













從 DeepSeek 看25年前端的一個小趨勢
大家好,我卡頌。
最近DeepSeek R1爆火。有多火呢?連我爺爺都用上了,還研究起提示詞工程來了。
大模型不斷發展對我們前端工程師有什么長遠影響呢?本文聊聊25年前端會有的一個小趨勢。
模型進步的影響
像DeepSeek R1這樣的推理模型和一般語言模型(類似Claude Sonnet、GPT-4o、DeepSeek-V3)有什么區別呢?
簡單來說,推理模型的特點是:「推理能力強,但速度慢、消耗高」。
他比較適合的場景比如:
- Meta Prompting(讓推理模型生成或修改給一般語言模型用的提示詞)
- 路徑規劃
等等。
這些應用場景主要利好AI Agent。
再加上一般語言模型在生成效果、token上下文長度上持續提升。可以預見,類似Cursor Composer Agent這樣的AI Agent在25年能力會持續提升,直到成為開發標配。
這會給前端工程師帶來什么進一步影響呢?
一種抽象的理解
我們可以將AI Agent抽象得理解為「應用壓縮算法」,什么意思呢?
以Cursor Composer Agent舉例:
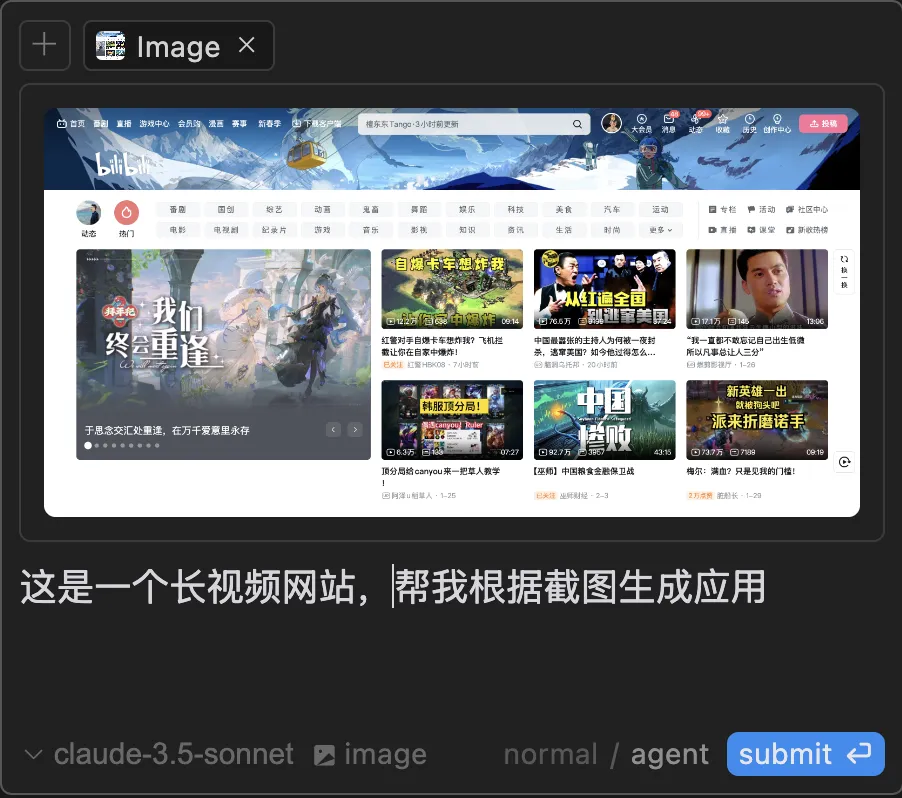
我們傳入:
- 描述應用狀態的提示詞
- 描述應用結構的應用截圖
AI Agent幫我們生成應用代碼。

同樣,也能反過來,讓AI Agent根據應用代碼幫我們生成「描述應用的提示詞」。

從左到右可以看作是「解壓算法」,從右往左可以看作是「壓縮算法」。
就像圖片的壓縮算法存在「失真」,基于AI Agent抽象的「應用壓縮算法」也存在失真,也就是「生成的效果不理想」。
隨著上文提到的「AI Agent」能力提高(背后是模型能力提高、工程化的完善),「應用壓縮算法」的失真率會越來越低。
這會帶來什么進一步的影響呢?
對開發的影響
如果提示詞(經過AI Agent)就能準確表達想要的代碼效果,那會有越來越多「原本需要用代碼表達的東西」被用提示詞表達。
比如,21st.dev[1]的組件不是通過npm,而是通過提示詞引入。
相當于將「引入組件的流程」從:開發者 -> 代碼。
變成了:開發者 -> 提示詞 -> AI Agent -> 代碼。

再比如,CopyCoder[2]是一款「上傳應用截圖,自動生成應用提示詞」的應用。
當你上傳應用截圖后,他會為你生成多個提示詞文件。
其中.setup描述AI Agent需要執行的步驟,其他文件是「描述應用實現細節的結構化提示詞」
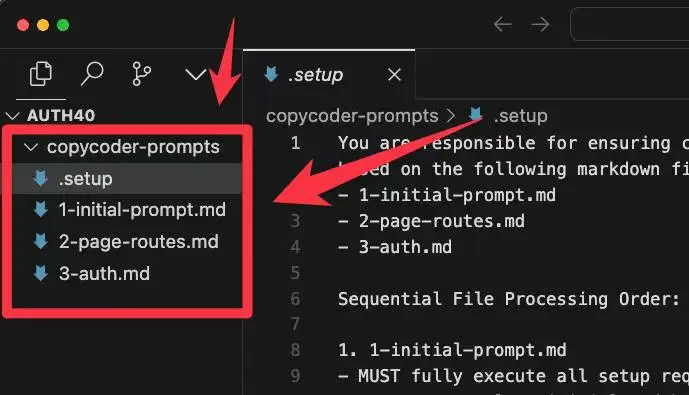
這個過程相當于「根據應用截圖,將應用壓縮為提示詞」。
很自然的,反過來我們就能用AI Agent將這段提示詞重新解壓為應用代碼。
這個過程在25年會越來越絲滑。
這會造成的進一步影響是:越來越多前端開發場景會被提煉為「標準化的提示詞」,比如:
- 后臺管理系統
- 官網
- 活動頁
前端開發的日常編碼工作會越來越多被上述流程取代。
你可能會說,當前AI生成的代碼效果還不是很好。
但請注意,我們談的是「趨勢」。當你日復一日做著同樣的業務時,你的硅基對手正在每年大跨步進步。
總結
隨著基礎模型能力提高,以及工程化完善,AI Agent在25年會逐漸成為開發標配。
作為應用開發者(而不是算法工程師),我們可以將AI Agent抽象得理解為「應用壓縮算法」。
隨著時間推移,這套壓縮算法的失真率會越來越低。
屆時,會有越來越多「原本需要用代碼表達的東西」被用提示詞表達。
這對前端工程師來說,既是機遇也是挑戰。
參考資料
[1]21st.dev:https://21st.dev/?tab=components&sort=recommended
[2]CopyCoder:https://copycoder.ai/



















