DeepSeek-R1秘籍輕松遷移,最低只需原始數據0.3%
DeepSeek-R1背后關鍵——多頭潛在注意力機制(MLA),現在也能輕松移植到其他模型了!
而且只需原始數據的0.3%~0.6%。
這項研究由復旦大學、華東師范大學、上海AI Lab等聯合提出,復旦教授邱錫鵬(Moss大模型項目負責人)也在作者名單之列。

他們提出了MHA2MLA這種數據高效的微調方法,使基于MHA(多頭注意力)的大語言模型(LLMs)能夠順利轉換到MLA架構。
以Llama2-7B為例,MHA2MLA在降低推理成本(如減少KV緩存大小92.19%)的同時,能將性能損失控制在較小范圍(如LongBench性能僅下降0.5%)。
具體咋回事,下面我們接著看。
掌握DeepSeek核心秘訣
多頭注意力MHA(Multi-Head Attention)是Transformer架構中的一個核心組件,允許模型同時關注輸入的不同部分,每個注意力頭都獨立地學習輸入序列中的不同特征。
然而,隨著序列長度的增長,鍵值(Key-Value,KV)緩存的大小也會線性增加,這給模型帶來了顯著的內存負擔。
為了解決MHA在高計算成本和KV緩存方面的局限性,DeepSeek突破性地引入了多頭潛在注意力機制MLA。
簡單說,MLA最大創新之處在于:
利用低秩聯合壓縮鍵值技術,減少了推理時的KV緩存,從而在保持性能的同時顯著降低內存占用。
這一技術也被視為DeepSeek-V3、DeepSeek-R1等當紅炸子雞模型背后的關鍵。
而現在,為了進一步降低其他LLMs的推理成本,研究人員開發了一種能將采用MHA的模型快速適配MLA架構的方法——MHA2MLA。
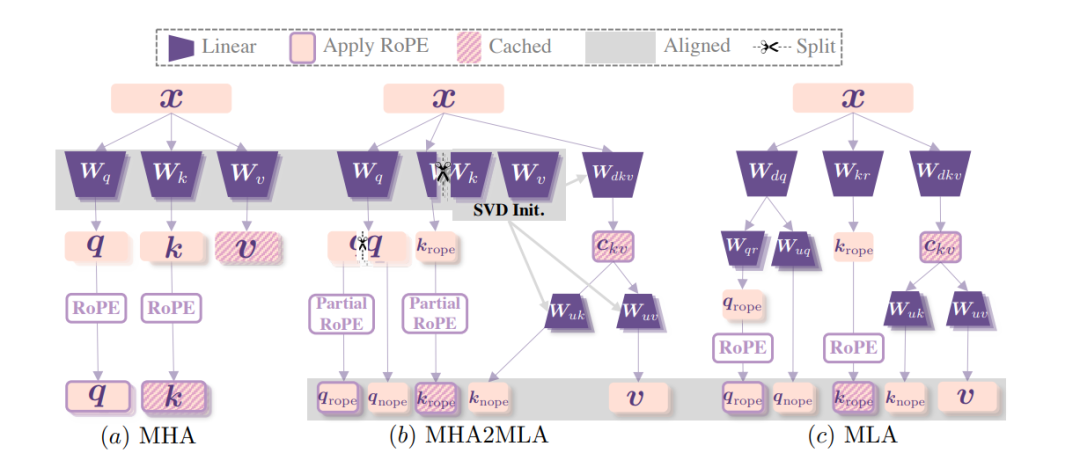
這一數據微調方法包含兩個關鍵部分:
- partial-RoPE,即從對注意力分數貢獻較小的查詢和鍵的維度中移除旋轉位置嵌入(RoPE);
- 低秩近似,基于預訓練的鍵和值參數引入聯合奇異值分解(SVD)近似。
先說第一個。Transformer架構中,RoPE(旋轉位置編碼,Rotary Position Embedding) 通過旋轉操作將位置信息融入查詢向量Q和鍵向量K ,幫助模型捕捉序列位置關系。
但研究發現,在計算注意力分數時,并非所有維度的RoPE對結果貢獻相同。
換句話說,即使去除那些對注意力分數影響較小的部分維度的RoPE,理論上不會對模型理解上下文的能力造成關鍵影響。
基于此,研究人員通過計算敏感度指標來確定哪些維度的RoPE貢獻較小。
具體而言,對于每個維度,計算RoPE變化時注意力分數的變化程度。一旦變化程度低于特定閾值的維度,即被判定為對注意力分數貢獻小。在后續計算中,這些維度將不再應用RoPE。
最終實驗證明,partial-RoPE這一策略在不顯著影響模型性能的前提下,減少了計算量。
再說低秩近似策略。
該方法基于預訓練的鍵和值參數,引入聯合奇異值分解(SVD)近似。
SVD是一種矩陣分解技術,通過對鍵值矩陣進行SVD分解,可以用低秩矩陣近似原始矩陣,從而減少參數數量。
具體實現中,研究人員首先提取預訓練模型中的鍵和值參數矩陣,對這些矩陣進行聯合SVD分解;然后根據模型的性能和壓縮需求,構建低秩近似矩陣,用這些低秩近似矩陣替代原始的鍵值矩陣參與后續計算。
最終結果顯示,此舉有效降低了模型推理時的計算量和內存占用。
性能幾乎不變,將Llama2 KV緩存減少90%以上
實驗環節也驗證了MHA2MLA方法的有效性。
能在顯著降低推理成本的同時,保持甚至提升模型性能。
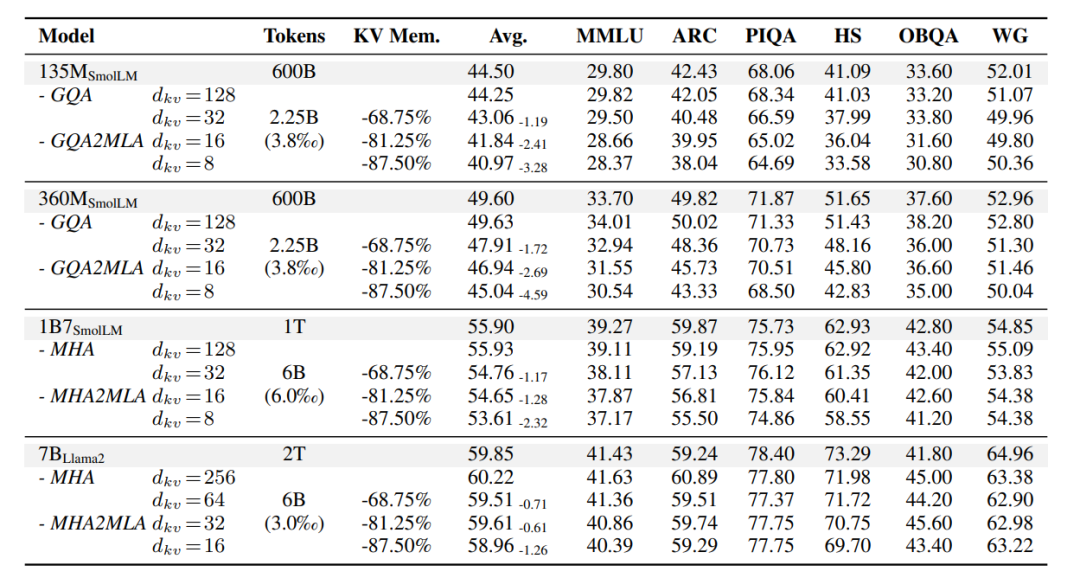
研究人員選取了用MHA或GQA預先訓練的不同規模(135M-7B)的LLMs,然后設置了對照組。
一組是基于傳統MHA的原始模型,用于直接對比MHA2MLA方法在相同任務和數據集上的性能表現;另一組是采用分組查詢注意力(GQA)的模型,GQA作為MHA的變體,在一定程度上優化了計算成本,將其與MHA2MLA對比,能更清晰地展現MHA2MLA的優勢。
在評估其常識性推理能力的六個基準測試中,研究發現:
與原始LLMs性能相比,四個基礎模型的性能變化極小,135M模型性能下降0.25%,360M、1B7和7B模型分別有0.03% 、0.03%和0.37%的性能提升或保持。
這表明微調數據未顯著影響原模型性能,MHA2MLA能有效實現架構遷移,而且微調數據僅需預訓練數據的0.3%-0.6%。
甚至,較大模型在轉換到MLA架構時性能下降更少,這說明這一方法對規模更大的模型更有效。
此外,在長文本生成能力評估中,以LongBench為基準,MHA2MLA相比訓練后量化方法,在壓縮率和精度平衡上表現出色。
當dkv=16時,MHA2MLA可實現87.5%的壓縮率,精度損失僅3%;與4-bit量化結合后,壓縮率可達92.19%(dkv=64 + Int4HQQ)和96.87%(dkv=16 + Int4HQQ),精度損失分別為-0.5%和-3.2%,優于所有2-bit量化的基線模型。
這也反映了MHA2MLA方法能夠與量化技術良好兼容。
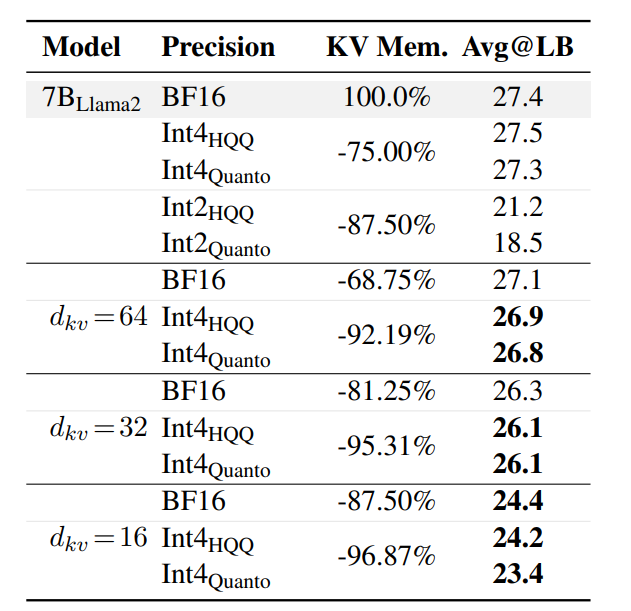
綜合以上實驗,可以看到以Llama2-7B為例,MHA2MLA在降低推理成本(如減少KV緩存大小92.19%)的同時,能將性能損失控制在較小范圍(如LongBench性能僅下降0.5%)。
不過,論文也提到了研究局限性。
受計算資源限制,未在更大、更多樣化的開源大語言模型上驗證MHA2MLA;且由于Deepseek未開源MLA的張量并行推理框架,難以探索大于7B的模型。
下一步,研究人員計劃在更多模型上進行驗證。
感興趣的童鞋可以查看原論文~
論文:https://arxiv.org/abs/2502.14837
代碼:https://github.com/JT-Ushio/MHA2MLA