譯者 | 李睿
審校 | 重樓
本文將深入探討一個至關重要的問題:當系統出現問題時,應當如何有效地監控服務?

一方面,可以借助具備提醒功能的Prometheus,以及集成儀表板和其他實用功能的Kibana來增強監控能力。另一方面,在日志收集方面,ELK堆棧無疑是首選方案。然而,簡單的日志記錄往往不足以滿足需求,因為它無法提供覆蓋整個組件生態系統的請求流程的整體視圖。
如果直觀地展示請求流程呢?或者需要在系統間追蹤關聯的請求,該怎么辦?這既適用于微服務,也適用于單體服務——有多少服務并不重要;重要的是如何管理它們的延遲。
事實上,每個用戶請求可能要經過由獨立服務、數據庫、消息隊列和外部API組成的復雜鏈路。
在這種復雜的環境中,很難準確地確定延遲發生的位置,確定鏈路的哪一部分是性能瓶頸,并在發生故障時快速找到其根本原因。
為了有效地應對這些挑戰,需要一個集中的、一致的系統來收集遙測數據——包括跟蹤、指標和日志。這正是OpenTelemetry和Jaeger發揮重要作用的地方。
了解基礎知識
人們必須理解以下兩個主要術語:
Trace ID
Trace ID是一個16字節的標識符,通常表示為32個字符的十六進制字符串。它在跟蹤開始時自動生成,并在由特定請求創建的所有跨度中保持不變。這樣可以很容易地看到請求是如何通過系統中的不同服務或組件傳遞的。
Span ID
跟蹤中的每個單獨操作都有自己的Span ID,它通常是一個隨機生成的64位值。Span共享相同的Trace ID,但是每個Span都有一個唯一的Span ID,因此可以確定每個Span代表工作流的哪個部分(如數據庫查詢或對另一個微服務的調用)。
它們之間有何關聯?
Trace ID和Span ID是相輔相成的。
當發起請求時,會生成一個Trace ID,并將其傳遞給所有相關服務。每個服務又會創建一個與Trace ID關聯的、具有唯一Span ID的Span,從而能夠可視化請求從開始到結束的完整生命周期。
那么,為什么不直接使用Jaeger呢?為什么需要OpenTelemetry(OTEL)及其所有規范?這是一個很好的問題!以下逐步分析。
- Jaeger是一個用于存儲和可視化分布式跟蹤的系統。它收集、存儲、搜索和顯示數據,顯示請求如何通過服務“傳輸”。
- OpenTelemetry (OTEL)是一個標準(以及一組庫),用于從應用程序和基礎設施中收集遙測數據(跟蹤、指標、日志)。它不依賴于任何單一的可視化工具或后端。
簡而言之:
- OTEL就像一種“通用語言”和一組遙測收集庫。
- Jaeger是用于查看和分析分布式跟蹤的后端和用戶界面。
如果已經有了Jaeger,為什么還需要OTEL?
1.單一的收集標準
在過去,有像OpenTracing和OpenCensus這樣的項目。OpenTelemetry將這些收集指標和跟蹤的方法統一到一個通用標準中。
2.易于集成
采用Go(或其他語言)編寫代碼,為自動注入攔截器和跨度添加OTEL庫,就這樣完成。之后,無論想把數據發送到哪里并不重要——Jaeger、Tempo、Zipkin、Datadog、自定義后端——OpenTelemetry都會負責管道。只需更換導出器即可。
3.不僅僅是跟蹤
OpenTelemetry不僅涵蓋跟蹤,還處理指標和日志。最終,可以使用一個工具集來滿足所有遙測需求,而不僅僅是跟蹤。
4.以Jaeger為后端
如果主要對分布式跟蹤可視化感興趣,Jaeger是一個很好的選擇。但默認情況下,它不提供跨語言檢測。另一方面,OpenTetry提供了一種標準化的數據收集方式,然后可以決定將數據發送到哪里(包括Jaeger)。
在實踐中,它們經常協同工作:
應用程序使用OpenTelemetry→通過OTLP協議通信→進入OpenTelemetry收集器(HTTP或gRPC)→導出到Jaeger進行可視化。

技術部分
系統設計(簡要介紹)
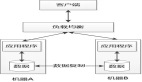
以下快速勾勒出幾個服務,這些服務將執行以下操作:
1.購買服務——處理付款并記錄在MongoDB中。
2.CDC與Debezium——監聽MongoDB表中的更改,并將它們發送到Kafka。
3.購買處理器——使用來自Kafka的消息并調用Auth服務查找user_id進行驗證。
4.認證服務——一種簡單的用戶服務。
總結:
- 3 Go services
- Kafka
- CDC (Debezium)
- MongoDB
代碼部分
從基礎設施開始。為了將所有內容匯集到一個系統中,將創建一個大型的DockerCompose文件,并從設置遙測開始。
注:所有代碼都可以通過本文末尾的鏈接獲得,包括基礎設施。
YAML
services:
jaeger:
image: jaegertracing/all-in-one:1.52
ports:
- "6831:6831/udp" # UDP port for the Jaeger agent
- "16686:16686" # Web UI
- "14268:14268" # HTTP port for spans
networks:
- internal
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
depends_on:
- kafka
- jaeger
- otel-collector
command:
--config.file=/etc/prometheus/prometheus.yml
networks:
- internal
otel-collector:
image: otel/opentelemetry-collector-contrib:0.91.0
command: ['--cnotallow=/etc/otel-collector.yaml']
ports:
- "4317:4317" # OTLP gRPC receiver
volumes:
- ./otel-collector.yaml:/etc/otel-collector.yaml
depends_on:
- jaeger
networks:
- internal還將配置收集器——收集遙測數據的組件。
在這里選擇gRPC進行數據傳輸,這意味著通信將通過HTTP/2進行:
YAML
receivers:
# Add the OTLP receiver listening on port 4317.
otlp:
protocols:
grpc:
endpoint: "0.0.0.0:4317"
processors:
batch:
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter:
check_interval: 1s
limit_percentage: 80
spike_limit_percentage: 15
extensions:
health_check: {}
exporters:
otlp:
endpoint: "jaeger:4317"
tls:
insecure: true
prometheus:
endpoint: 0.0.0.0:9090
debug:
verbosity: detailed
service:
extensions: [health_check]
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheus]確保根據需要調整任何地址,這樣就完成了基本配置。
OpenTelemetry (OTEL)使用兩個關鍵概念——Trace ID和Span ID,它們有助于跟蹤和監控分布式系統中的請求。
代碼實現
現在了解如何讓它在Go代碼中實現這一點。需要以下導入:
Go
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"然后,當應用程序啟動時,在main()中添加一個函數來初始化跟蹤器:
Go
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}在設置跟蹤之后,只需要在代碼中放置span來跟蹤調用。例如,如果想測量數據庫調用(因為這通常是尋找性能問題的第一個地方),可以這樣寫:
Go
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")在服務層進行跟蹤,這太棒了!但可以更深入地分析數據庫層:
Go
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}現在,你對請求過程有了完整的了解。前往Jaeger UI,查詢auth-service下的最后20條跟蹤記錄,將會在一個界面中看到所有的Span以及它們之間的關聯方式。

現在,一切都是可見的。如果需要,可以將整個查詢包含在標記中。需要記住,不應該使遙測過載——故意添加數據。在這里只是在演示什么是可能的,但包括完整的查詢,通常不推薦這種方式。
gRPC客戶機-服務器

如果希望查看跨越兩個gRPC服務的跟蹤,這很簡單。需要做的就是從庫中添加開箱即用的攔截器。例如,在服務器端:
Go
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)在客戶端,代碼也很短:
Go
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}就是這樣!確保導出器配置正確,當客戶端調用服務器時,將看到這些服務上記錄的單個Trace ID。
處理CDC事件和跟蹤
也想變更數據捕獲 (CDC)的事嗎?一個簡單的方法是將Trace ID嵌入到MongoDB存儲的對象中。這樣,當Debezium捕獲更改并將其發送給Kafka時,Trace ID已經是記錄的一部分。
例如,如果使用的是MongoDB,可以這樣做:
Go
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
然后Debezium拾取這個對象(包括trace_id)并將其發送給Kafka。在消費者端,只需解析傳入消息,提取trace_id,并將其合并到跟蹤上下文中:
Go
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}Go:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}替代方案:使用Kafka標頭
有時,將Trace ID存儲在Kafka標頭中比存儲在負載本身中更容易。對于CDC工作流來說,這可能無法開箱使用——Debezium可能限制添加到標題中的內容。但是如果控制了生產者端(或者如果使用的是標準的Kafka生產者),那么可以使用Sarama等工具執行以下操作:
將Trace ID注入標頭
Go
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}在消費者端提取Trace ID
Go
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}根據用例和CDC管道的設置方式,可以選擇最有效的方法:
1.在數據庫記錄中嵌入Trace ID,使其通過CDC自然流動。
2.如果對生產者有更多的控制權,或者想避免增加消息有效載荷的大小,可以使用Kafka標頭。
無論哪種方式,都可以確保跨多個服務的跟蹤信息保持一致,即使事件是通過Kafka和Debezium異步處理的。
結論
使用OpenTelemetry和Jaeger提供詳細的請求跟蹤信息,幫助確定分布式系統中延遲發生的位置和原因。
在添加Prometheus之后,可以通過指標(性能和穩定性的關鍵指標)完善監控體系。這些工具共同構成了一個全面的可觀測性堆棧,能夠更快地檢測和解決問題、優化性能以及提高系統的整體可靠性。
可以說,這種方法在微服務環境中顯著加快了故障排除的速度,是在項目中最先實施的事項之一。
參考鏈接
原文標題:Control Your Services With OTEL, Jaeger, and Prometheus,作者:Ilia Ivankin