零基礎也能看懂的 ChatGPT 等大模型入門解析!
近兩年,大語言模型LLM(Large Language Model)越來越受到各行各業的廣泛應用及關注。對于非相關領域研發人員,雖然不需要深入掌握每一個細節,但了解其基本運作原理是必備的技術素養。本文筆者結合自己的理解,用通俗易懂的語言對復雜的概念進行了總結,與大家分享~

一、什么是ChatGPT?
GPT 對應的是三個關鍵概念:生成式(Generative)、預訓練(Pre-Training)和Transformer。
生成式(Generative):是指通過學習歷史數據來生成全新的數據。當使用ChatGPT回答問題時,是逐字(或三四個字符一起)生成的。在生成過程中,每一個字(或詞,在英文中可能是詞根)都可以被稱作一個 token。
預訓練(Pre-Training):是指預先訓練模型。舉個簡單的例子,我們想讓一個對英語一竅不通的同學去翻譯并總結一篇英語技術文章,首先需要教會這個同學英語的26個字母、以及單詞語法等基礎知識,然后讓他了解文章相關的技術內容,最后才能完成任務。相比之下,如果讓一個精通英語的同學來做這個任務就簡單多了,他只需要大致了解文章的技術內容,就能很好地總結出來。「這就是預訓練的作用——提前訓練出一些通用能力。在人工智能中,預訓練是通過不斷調整參數來實現的。」如果我們可以提前將這些通用能力相關的參數訓練好,那么在特定場景中,只需要進行簡單的參數微調即可,從而大幅減少每個獨立訓練任務的計算成本。
Transformer:這是ChatGPT的核心架構,是一種神經網絡模型。后文將對其進行詳細的說明。
綜上,ChatGPT就是一個采用了預訓練的生成式神經網絡模型,能夠模擬人類的對話。
二、ChatGPT核心任務
ChatGPT核心任務就是生成一個符合人類書寫習慣的下一個合理的內容。具體實現邏輯就是:根據大量的網頁、數字化書籍等人類撰寫內容的統計規律,推測接下來可能出現的內容。
1. 逐字/逐詞推測
在使用ChatGPT時,如果細心觀察會發現它回答問題時是逐字或逐詞進行的。這正是ChatGPT的本質:根據上下文對下一個要出現的字或詞進行推測。例如,假設我們要讓ChatGPT預測“今天天氣真好”,它的運行步驟如下:
- 輸入“今”這個字,輸出可能是“天”,“日”,“明”這三個字,其中結合上下文概率最高的是“天”字。
- 輸入“今天”這兩個字,輸出可能是“天”,“好”,“氣”這三個字,其中結合上下文概率最高的是“氣”字。
- 輸入“今天天”這三個字,輸出可能是“氣”,“好”,“熱”這三個字,其中結合上下文概率最高的是“氣”字。
- 輸入“今天天氣”這四個字,輸出可能是“真”,“好”,“熱”這三個字,其中結合上下文概率最高的是“真”字。
- 輸入“今天天氣真”這五個字,輸出可能是“好”,“熱”,“美”這三個字,其中結合上下文概率最高的是“好”字。
由于ChatGPT學習了大量人類現有的各種知識,它可以進行各種各樣的預測。這就是Transformer模型最終做的事情,但實際原理要復雜得多。
三、AI基礎知識
在介紹 ChatGPT 的原理之前,先學習一下人工智能的一些基礎知識:
1. 機器學習 (Machine Learning, ML)
機器學習是指從有限的觀測數據中學習(或“猜測”)出具有一般性的規律,并將這些規律應用到未觀測數據樣本上的方法。主要研究內容是學習算法。基本流程是基于數據產生模型,利用模型預測輸出。目標是讓模型具有較好的泛化能力。
舉一個經典的例子,我們挑西瓜的時候是如何判斷一個西瓜是否成熟的呢?每個人一開始都是不會挑選的,但是隨著我們耳濡目染,看了很多挑西瓜能手是怎么做的,發現可以通過西瓜的顏色、大小、產地、紋路、敲擊聲等因素來判斷,這就是一個學習的過程。
2. 神經網絡
(1) 與人腦的類比
神經網絡的設計靈感來源于人腦的工作方式。當信息進入大腦時,神經元的每一層或每一級都會完成其特殊的工作,即處理傳入的信息,獲得洞見,然后將它們傳遞到下一個更高級的層。神經網絡模仿了這一過程,通過多層結構來處理和轉換輸入數據。
(2) 基本形式的人工神經網絡
最基本形式的人工神經網絡通常由三層組成:
- 輸入層:這是數據進入系統的入口點。每個節點代表一個特征或屬性,例如在預測房價的例子中,輸入層可能包含房屋面積、臥室數量、浴室數量等特征。
- 隱藏層:這是處理信息的地方。隱藏層可以有多個,每一層中的節點會對來自前一層的數據進行加權求和,并通過激活函數(如 ReLU、Sigmoid 或 Tanh)進行非線性變換。隱藏層的數量和每層的節點數可以根據任務復雜度進行調整。
- 輸出層:這是系統根據數據決定如何繼續操作的位置。輸出層的節點數量取決于任務類型。例如,在分類任務中,輸出層可能對應于不同類別的概率分布;在回歸任務中,輸出層可能直接給出預測值。

每一層的每一個節點都會對模型的某個參數進行調整計算。在大部分情況下,每個當前節點與上層的所有節點都是相連的,這種連接方式被稱為全連接(fully connected)。然而,在某些特定的應用場景下,完全連接的網絡可能會顯得過于復雜,因此需要采用更高效的網絡結構。
(3) 卷積神經網絡(Convolutional Neural Networks, CNNs)
在處理圖像等具有特定已知結構的數據時,使用卷積神經網絡(CNN)會更加高效。CNN 的設計是為了捕捉局部模式和空間關系,其特點包括:
- 卷積層:卷積層中的神經元布置在類似于圖像像素的網格上,并且僅與網格附近的神經元相連。這種方式減少了參數數量,同時保留了重要的局部信息。
- 池化層:用于降低特征圖的空間維度,減少計算量并防止過擬合。常見的池化方法包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全連接層:通常位于網絡的末端,用于將提取到的特征映射到最終的輸出類別或預測值。
4. 參數/權重
所有的AI都有一個模型,這個模型可以簡單地被理解為我們數學里的一個公式,比如一個線性公式:。參數(權重)就是 和 。在 ChatGPT 中,3.0 版本已經有了 1750 億個參數,4.0 的參數規模未公布,但可以猜測只會比 3.0 版本更多。因此,在這樣巨大的參數規模中進行調參訓練是一個非常耗費計算資源(如 GPU)的工作,所以需要大量的資金和機房支持。
5. 監督學習 / 無監督學習
「監督學習」:簡單的理解就是給算法模型一批已經標記好的數據。例如,我們提前給模型提供 1000 個西瓜,并且標記好這 1000 個西瓜是否已經成熟,然后由模型自己不斷去學習調整,計算出一組最擬合這些數據的函數參數。這樣我們在拿到一個全新的西瓜時,就可以根據這組參數來進行比較準確的預測。
「無監督學習」:就是我們扔給模型 1000 個西瓜,由算法自己去學習它們的特征,然后把相似的類逐漸聚合在一起。在理想情況下,我們希望聚合出 2 個類(成熟和不成熟)。
6. 過擬合 / 欠擬合
在模型進行訓練時,最終的目的就是訓練出一組參數來最大限度地擬合訓練數據的特征。但是訓練的過程總會出現各種問題,比較經典的就是過擬合和欠擬合。其中,
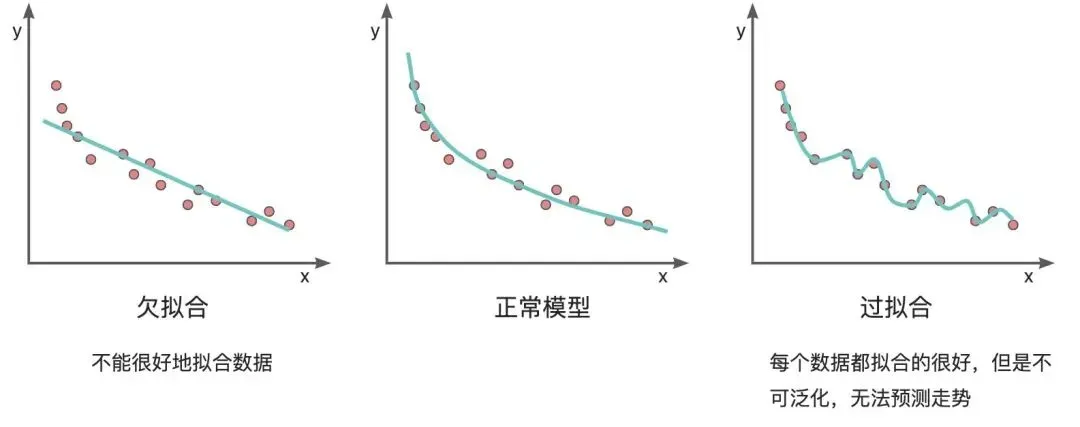
直接舉例說明更直接一點,如下圖,我們希望模型能盡量好的來匹配我們的訓練數據,理想狀態下模型的表現應當和中間的圖一致,但實際訓練中可能就會出現左右兩種情況。左邊的欠擬合并并沒有很好的擬合數據,預測一個新數據的時候準確率會比較低,而右側看起來非常好,把所有的數據都成功擬合了進去,但是模型不具有泛化性,也沒有辦法對新的數據進行準確預測。
那么怎么解決過擬合和欠擬合的問題呢?可以根據模型訓練中的實際表現情況來進行正則化處理、降低復雜度處理等方法,這一點可以自行查閱相關資料。
四、有監督微調(Supervised Fine-Tuning, SFT)
有監督微調是一種用于機器學習的超參數調整方法,它可以使用從未見過的數據來快速準確地調整神經網絡的權重參數,以獲得最佳的性能。它可以幫助機器學習模型快速地從訓練數據中學習,而不需要重新訓練整個網絡。
五、強化學習模型(Proximal Policy Optimization, PPO)
強化學習模型(PPO)是一種強化學習算法,可以使智能體通過最大化獎勵信號來學習如何與環境進行交互。它使用剪裁目標函數和自適應學習率來避免大的策略更新。PPO 還具有學習可能不完全獨立和等分布數據的優勢。
六、人類反饋強化學習(Reinforcement Learning with Human Feedback, RLHF)
人類反饋強化學習(RLHF)是訓練 GPT-3.5 系列模型而創建的一種方法。主要包括三個步驟,旨在通過人類反饋來優化語言模型的輸出質量。
- 使用監督學習訓練語言模型:首先通過大量標記數據訓練一個基礎語言模型。
- 根據人類偏好收集比較數據并訓練獎勵模型:生成多個輸出并讓人類評估其質量,訓練一個獎勵模型來預測這些輸出的質量分數。
- 使用強化學習針對獎勵模型優化語言模型:通過獎勵模型優化語言模型,使其生成更符合人類偏好的輸出。
舉個例子,假設我們要訓練一個能夠生成高質量對話的LLM,RLHF具體步驟如下:
(1) 預訓練和微調:使用大量的對話數據對 LLM 進行預訓練和微調,使其能夠生成連貫的對話文本。
(2) 生成多個輸出:
① 給 LLM 提供一個提示,例如:“今天天氣怎么樣?”
② LLM 生成多個響應,例如:
- 響應1:今天天氣真好。
- 響應2:不知道,我沒有查看天氣預報。
- 響應3:今天天氣晴朗,適合外出。
③ 人工評估:讓人類評估這些響應的質量,并為每個響應分配一個分數。
- 響應1:3
- 響應2:1
- 響應3:4
④ 訓練獎勵模型:使用這些人工評估的數據來訓練一個獎勵模型。獎勵模型學習如何預測 LLM 生成文本的質量分數。
⑤ 強化學習循環:
- 創建一個強化學習循環,LLM 的副本成為 RL 代理。
- 在每個訓練集中,LLM 從訓練數據集中獲取多個提示并生成文本。
- 將生成的文本傳遞給獎勵模型,獎勵模型提供一個分數來評估其與人類偏好的一致性。
- 根據獎勵模型的評分,更新 LLM 的參數,使其生成的文本在獎勵模型上的得分更高。
通過這種方式,RLHF 能夠顯著提高 LLM 的輸出質量,使其生成的文本更符合人類的偏好和期望。
七、Transformer架構
對于像ChatGPT這樣的大語言模型,Transformer架構是其核心。與傳統的RNN和LSTM不同,Transformer完全依賴于自注意力機制(self-attention mechanism),允許模型并行處理長序列數據,而不需要逐個處理時間步。Transformer的主要組成部分包括:
- 編碼器(Encoder):負責將輸入序列轉換為上下文表示。每個編碼器層包含一個多頭自注意力機制(Multi-Head Self-Attention Mechanism)和一個前饋神經網絡(Feed-Forward Neural Network),兩者之間通過殘差連接(Residual Connection)和層歸一化(Layer Normalization)連接。
- 解碼器(Decoder):負責生成輸出序列。解碼器層不僅包含自注意力機制和前饋神經網絡,還包括一個編碼器-解碼器注意力機制(Encoder-Decoder Attention Mechanism),用于關注輸入序列中的相關信息。
- 位置編碼(Positional Encoding):由于Transformer沒有內在的時間/順序概念,位置編碼被添加到輸入嵌入中,以提供關于單詞相對位置的信息。
八、Transformer基本原理
第一步:Embedding
在Transformer架構中,embedding的過程可以簡單理解為將輸入的詞(token)映射成向量表示。這是因為神經網絡處理的是數值型數據,而文本是由離散的符號組成的。因此,需要一種方法將這些符號轉換為模型能夠理解和處理的連續向量形式。
(1) Token Embedding
每個輸入的token通過一個查找表(lookup table)被映射到一個固定維度的稠密向量空間中。這個查找表實際上是一個可訓練的參數矩陣,其中每一行對應于詞匯表中的一個token。例如,在GPT-2中,每個token會被轉化為長度為768的embedding向量;而在更大型的模型如ChatGPT所基于的GPT-3中,embedding向量的長度可能達到12288維。
(2) Positional Encoding
由于Transformer沒有像RNN那樣的內在順序處理機制,它無法直接感知序列中元素的位置信息。為了彌補這一點,引入了位置編碼(positional encoding),它為每個位置添加了一個唯一的標識符,使得模型能夠在處理過程中考慮到token的相對或絕對位置。位置編碼通常也是通過一個固定的函數生成,或者是作為額外的可學習參數加入到模型中。
(3) Token和Position Embedding的結合
最終的embedding是通過將token embedding和position embedding相加得到的。具體來說:
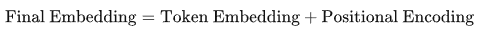
這種相加的方式并不是隨意選擇的,而是經過大量實驗驗證后被認為有效的方法之一。其背后的原因在于:
- 保持原始信息:通過簡單地相加,既保留了token本身的語義信息,又引入了位置信息。
- 允許自適應調整:即使初始設置不是最優的,隨著訓練的進行,模型可以通過梯度下降等優化算法自動調整這些embedding,以更好地捕捉數據中的模式。
- 簡化計算:相比于其他復雜的組合方式,簡單的相加操作更加高效,并且不會增加太多額外的計算負擔。
以字符串“天氣”為例,假設我們使用GPT-2模型來處理:
- Token Embedding:首先,“天”和“氣”這兩個字符分別被映射到它們對應的768維向量。
- Positional Encoding:然后,根據它們在句子中的位置(第一個位置和第二個位置),分別為這兩個字符生成相應的位置編碼向量。
- 相加生成最終的embedding:最后,將上述兩個步驟得到的向量相加以形成最終的embedding向量序列。
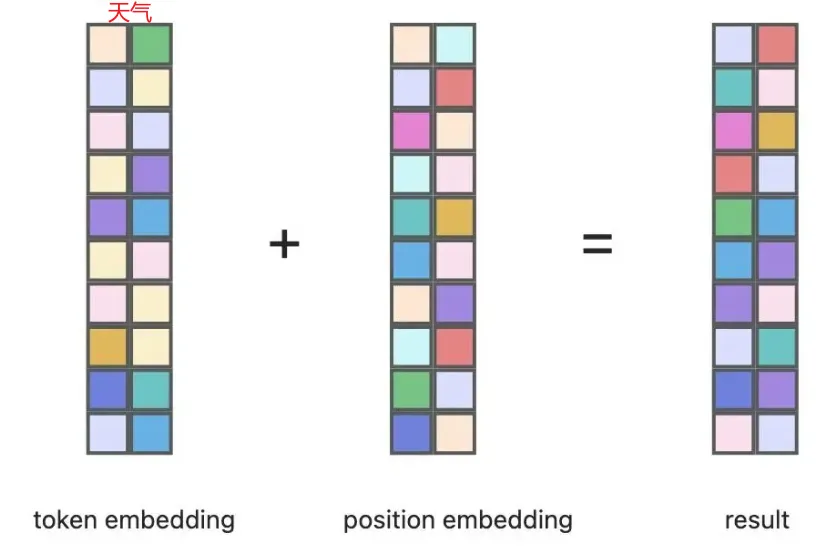
如上圖,第一張圖中展示了token embedding,其中縱向一列表示一個向量,依次排列的是“天”和“氣”的embedding向量。第二張圖則顯示了位置的embedding,反映了這兩個字符的位置信息。將這兩者相加后,我們就得到了包含語義和位置信息的完整embedding序列。
第二步:Attention
在Transformer架構中,Attention機制是核心組件之一,它使得模型能夠并行處理長序列數據,并且有效地捕捉輸入序列中的依賴關系。Attention機制的核心思想是讓模型關注輸入序列的不同部分,從而更好地理解上下文信息。
(1) 自注意力(Self-Attention)
自注意力(也稱為內部注意力)是Transformer中的一種特殊形式的Attention,它允許每個位置的token與序列中的所有其他位置進行交互。這意味著每個token都可以根據整個序列的信息來調整自己的表示,而不僅僅是依賴于前一個或后一個token。
(2) Attention Head
每個“注意力塊”(Attention Block)包含多個獨立的Attention Heads,這些Head可以看作是不同視角下的Attention計算。每個Head都會獨立地作用于embedding向量的不同子空間,這樣可以捕捉到更多樣化的信息。例如,在GPT-3中有96個這樣的注意力塊,每個塊中又包含多個Attention Heads。
(3) Q、K、V 的生成
對于每個token的embedding向量,我們通過線性變換(即乘以三個不同的可訓練矩陣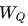 、
、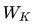 和
和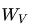 )將其轉換為三個向量:Query (Q)、Key (K) 和 Value (V)。這三個向量分別代表查詢、鍵和值。具體來說:
)將其轉換為三個向量:Query (Q)、Key (K) 和 Value (V)。這三個向量分別代表查詢、鍵和值。具體來說:
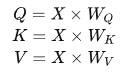
其中,X是輸入的embedding向量,、和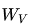 是隨機初始化并在訓練過程中學習得到的權重矩陣。
是隨機初始化并在訓練過程中學習得到的權重矩陣。
(4) Attention分數的計算
接下來,我們需要計算每個token與其他所有token之間的Attention分數。這一步驟使用了Scaled Dot-Product Attention公式:
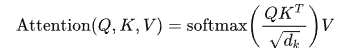
這里,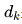 是Key向量的維度大小,用于縮放點積結果以穩定梯度。Softmax函數確保輸出的概率分布加起來等于1,這樣可以突出最重要的部分。
是Key向量的維度大小,用于縮放點積結果以穩定梯度。Softmax函數確保輸出的概率分布加起來等于1,這樣可以突出最重要的部分。
以上就是 Transformer 的大致原理,用一張圖來表示上面的步驟,如下所示。