Flink CDC + Hudi 海量數據入湖在順豐的實踐
?摘要:本文整理自順豐大數據研發工程師覃立輝在 5月 21 日 Flink CDC Meetup 的演講。主要內容包括:
- 順豐數據集成背景
- Flink CDC 實踐問題與優化
- 未來規劃
一、順豐數據集成背景

順豐是快遞物流服務提供商,主營業務包含了時效快遞、經濟快遞、同城配送以及冷鏈運輸等。
運輸流程背后需要一系列系統的支持,比如訂單管理系統、智慧物業系統、以及很多中轉場、汽車或飛機上的很多傳感器,都會產生大量數據。如果需要對這些數據進行數據分析,那么數據集成是其中很重要的一步。
順豐的數據集成經歷了幾年的發展,主要分為兩塊,一塊是離線數據集成,一塊是實時數據集成。離線數據集成以 DataX 為主,本文主要介紹實時數據集成方案。
2017 年,基于 Jstorm + Canal 的方式實現了第一個版本的實時數據集成方案。但是此方案存在諸多問題,比如無法保證數據的一致性、吞吐率較低、難以維護。2019 年,隨著 Flink 社區的不斷發展,它補齊了很多重要特性,因此基于 Flink + Canal 的方式實現了第二個版本的實時數據集成方案。但是此方案依然不夠完美,經歷了內部調研與實踐,2022 年初,我們全面轉向 Flink CDC 。

上圖為 Flink + Canal 的實時數據入湖架構。
Flink 啟動之后,首先讀取當前的 Binlog 信息,標記為 StartOffset ,通過 select 方式將全量數據采集上來,發往下游 Kafka。全量采集完畢之后,再從 startOffset 采集增量的日志信息,發往 Kafka。最終 Kafka 的數據由 Spark 消費后寫往 Hudi。
但是此架構存在以下三個問題:
- 全量與增量數據存在重復:因為采集過程中不會進行鎖表,如果在全量采集過程中有數據變更,并且采集到了這些數據,那么這些數據會與 Binlog 中的數據存在重復;
- 需要下游進行 Upsert 或 Merge 寫入才能剔除重復的數據,確保數據的最終一致性;
- 需要兩套計算引擎,再加上消息隊列 Kafka 才能將數據寫入到數據湖 Hudi 中,過程涉及組件多、鏈路長,且消耗資源大。
基于以上問題,我們整理出了數據集成的核心需求:

- 全量增量自動切換,并保證數據的準確性。Flink + Canal 的架構能實現全量和增量自動切換,但無法保證數據的準確性;
- 最大限度地減少對源數據庫的影響,比如同步過程中盡量不使用鎖、能流控等;
- 能在已存在的任務中添加新表的數據采集,這是非常核心的需求,因為在復雜的生產環境中,等所有表都準備好之后再進行數據集成會導致效率低下。此外,如果不能做到任務的合并,需要起很多次任務,采集很多次 Binlog 的數據,可能會導致 DB 機器帶寬被打滿;
- 能同時進行全量和增量日志采集,新增表不能暫停日志采集來確保數據的準確性,這種方式會給其他表日志采集帶來延遲;
- 能確保數據在同一主鍵 ID 下按歷史順序發生,不會出現后發生的事件先發送到下游。

Flink CDC 很好地解決了業務痛點,并且在可擴展性、穩定性、社區活躍度方面都非常優秀。
- 首先,它能無縫對接 Flink 生態,復用 Flink 眾多 sink 能力,使用 Flink 數據清理轉換的能力;
- 其次,它能進行全量與增量自動切換,并且保證數據的準確性;
- 第三,它能支持無鎖讀取、斷點續傳、水平擴展,特別是在水平擴展方面,理論上來說,給的資源足夠多時,性能瓶頸一般不會出現在 CDC 側,而是在于數據源/目標源是否能支持讀/寫這么多數據。
二、Flink CDC 實踐問題與優化

上圖為 Flink CDC 2.0 的架構原理。它基于 FLIP-27 實現,核心步驟如下:
- Enumerator 先將全量數據拆分成多個 SnapshotSplit,然后按照上圖中第一步將 SnapshotSplit 發送給 SourceReader 執行。執行過程中會對數據進行修正來保證數據的一致性;
- SnapshotSplit 讀取完成后向 Enumerator 匯報已讀取完成的塊信息;
- 重復執行 (1) (2) 兩個步驟,直到將全量數據讀取完畢;
- 全量數據讀取完畢之后,Enumerator 會根據之前全量完成的 split 信息, 構造一個 BinlogSplit。發送給 SourceRead 執行,讀取增量日志數據。
問題一:新增表會停止 Binlog 日志流
?
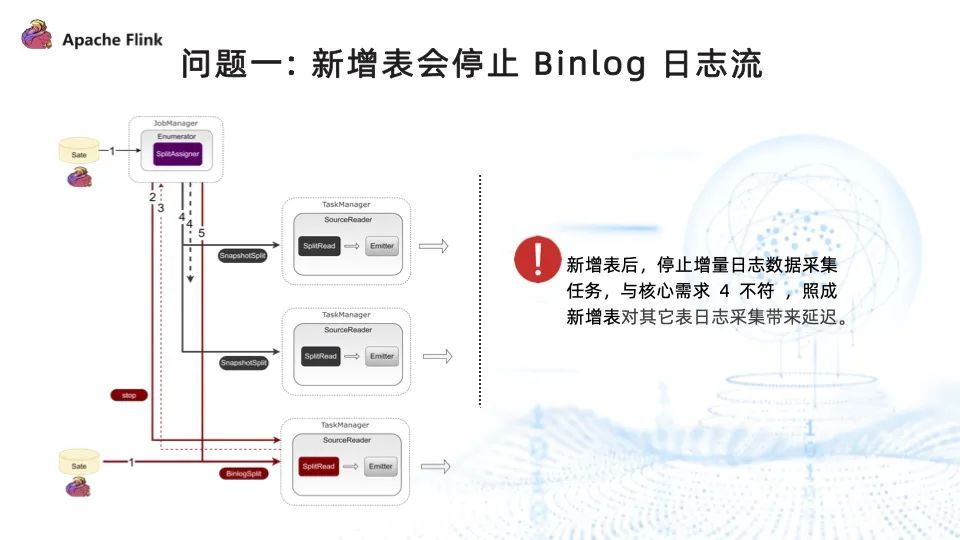
在已存在的任務中添加新表是非常重要的需求, Flink CDC 2.0 也支持了這一功能。但是為了確保數據的一致性,Flink CDC 2.0 在新增表的流程中,需要停止 Binlog 日志流的讀取,再進行新增表的全量數據讀取。等新增表的全量數據讀取完畢之后,再將之前停止的 Binlog 任務重新啟動。這也意味著新增表會影響其他表的日志采集進度。然而我們希望全量和增量兩個任務能夠同時進行,為了解決這一問題,我們對 Flink CDC 進行了拓展,支持了全量和增量日志流并行讀取,步驟如下:

- 程序啟動后,在 Enumerator 中創建 BinlogSplit ,放在分配列表的第一位,分配給 SourceReader 執行增量數據采集;
- 與原有的全量數據采集一樣,Enumerator 將全量采集切分成多個 split 塊,然后將切分好的塊分配給 SourceReader 去執行全量數據的采集;
- 全量數據采集完成之后,SourceReader 向 Enumerator 匯報已經完成的全量數據采集塊的信息;
- 重復 (2) (3) 步,將全量的表采集完畢。
以上就是第一次啟動任務,全量與增量日志并行讀取的流程。新增表后,并行讀取實現步驟如下:

- 恢復任務時,Flink CDC 會從 state 中獲取用戶新表的配置信息;
- 通過對比用戶配置信息與狀態信息,捕獲到要新增的表。對于 BinlogSplit 任務,會增加新表 binlog 數據的采集;對于 Enumerator 任務,會對新表進行全量切分;
- Enumerator 將切分好的 SnapshotSplit 分配給 SourceReader 執行全量數據采集;
- 重復步驟 (3),直到所有全量數據讀取完畢。
然而,實現全量和增量日志并行讀取后,又出現了數據沖突問題。

如上圖所示, Flink CDC 在讀取全量數據之前,會先讀取當前 Binlog 的位置信息,將其標記為 LW,接著通過 select 的方式讀取全量數據,讀取到上圖中 s1、s2、 s3、s4 四條數據。再讀取當前的 Binlog 位置,標記為 HW, 然后將 LW 和 HW 中變更的數據 merge 到之前全量采集上來的數據中。經過一系列操作后,最終全量采集到的數據是 s1、s2、s3、s4 和 s5。
而增量采集的進程也會讀取 Binlog 中的日志信息,會將 LW 和 HW 中的 s2、s2、s4、s5 四條數據發往下游。
上述整個流程中存在兩個問題:首先,數據多取,存在數據重復,上圖中紅色標識即存在重復的數據;其次,全量和增量在兩個不同的線程中,也有可能是在兩個不同的 JVM 中,因此先發往下游的數據可能是全量數據,也有可能是增量數據,意味著同一主鍵 ID 到達下游的先后順序不是按歷史順序,與核心需求不符。
針對數據沖突問題,我們提供了基于 GTID 實現的處理方案。

首先,為全量數據打上 Snapshot 標簽,增量數據打上 Binlog 標簽;其次,為全量數據補充一個高水位 GTID 信息,而增量數據本身攜帶有 GTID 信息,因此不需要補充。將數據下發,下游會接上一個 KeyBy 算子,再接上數據沖突處理算子,數據沖突的核心是保證發往下游的數據不重復,并且按歷史順序產生。
如果下發的是全量采集到的數據,且此前沒有 Binlog 數據下發,則將這條數據的 GTID 存儲到 state 并把這條數據下發;如果 state 不為空且此條記錄的 GTID 大于等于狀態中的 GTID ,也將這條數據的 GTID 存儲到 state 并把這條數據下發;
通過這種方式,很好地解決了數據沖突的問題,最終輸出到下游的數據是不重復且按歷史順序發生的。

然而,新的問題又產生了。在處理算法中可以看出,為了確保數據的不重復并且按歷史順序下發,會將所有記錄對應的 GTID 信息存儲在狀態中,導致狀態一直遞增。
清理狀態一般首選 TTL,但 TTL 難以控制時間,且無法將數據完全清理掉。第二種方式是手動清理,全量表完成之后,可以下發一條記錄告訴下游清理 state 中的數據。
解決了以上所有問題,并行讀取的最終方案如下圖所示。
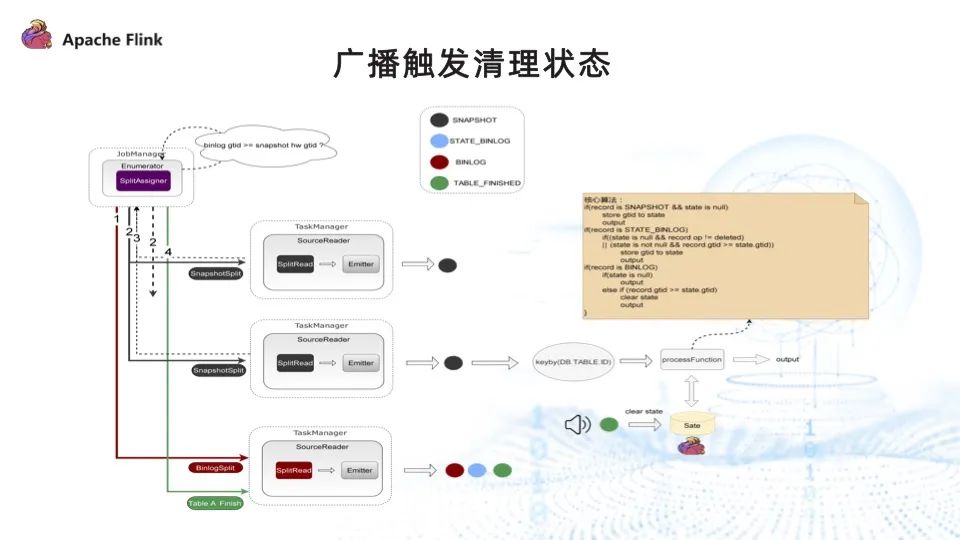
首先,給數據打上四種標簽,分別代表不同的狀態:
- SNAPSHOT:全量采集到的數據信息。
- STATE_BINLOG:還未完成全量采集, Binlog 已采集到這張表的變更數據。
- BINLOG:全量數據采集完畢之后,Binlog 再采集到這張表的變更數據。
- TABLE_FINISHED:全量數據采集完成之后通知下游,可以清理 state。
具體實現步驟如下:
- 分配 Binlog ,此時 Binlog 采集到的數據都為 STATE_BINLOG 標簽;
- 分配 SnapshotSplit 任務,此時全量采集到的數據都為 SNAPSHOT 標簽;
- Enumerator 實時監控表的狀態,某一張表執行完成并完成 checkpoint 后,通知 Binlog 任務。Binlog 任務收到通知后,將此表后續采集到的 Binlog 信息都打上 BINLOG 標簽;此外,它還會構造一條 TABLE_FINISHED 記錄發往下游做處理;
- 數據采集完成后,除了接上數據沖突處理算子,此處還新增了一個步驟:從主流中篩選出來的 TABLE_FINISHED 事件記錄,通過廣播的方式將其發往下游,下游根據具體信息清理對應表的狀態信息。
問題二:寫 Hudi 時存在數據傾斜

如上圖,Flink CDC 采集三張表數據的時候,會先讀取完 tableA 的全量數據,再讀取tableB 的全量數據。讀取 tableA 的過程中,下游只有 tableA 的 sink 有數據流入。
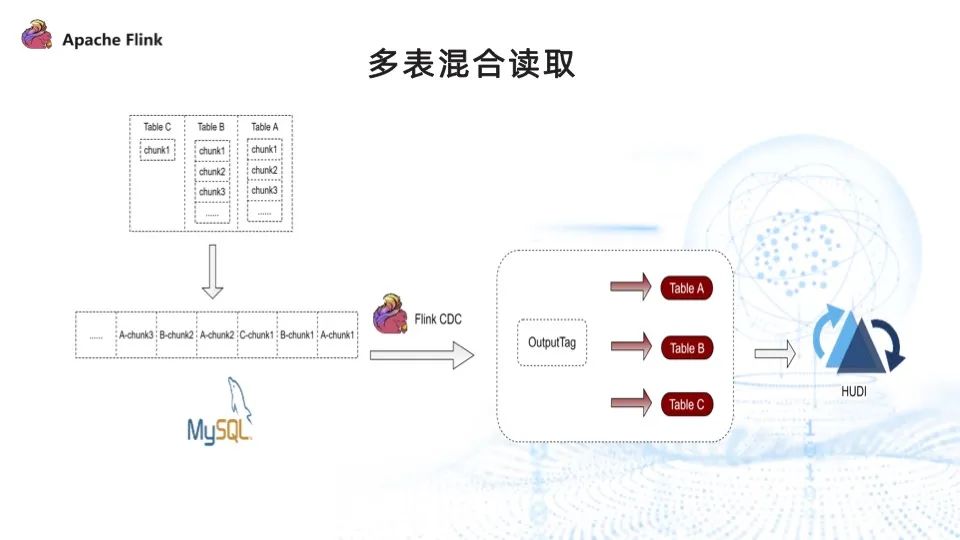
我們通過多表混合讀取的方式來解決數據傾斜的問題。
引入多表混合之前,Flink CDC 讀取完 tableA 的所有 chunk,再讀取 tableB 的所有 chunk。實現了多表混合讀取后,讀取的順序變為讀取 tableA 的 chunk1、tableB 的 chunk1、tableC 的 chunk1,再讀取 tableA 的 chunk2,以此類推,最終很好地解決了下游 sink 數據傾斜的問題,保證每個 sink 都有數據流入。
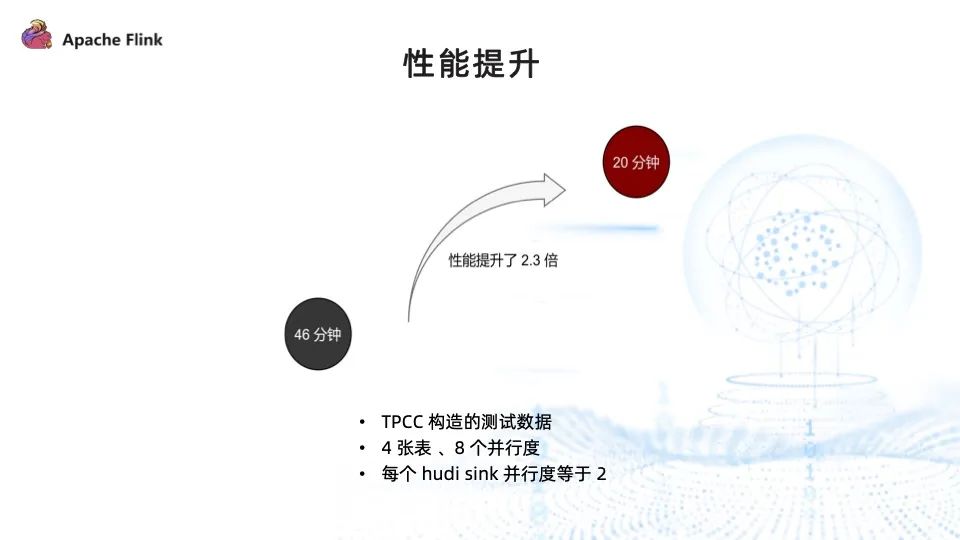
我們對多表混合讀取的性能進行了測試,由 TPCC 工具構造的測試數據,讀取了 4。張表,總并行度為 8,每個 sink 的并行度為 2,寫入時間由原來的 46 分鐘降至 20 分鐘,性能提升 2.3 倍。
需要注意的是,如果 sink 的并行度和總并行度相等,則性能不會有明顯提升,多表混合讀取主要的作用是更快地獲取到每張表下發的數據。
問題三:需要用戶手動指定 schema 信息

用戶手動執行 DB schema 與 sink 之間 schema 映射關系,開發效率低,耗時長且容易出錯。
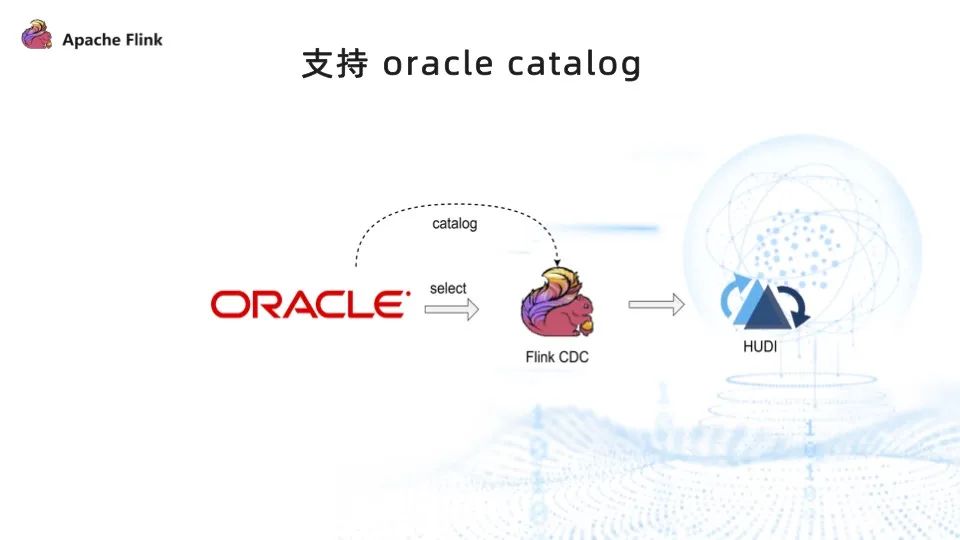
為了降低用戶的使用門檻,提升開發效率,我們實現了 Oracle catalog ,讓用戶能以低代碼的方式、無需指定 DB schema 信息與 sink schema 信息的映射關系,即可通過 Flink CDC 將數據寫入到 Hudi。
三、未來規劃

- 第一, 支持 schema 信息變更同步。比如數據源發生了 schema 信息變更,能夠將其同步到 Kafka 和 Hudi 中;支持平臺接入更多數據源類型,增強穩定性,實現更多應用場景的落地。
- 第二, 支持 SQL 化的方式,使用 Flink CDC 將數據同步到 Hudi 中,降低用戶的使用門檻。
- 第三, 希望技術更開放,與社區共同成長,為社區貢獻出自己的一份力量。
提問&解答
Q1斷點續傳采集如何處理?
斷點續傳有兩種,分為全量和 Binlog。但它們都是基于 Flink state 的能力,同步的過程中會將進度存儲到 state 中。如果失敗了,下一次再從 state 中恢復即可。
Q2MySQL 在監控多表使用 SQL 寫入 Hudi 表中的時候,存在多個 job,維護很麻煩,如何通過單 job 同步整庫?
我們基于 GTID 的方式對 Flink CDC 進行了拓展,支持任務中新增表,且不影響其他表的采集進度。不考慮新增表影響到其他表進度的情況下,也可以基于 Flink CDC 2.2 做新增表的能力。
Q3順豐這些特性會在 CDC 開源版本中實現嗎?
目前我們的方案還存在一些局限性,比如必須用 MySQL 的 GTID,需要下游有數據沖突處理的算子,因此較難實現在社區中開源。
Q4Flink CDC 2.0 新增表支持全量 + 增量嗎?
是的。
Q5GTID 去重算子會不會成為性能瓶頸?
經過實踐,不存在性能瓶頸,它只是做了一些數據的判斷和過濾。