機器人視覺控制新范式!ByteDance Research新算法實現通過性能SOTA
世界模型(World Model)作為近年來機器學習和強化學習的研究熱點,通過建立智能體對其所處環境的一種內部表征和模擬,能夠加強智能體對于世界的理解,進而更好地進行規劃和決策。在強化學習領域中,世界模型通常被建模為一個神經網絡,通過歷史狀態和動作,預測未來可能出現的狀態。其中,Dreamer 算法在多種模擬環境的成功表現讓我們看到了世界模型優秀的表征和泛化能力。如果將世界模型應用于復雜真實場景,是否能夠實現更好的控制決策呢?
對此,ByteDance Research 研究團隊成功將世界模型應用于四足機器人視覺控制領域,提出了基于世界模型的感知算法 WMP(World Model-based Perception),WMP 通過在模擬器中學習世界模型和策略,其中世界模型通過歷史感知信息(包括視覺感知和本體感知)預測未來的感知,策略以世界模型提取的特征作為輸入,輸出具體控制動作。
WMP 將模擬器中訓練的世界模型和策略 Zero-Shot 遷移到宇樹 A1 機器人進行驗證,在多種環境下取得了出色的成績,達到了目前為止 A1 機器人 SOTA 的通過性能。同時,使用模擬數據訓練的世界模型可以準確預測真實軌跡,展示出卓越的泛化性能,有望成為一種機器人控制的新范式。
- 項目主頁:https://wmp-loco.github.io/
- 論文地址:https://arxiv.org/abs/2409.16784

研究背景
近年來,強化學習 (RL) 通過在物理模擬器中訓練策略,然后將其轉移到現實世界(Sim-to-Real transfer),在足式機器人的運動控制領域被廣泛應用。在足式機器人的運動控制中,視覺圖像信息對于諸如越障等復雜環境是不可或缺的。
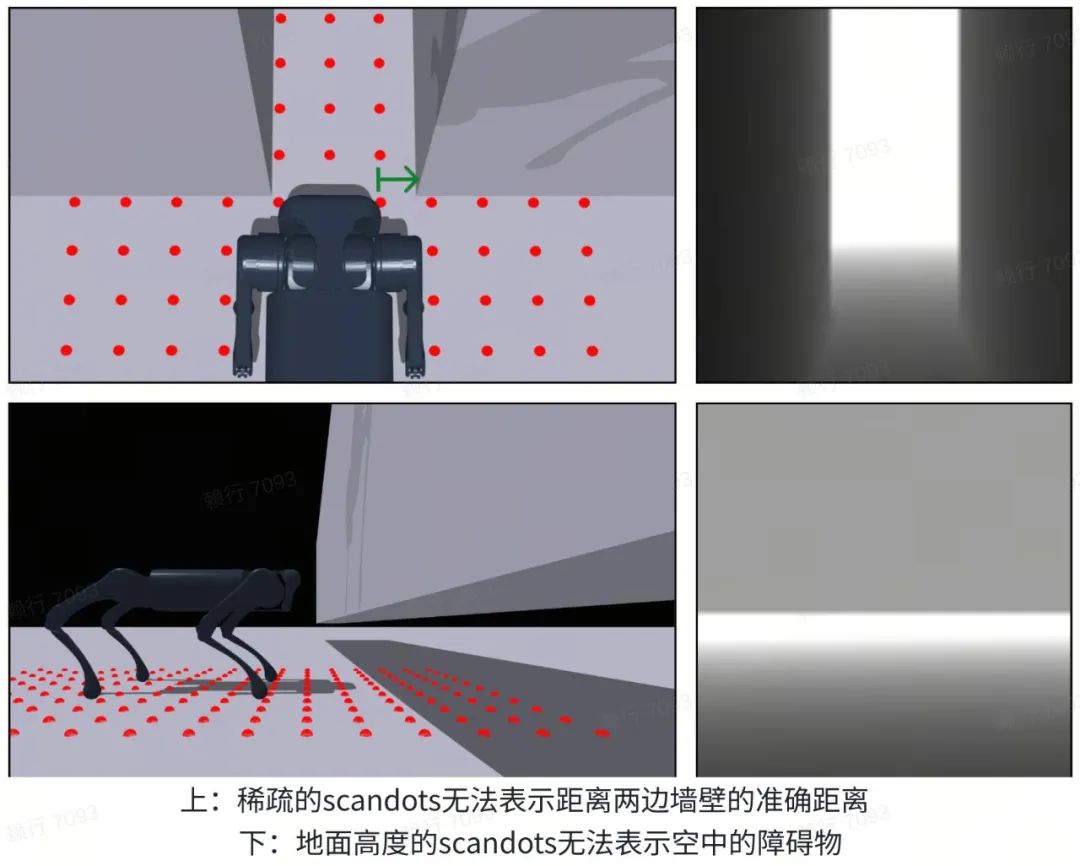
憑借強化學習的獎勵信號從長序列、高維的視覺信息中學習策略難度極大。為了更好地引入視覺信息,傳統特權學習(privileged learning)框架首先學習一個教師策略,教師策略的輸入包含只能在模擬器中得到的特權信息,如高度圖掃標點(heightmap scandots),各類障礙物的幾何參數等。之后再學習一個以深度圖序列為輸入的學生策略以模仿教師策略的動作。
由于特權學習兩階段的訓練模式,學生策略的性能往往落后于教師策略;并且特權信息的選擇需要人工設計,較為繁瑣,同時易受到具體環境的限制。如下圖所示,使用 scandots 作為特權信息無法處理需要精確距離的環境以及存在空中障礙物的環境。
相比之下,動物能夠在沒有特權信息的情況下僅憑借視覺感官信息通過各種非結構化的地形,并且在不熟悉的環境中依然能夠做出合理的決策。認知科學的一種解釋是動物會利用腦中建立的心智模型(mental model)對外部環境進行理解和預測以便更好地理解和應對周圍的環境,從而做出合理的動作和決策。
ByteDance Research 的機器人研究團隊在此啟發下設計了一種更加通用的機器人控制框架 WMP(World Model-based Perception)。WMP 通過構建世界模型來處理復雜的感知信息,并將世界模型提取的環境信息輸入給策略,解決了特權學習中特權信息難以設計的局限性。通過訓練的世界模型和策略可以直接遷移到真實環境的 A1 機器人上,在多種復雜任務中達到了目前該領域的領先水平效果。例如,在世界模型的幫助下,A1 機器人可以跳過 85cm 的間隙,跳上 55cm 的高臺,穿過 22cm 高的橋洞。這些結果證明了世界模型對于決策的正向作用,為之后世界模型在機器人等領域的研究提供了重要參考。
方法

WMP 采用經典的 RSSM 框架作為世界模型的結構,RSSM 包括編碼模塊 encoder,解碼模塊 decoder,以及循環模塊 recurrent model。encoder 將感知信息以及循環狀態編碼為一個隨機變量,decoder 通過循環狀態和隨機變量恢復出原始的感知信息,而循環模塊則通過循環狀態、隨機變量以及動作序列預測下一個循環狀態。為了滿足真機運行的算力要求,WMP 將世界模型的運行頻率設定為策略運行頻率的 k 分之一。由于世界模型主要處理更高層級的信息,較低的控制頻率同樣能滿足底層控制的需求,這與人體大腦和小腦展現出的不同的控制頻率情況有一定的相似之處。
一個訓練有素的世界模型的循環狀態包含足夠多的信息從而預測未來的時間步,也有助于策略執行動作。因此在 WMP 框架中,策略會接受來自世界模型的循環狀態作為輸入。并使用強化學習算法 PPO 進行訓練。此外,策略的訓練和世界模型的訓練使用模擬數據同步進行,簡化了特權學習中的兩階段訓練。訓練后的策略和世界模型可以無需微調直接遷移到真實機器人設備。
實驗結果
模擬實驗:
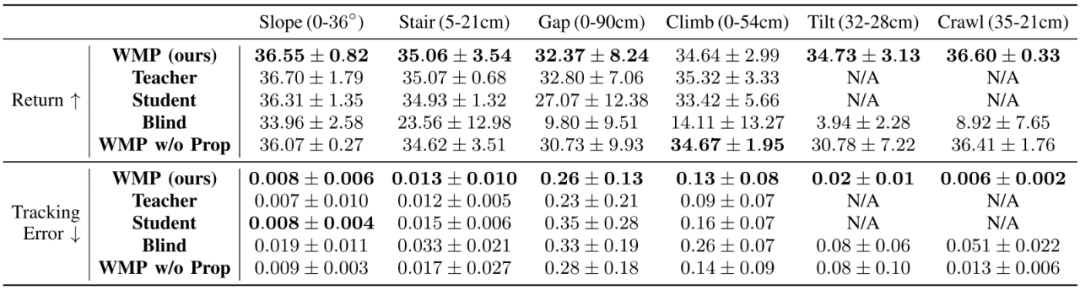
WMP 算法使用 Issacgym 模擬器構建的 6 種地形上進行訓練:Slope、Stair、Gap、Climb、Crawl、Tilt。由于 scandot 特權信息的局限性,使用特權學習訓練的 Student baseline 只使用前四個地形進行訓練。在模擬器的定量對比實驗中,WMP 在絕大多數任務中獲得了比 Baseline 更高的回報獎勵以及更小的速度追蹤誤差。
真機實驗:
在真機實驗中,WMP 繼承了模擬器中的優秀表現,相比 baseline 能以更高的成功率通過更難的地形,并且在室內和室外環境中表現保持一致,進一步展現出世界模型優秀的泛化能力。
一鏡到底視頻:


驗證實驗:

使用模擬數據訓練需要考慮的一個問題是世界模型對真實軌跡預測的準確性如何。驗證實驗表明,世界模型對于真實軌跡的圖像能給出準確的預測,尤其是對于關鍵的部分。例如,世界模型對橋洞障礙物整體形狀的預測存在偏差,但對機器人需通過的窄縫的位置角度的預測十分準確。這驗證了世界模型有利于解構和提取不同域中的關鍵要素,從而有助于模擬到真實的泛化。
總結
本研究提出了一種新的運動控制框架,通過構筑的世界模型來處理視覺信息和輔助決策,在四足機器人運動控制領域取得了不錯的效果。WMP 揭示了世界模型在 Sim2Real 以及機器人控制領域的巨大潛力,為之后世界模型在現實世界更廣泛的應用提供了樣例和寶貴的經驗。