別讓更新變麻煩:Python 腳本助你一鍵獲取修復操作系統漏洞補丁包!
在日常工作中,服務器安全是企業運營的關鍵。我們專業的安全團隊會用工具對所有服務器進行掃描,找出潛在的安全問題,并生成詳細的報告,里面不僅有漏洞信息,還有修復建議。如下圖所示,這樣不僅能及時解決問題,還能幫助企業建立更安全的防護體系,保障業務正常運行。
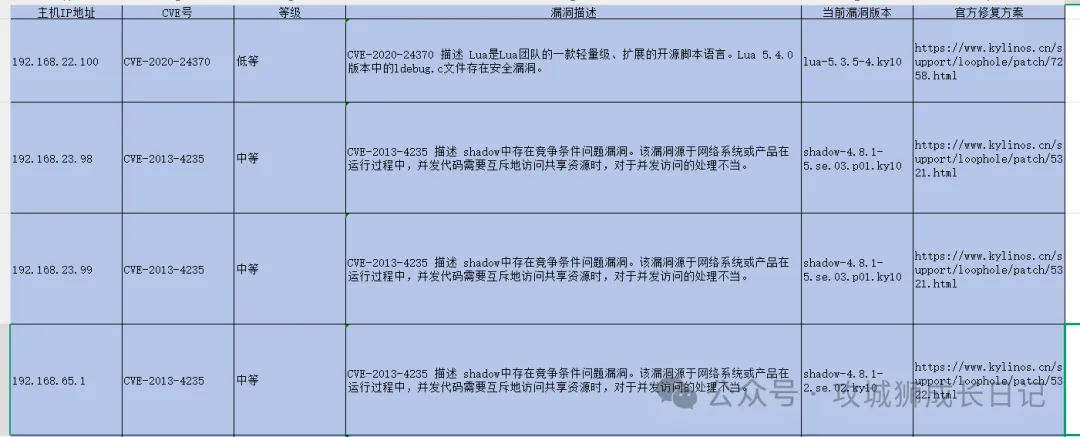
那問題來了,雖然表格中提供了每個漏洞的修復建議鏈接,但還是需要我們逐一訪問官方頁面來詳細了解具體的修復方案。當漏洞數量較少時,這項工作還算輕松;但如果數量較多,那這個任務的工作量確實會變得相當大。
像這種重復的工作肯定是交給腳本去執行的。我們現來分析一下,我們最終想要實現的效果,如下圖所示:

一、實現思路
我們將利用Python中的pandas庫來處理原始數據,以CVE編號作為主要標識符,并把具有相同CVE編號的所有主機信息整理在一起。
對于修復步驟,您可以通過訪問官方提供的修復鏈接,根據頁面上的關鍵詞找到需要更新的具體軟件包。之后,可以根據這些信息構建出使用yum命令進行更新的具體指令。
二、代碼實現
1. 獲取更新軟件包
我們首先分析一下如果從官方修復方案的中提取需要修復軟件包,以CVE-2020-24370這個漏洞為例,打開官方修復方案的鏈接,頁面如下圖所示:
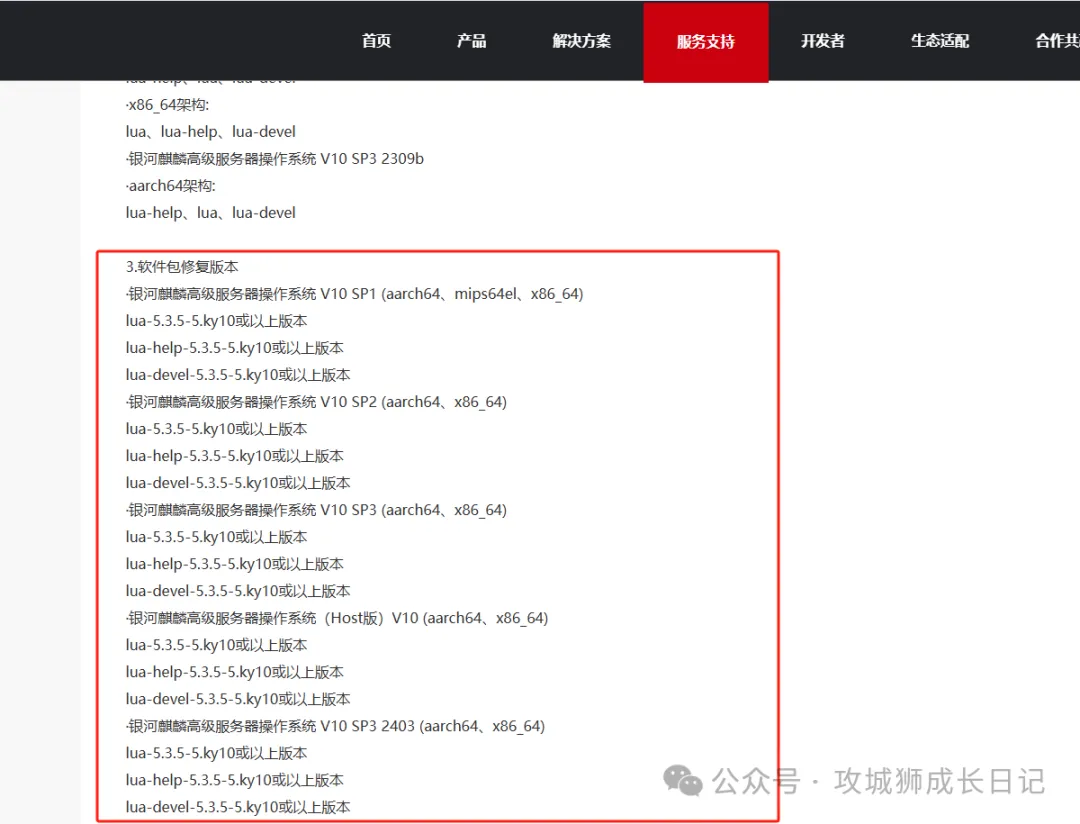
從上圖可以看出,修復的軟件包有一個共同的特點:它們都遵循“包名-版本號_ky10”這樣的命名格式。基于這一點,我們可以使用正則表達式來匹配這些軟件包。
下面是一個示例函數,它可以從指定的網頁中提取出更新的軟件包信息。這個函數的工作流程是這樣的:首先接收一個URL作為參數,然后利用Python的第三方庫requests獲取該網頁的內容,最后通過正則表達式篩選出我們需要的軟件包列表。
def get_kylin_patches(url):
# 設置請求頭模擬瀏覽器訪問
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, timeout=10,headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 獲取所有base-desc容器
desc_containers = soup.find_all('div', class_='base-desc')
# 只提取第二個base-desc內容(索引從0開始)
packages_list = []
iflen(desc_containers) >= 2:
target_desc = desc_containers[1]
# print(target_desc)
# 使用正則表達式匹配軟件包及其版本
pattern = re.compile(r'([a-zA-Z0-9\-]+)-([\d\.]+(?:-\d+)?(?:\.[a-zA-Z0-9]+)*(?:\.ky\d+))')
matches = pattern.findall(str(target_desc))
formatchin matches:
packages_list.append("{}-{}".format(match[0],match[1]))
unique_packages = set(packages_list) # 類型變為set
return unique_packages
except Exception as e:
print(f"獲取補丁信息失敗: {str(e)}")
return '查詢失敗'2. 生成更新軟件包
根據我們上面介紹的方法,您可以輕松獲取到需要更新的軟件包名稱。接下來,我們將使用下面的函數把這些名稱組合成一條完整的更新命令。具體步驟如下:
# 生成yum更新命令(新增代碼)
def generate_yum_command(packages):
if not packages or packages in ('暫無修復包', '查詢失敗'):
return '# 無可用更新'
return f"yum update -y {' '.join(sorted(packages))}"3. 重新組合數據
為了將原始數據轉換為我們需要的格式,我們可以利用Python中的強大工具——Pandas庫來進行數據聚合處理。下面是具體的函數內容:
def process_vulnerability_data(input_file, output_file):
"""處理原始漏洞數據并生成修復計劃表"""
# 讀取數據
df = pd.read_excel(input_file, engine='openpyxl')
# 聚合處理
new_df = df.groupby('CVE號').agg({
'主機IP地址': lambda x: ', '.join(x),
'等級': 'first',
'漏洞描述': 'first',
'當前漏洞版本': 'first',
"官方修復方案": "first"
}).reset_index()
# 新增執行修復命令列
new_df['執行修復命令'] = new_df['官方修復方案'].apply(
lambda url: generate_yum_command(get_kylin_patches(url)) if pd.notnull(url) else'# 無修復鏈接'
)
# 計算主機數量
new_df['涉及主機數量'] = new_df['主機IP地址'].str.split(', ').apply(len)
# 調整列順序
ordered_df = new_df[['CVE號', '主機IP地址', '涉及主機數量', '等級',
'漏洞描述', '當前漏洞版本', '官方修復方案','執行修復命令']]
# 保存結果
ordered_df.to_excel(output_file, index=False)4. 調用函數生成數據
通過調用 process_vulnerability_data,輸入兩個參數:原始數據表以及輸出表的名稱。
if __name__ == '__main__':
process_vulnerability_data(
input_file='漏洞表原始數據_test.xlsx',
output_file='漏洞修復計劃表_test.xlsx'
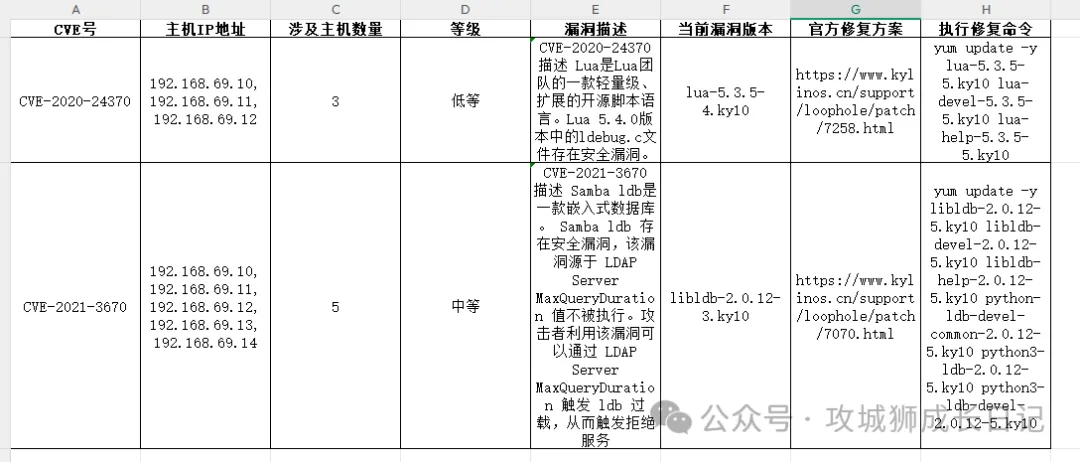
)執行上述命令后,就可以得到我們想要的效果表。如下圖所示:
三、小結
對于那些重復性的任務,我們可以考慮一下是否可以通過自動化工具或腳本來完成。這樣做不僅能提高我們的工作效率,還能讓我們有更多時間去休息或是專注于其他重要的事情上呢!