏈路切換時希望保障數(shù)據(jù)的一致性,即最終數(shù)據(jù)結(jié)果是等價的。因此需要通過一些科學的數(shù)據(jù)驗證手段,如雙跑驗證、采用對數(shù)工具,保證數(shù)據(jù)最終一致。
2. 開源組件對比

我們在進行實時數(shù)據(jù)同步調(diào)研時對一些開源組件的功能、使用場景、穩(wěn)定性以及社區(qū)生態(tài)等多方面進行了對比,包括 Flink CDC、Canal、Apache SeaTunnel 以及 DataX。
- CDC 同步機制:傳統(tǒng)數(shù)據(jù)同步方面,DataX 只支持查詢的 CDC 操作。Flink CDC 只需要訂閱 binlog 即可完成數(shù)據(jù)采集比較服務(wù)業(yè)務(wù)訴求。
- 全量+增量同步:只有 Flink CDC 支持全量+增量數(shù)據(jù)同步,滿足貨拉拉某些場景下采集全量數(shù)據(jù)構(gòu)建湖倉一體,業(yè)務(wù)需要持續(xù)性地對歷史數(shù)據(jù)進行全量采集并加上增量數(shù)據(jù)同步,而其他組件在此方面表現(xiàn)為不支持或部分支持。
- 部署形態(tài):由于 Flink CDC 是依托于 Flink 的底層架構(gòu),F(xiàn)link 本身采用分布式部署,架構(gòu)選型會考慮 Flink CDC 在數(shù)據(jù)采集階段以及下游消費階段的整體的一些協(xié)調(diào)性。
- 穩(wěn)定性:Flink CDC 依靠于 Flink 的 HA 機制,包括 ZooKeeper 以及 on K8s 的高可用,整體上會更加傾向于 Flink CDC 作為實時鏈路的數(shù)據(jù)同步工具。
3. 未來數(shù)據(jù)入湖需求

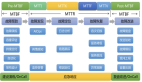
我們正在建設(shè)的數(shù)據(jù)入湖,也做了一些面向未來的設(shè)計,包括 CDC 數(shù)據(jù)入湖分析,數(shù)據(jù)時效性高且為結(jié)構(gòu)化數(shù)據(jù),而埋點數(shù)據(jù)時效性低且非結(jié)構(gòu)化數(shù)據(jù),以及日志數(shù)據(jù)需要間接性統(tǒng)計和分析,并且為非結(jié)構(gòu)樹數(shù)據(jù)。這里我們需要通過引入 CDC pipeline 機制對接 Paimon Yaml 配置,便可通過 CDC 將傳統(tǒng) MySQL 數(shù)據(jù)庫直接訂閱入湖到 Paimon,然后進行數(shù)據(jù)加工等 ETL 相關(guān)操作。

經(jīng)過前期的深度思考、對比與總結(jié)最終形成了如上圖所示的架構(gòu),主要包括數(shù)據(jù)來源、業(yè)務(wù)場景、數(shù)據(jù)服務(wù)以及數(shù)據(jù)湖平臺、數(shù)據(jù)引擎、湖倉格式、數(shù)據(jù)存儲層以及業(yè)務(wù)等。數(shù)據(jù)內(nèi)部開發(fā)平臺主要是元數(shù)據(jù)平臺(元初)、離線數(shù)據(jù)平臺(IDP)以及實時數(shù)據(jù)開發(fā)平臺(飛流);數(shù)據(jù)湖平臺主要包含數(shù)據(jù)集成服務(wù)和湖倉優(yōu)化服務(wù)。數(shù)據(jù)集成服務(wù)采用 Flink CDC 實時采集把數(shù)據(jù)源的數(shù)據(jù)訂閱到湖倉里面,并通過 Amoro 進行自動優(yōu)化湖倉,從而達到湖倉一體的整體架構(gòu)。在執(zhí)行引擎方面當前只是完成了基于 Flink Engine 的建設(shè),對于灰色的 Doris Engine、Spark Engine 以及 Presto Engine 將是 2025 年的建設(shè)重點,數(shù)據(jù)加工完成后將輸送給業(yè)務(wù)方,如埋點業(yè)務(wù)、業(yè)務(wù)畫像以及實時大屏、同時也會輸出給內(nèi)部 GPT 項目等提供給業(yè)務(wù)方去使用。
三、貨拉拉 CDC 生產(chǎn)實踐
1. 飛流實時計算平臺能力建設(shè)

飛流作為貨拉拉的實時計算平臺,為了很好的對接 Flink CDC,實時數(shù)據(jù)計算平臺進行了升級優(yōu)化,主要包括以下幾個方面:
- 平臺感知能力:修改了很多底層代碼,新增了 Metrics 的一些能力,如把 DB 底層的 Metrics 進行了封裝,連同 Flink 的 Metrics 一并上報,形成報警能力,便于業(yè)務(wù)及時發(fā)現(xiàn) DB 底層的整體采集狀況。
- 平臺配置化能力:對 Flink CDC 的 catalog 做了一層封裝,同時支持 Flink Yaml 的配置化方式,提供了更多的靈活性。
- 平臺數(shù)據(jù)協(xié)議優(yōu)化:由于采用 Flink CDC Connector 進行二次開發(fā),當前對數(shù)據(jù)協(xié)議進行了二次封裝,把內(nèi)部的 DB 層數(shù)據(jù)進行打?qū)挘⒃黾恿艘恍┰甲侄危С謽I(yè)務(wù)方消費這些數(shù)據(jù),同時做到了傳統(tǒng)數(shù)據(jù)庫的采集數(shù)據(jù)落庫。
- 數(shù)據(jù)解析優(yōu)化:通過增加元數(shù)據(jù)字段的一些信息,提高了在數(shù)據(jù)協(xié)議和數(shù)據(jù)解析的速度。
- SDK 封裝:由于 CDC 數(shù)據(jù)的使用者不僅包括大數(shù)據(jù)內(nèi)部平臺,還包含很多線上業(yè)務(wù)方,因此封裝了一套 SDK,屏蔽 CDC 相對業(yè)務(wù)方比較復雜的概念與邏輯,交付業(yè)務(wù)方使用。
從數(shù)據(jù)架構(gòu)層面,目前正在做的是統(tǒng)一數(shù)據(jù)采集的工作,如海內(nèi)網(wǎng)逐步推進整體使用 Flink CDC 替換掉 Canal,以及一鍵入倉、一鍵入湖的工作,甚至一些流量回放業(yè)務(wù)場景。在數(shù)據(jù)遷移方面,我們也會用到 Flink CDC。
穩(wěn)定性方面,引入了限流的能力,如會限制 sink 的采集速度,避免在采集高風險期引起數(shù)據(jù)庫的整體壓力。采集性能方面引入了多線程處理,提升解析能力。同時做了全局血緣的關(guān)聯(lián),用于快速感知業(yè)務(wù)方使用 CDC 表,以及 CDC 采集數(shù)據(jù)影響下游任務(wù),可以快速讓業(yè)務(wù)方感知采集出現(xiàn)問題時會導致哪些業(yè)務(wù)受到影響。
以上就是對飛流實時計算平臺整體能力的介紹。
2. 常規(guī)對數(shù)方法校驗

由于采用 Flink CDC 代替了 Canal 進行實時數(shù)據(jù)采集,因此需要進行數(shù)據(jù)校驗和對比。首先在常規(guī)對數(shù)方面,對特殊字段類型,如時間類型、bigInt、dynamic 等特殊字段的數(shù)據(jù)一致性校驗,同時基于時間切片做了 count 統(tǒng)計操作。由于消費方在大數(shù)據(jù)內(nèi)部,因此還會涉及到數(shù)倉分層逐層對數(shù)的校驗,這里我們使用 Flink batch task 在維度時間對齊、最終切片對齊的最大差異、差異占比以及差異分布等方面進行統(tǒng)一對數(shù)。
3. 數(shù)據(jù)科學方法校驗

上文提到使用 Flink batch task 進行統(tǒng)一對數(shù),主要會在基于差異率的正負進行分布式對數(shù),差異統(tǒng)計表、全局指標的差值以及與 Canal 對比差異的趨勢率。如上圖可以看到,可通過總條數(shù)以及每一個時間切片上面每一個數(shù)據(jù)的準確性進行整體對比,確保從 ODS 到 DWD 以及 DWS 層整體鏈路數(shù)據(jù)準確性和最終一致性,如果出現(xiàn)數(shù)據(jù)缺少將會主動進行排查。
4. 數(shù)據(jù)雙跑校驗

還會通過數(shù)據(jù)雙跑進行數(shù)據(jù)校驗,如通過生產(chǎn) Kafka 和驗證 Kafka 去進行數(shù)據(jù)交叉鏈路驗證對比,然后基于 binlog 采集時間對比這一段時間的數(shù)據(jù)總數(shù)以及數(shù)據(jù)的準確性進而得出一個交叉率,當兩部分數(shù)據(jù)完全一致時交叉率應(yīng)該是 100%,最終會輸出一份報告給到業(yè)務(wù)方,使業(yè)務(wù)方信任,并推動業(yè)務(wù)使用鏈路切換工作順利開展。
5. Schema Change 信息變更處理

由于基于 Flink CDC Connector 進行開發(fā),只有 3.0 才支持 Schema 變更操作,當前做法是把 Schema Change 通過一個測流發(fā)送到對應(yīng)告警的 Kafka topic,并通過消費再發(fā)出一個告警卡片,同時會將此任務(wù)告警和下一個任務(wù) Flink taskId 進行關(guān)聯(lián),通知下游業(yè)務(wù)方 Schema 變更消息。后續(xù)我們將接入 CDC3.X Pipeline Connector,進行定制化開發(fā),提供分流告警和下游支持等。
6. Canal VS Flink CDC 穩(wěn)定性對比

下面介紹一下切換后的整體穩(wěn)定性。以某一真實在線業(yè)務(wù)為例,在下午高峰期采集的時候,使用 Canal 最大的延遲在 3030s 左右,而使用 Flink CDC 基本維持在毫秒級別。在采集的整體穩(wěn)定性方面,可以看到 CDC 整體采集穩(wěn)定性要比 Canal 有顯著提升,最高可提高 80 倍。采集波動率方面,Canal 采集按照 Batch 作業(yè)有批量的波動,而 CDC 則保持在一個穩(wěn)定的水平。

截止到目前,我們已經(jīng)有 100+ 個 CDC 采集業(yè)務(wù),其中有 70+ 是之前的 Canal 任務(wù)切換到 Flink CDC,后續(xù)海外一些 Canal 采集也將會采用 Flink CDC 代替。
整體上延遲最高下降了 80%,同時我們基于協(xié)議進行改造,因此消息中間件的數(shù)據(jù)存量也下降了 30%,并且完成了一些核心應(yīng)用加關(guān)鍵線上業(yè)務(wù)的接入。上圖給出了整體延遲的 1h 截圖,可發(fā)現(xiàn)使用 Flink CDC 的數(shù)據(jù)采集基本上穩(wěn)定保持在 1s 左右,可以比較好地保持數(shù)據(jù)的新鮮度。
7. 建設(shè)成果

整體建設(shè)成果方面,當前通過訂閱關(guān)系型數(shù)據(jù)庫,通過飛流平臺使用 Flink 作業(yè)進行數(shù)據(jù)采集,寫入到 Kafka 或流入數(shù)據(jù)湖組件上,后續(xù)經(jīng)過離線 ETL 加工輸出后生成一些報表。目前公司內(nèi)部業(yè)務(wù)包括小伙拉行、貨拉拉、跑腿等多個業(yè)務(wù)線使用 Flink CDC 代替了原先的 Canal 進行實時數(shù)據(jù)鏈路采集,整體業(yè)務(wù)數(shù)據(jù)量達到 TB-PB 級別,并且多個實時看板、云臺、BI 報表以及交易 2.0 等業(yè)務(wù)也使用 Flink CDC 進行實時數(shù)據(jù)采集。最終我們希望可以實現(xiàn)數(shù)據(jù)訂閱鏈路的“以舊換新“,后續(xù)將持續(xù)對老鏈路的替換,最終完成平臺化工程建設(shè)。
四、CDC 數(shù)據(jù)入湖&未來展望

結(jié)合公司內(nèi)部使用場景以及阿里最新發(fā)布的 Fluss 項目,為我們帶來了一些新的想法。如上圖,業(yè)務(wù)數(shù)據(jù)經(jīng)過 CDC 訂閱同步后進入到 Fluss,F(xiàn)luss 將消費 CDC 的數(shù)據(jù)產(chǎn)生 changeLog,并將這個 changeLog 給到 Flink 下游繼續(xù)去消費。同時也會通過 Compaction Service 生成數(shù)據(jù)到 LakeHouse Storage,這一部分數(shù)據(jù)通過 Compaction Service 生成一些湖格式的表,如 Paimon 或 Iceberg 表,這些表可以通過外表的形式給到 OLAP 引擎或流計算引擎進行查詢。同時在 Flink 的 source 一端做合并讀的操作,如把 LakeHouse storage 進行合并讀從而屏蔽掉用戶對流和批的差異。
當然這樣將數(shù)據(jù)引入到 LakeHouse storage 會帶來讀放大的問題,可以引入 Amoro 持續(xù)優(yōu)化 Paimon 和 Iceberg 表減少小文件的數(shù)量,同時在為下游消費這部分 CDC 數(shù)據(jù)時帶來更好的體驗。

當前我們正在探索 Flink CDC+數(shù)據(jù)湖(Paimon 和 Iceberg),并結(jié)合 Apache Amoro 實現(xiàn)全自動數(shù)據(jù)入湖,形成完整的數(shù)據(jù)入湖生態(tài)體系,進一步提升數(shù)據(jù)時效性和準確性,以滿足業(yè)務(wù)方對數(shù)據(jù)新鮮度的需求。并將與數(shù)據(jù)湖開源社區(qū)開展深度合作與探討,把場景固化,加速湖倉一體落地的進程。
我們還會考慮多數(shù)據(jù)源訂閱的需求,滿足關(guān)系型和非慣性數(shù)據(jù)的訂閱查詢,如支持 MongoDB 數(shù)據(jù)的訂閱,構(gòu)建貨拉拉統(tǒng)一實時采集和湖倉數(shù)據(jù)生態(tài)。