十年領航,亞馬遜云科技為何能成為云數據庫行業標桿?
原創近日,在Gartner 發布的《2024 年 Gartner 云數據庫管理系統魔力象限報告》中,亞馬遜云科技以卓越的產品能力和前瞻性愿景,連續第十年被評為領導者。Gartner 指出,亞馬遜云科技是全球最廣泛采用的云服務提供商,提供廣泛的云DBMS服務,并且其數據庫服務可滿足交易、操作、分析和流式應用等多種工作負載的需求。
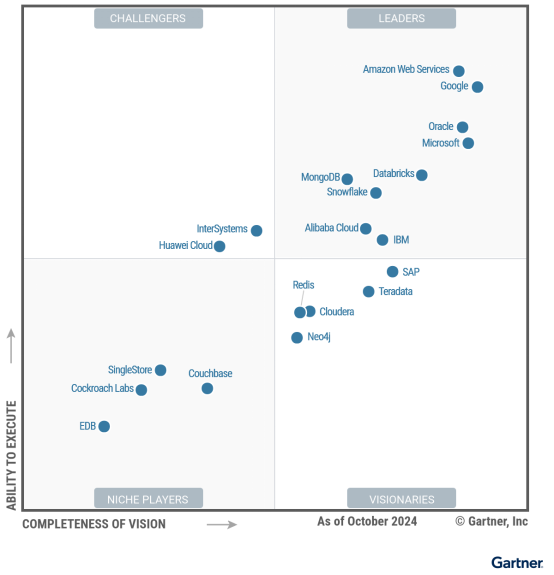
2024 年 Gartner 云數據庫管理系統魔力象限
在云數據庫領域競爭日益激烈之際,亞馬遜云科技究竟憑借何種能力,得以連續十年穩居領導者之位?其背后的關鍵,在于亞馬遜云科技對用戶需求的精準把握,以及對自我設限的持續突破。
對于用戶需求,亞馬遜云科技首席執行官 Matt Garman 表示,如果摒棄各種限制,數據庫客戶認為理想的數據庫解決方案需要具備高可用性、多區域運行、極低的讀寫延遲、強一致性、沒有操作負擔和兼容 SQL 語義的能力。
這些需求并非“或”的關系,而是“和”的關系。單獨一個需求容易滿足,但如此之多的需求能夠同時滿足嗎?答案是可以。
2024 年 12 月,亞馬遜云科技在 2024 re:Invent 全球大會上發布了一款重磅的數據庫服務新品——Amazon Aurora DSQL。這是一款集多種理想型功能于一身的“全能理想型”無服務器分布式 SQL 數據庫,能夠滿足上述所有的功能需求。
若要揭秘亞馬遜云科技為何能“領航十年”,為何能打破限制推出 Amazon Aurora DSQL,則要從2014年說起。
打破“A 或 B”,打造“A 和 B”: 從 Amazon Aurora 到 Amazon Aurora DSQL
2014 年,亞馬遜云科技在 re:Invent 大會上推出了 Amazon Aurora。Amazon Aurora 一經問世,便迅速成為企業上云的首選。究其原因,是因為在當時的市場中,既能滿足高性能需求,又不會帶來高昂成本的數據庫可謂鳳毛麟角。而 Amazon Aurora 恰恰做到了性能與價格的兼顧,自然迅速贏得了企業的青睞。

十年前,Amazon Aurora 在 2014 年 re:Invent 上發布
Amazon Aurora 是兼容 MySQL 和 PostgreSQL 的云原生關系型數據庫,其核心突破在于將傳統數據庫的存儲與計算分離,通過分布式架構實現高性能與高可用性。并且Amazon Aurora 的吞吐量達到傳統 MySQL 的 5 倍,成本卻僅為同級別商業數據庫解決方案的 1/10。
Amazon Aurora 的問世一舉打破了 “魚與熊掌不可兼得” 的傳統認知局限。突破傳統認知的背后,是亞馬遜云科技轉變了“在 A 和 B 之間做選擇” 的固有思維定式,轉而深入探索 “如何同時達成 A 和 B” 的創新路徑。
“當你嘗試構建某些東西或者決策時,常常會在 A 和 B 之間做選擇嗎?這種選擇恰恰限制了思路,亞馬遜云科技將其稱為‘或的暴政’,因為這種選擇制造了虛假的邊界,讓你馬上開始思考自己必須選出A 或 B。但亞馬遜云科技是推動團隊思考如何同時達成 A 和 B。”Matt Garman 在 2024 re:Invent 全球大會揭秘了亞馬遜云科技成功的秘訣之一。
滿足性能與價格的兼得后,Amazon Aurora 仍沒有停止創新的步伐。自Amazon Aurora 發布以來,亞馬遜云科技在此基礎上推出了眾多創新功能,如無服務器版本的推出讓用戶無需管理基礎設施地使用,推出Amazon Aurora Limitless Database以實現跨單臺服務器讀寫吞吐量限制進行擴展和自動分布式分片,與其他數據庫和數據倉庫服務間的Zero-ETL以加速數據流動,與Amazon Bedrock集成以助力客戶更好地構建生成式AI應用。
亞馬遜云科技不僅為Amazon Aurora 打造了“A 和 B”的功能,更是實現了“A 和B 和 C 和 D”的技術迭代與創新。在持續探索與創新過程中,Amazon Aurora DSQL 誕生了。
突破傳統數據庫束縛的Amazon Aurora DSQL
前文提到,Amazon Aurora DSQL 是一款“全能理想型”無服務器分布式 SQL 數據庫,能夠同時實現低延遲、多區域的強一致性、幾乎無限擴展的高可用性,以及零運營負擔。

2024 re:Invent 大會上,亞馬遜云科技發布Amazon Aurora DSQL
同時達成這些能力并不容易。但對于亞馬遜云科技來說,只有突破傳統數據庫的束縛才能實現更好的創新,就像打破“或的暴政”一樣。因此,Amazon Aurora DSQL突破的第一個傳統束縛是將事務處理與存儲解耦。
對于傳統數據庫來說,在單一位置或單一區域實現應用程序和數據庫的往返信息傳遞非常容易,也能夠滿足低延遲的需求;可一旦跨區域執行,信息受到光速的限制,不僅往返傳遞速度會大大降低,也難以達到多區域的強一致性要求。
為了解決這一難題,Amazon Aurora DSQL 應用了一種全新的交易處理方式——解耦事務處理與存儲。這種方式使Amazon Aurora DSQL 在事務提交時會進行一次性檢查,同時并行處理所有區域的所有寫入操作,從而提供具有強一致性和快速寫入的多區域數據庫服務。
實現低延遲和強一致性后,還需確保事務按照發生的順序提交。為了消除不同區域的時間偏差,Amazon Aurora DSQL 采用了 Amazon Time Sync 服務,該服務在每個 Amazon Elastic Compute Cloud(EC2) 實例上部署硬件參考時鐘,使實例與衛星連接的原子鐘同步,以此實現全球范圍內微秒級的精確時間同步。
這兩種能力結合使得Amazon Aurora DSQL 在確保低延遲的同時實現強一致性,即“所有在一個區域寫入的事務都將實時同步至其他區域”。
除此之外,Amazon Aurora DSQL 的另一突破是采用分布式架構,分離查詢處理層、提交層和存儲層,實現了“幾乎無限的擴展能力”。
傳統數據庫由于集中式架構和數據強一致性要求,在數據規模或應用需求快速擴大時,難以高效地進行橫向擴展,且存在數據一致性難以保證、擴展過程復雜等問題。
而Amazon Aurora DSQL 采用了分布式架構,允許查詢處理層、提交層和存儲層分離獨立擴展,以適應不同的讀寫比例、數據規模和查詢復雜性。這種設計不僅消除了傳統數據庫的擴展瓶頸,支持水平擴展,還能夠根據實際負載動態調整資源分配。
Amazon Aurora DSQL 的無服務器特性也進一步簡化了擴展過程,用戶無需手動管理服務器配置或進行數據庫分片,即可實現從較小規模到大規模的無縫過渡。再加上主-主(Active-Active)架構和多區域支持,Amazon Aurora DSQL 便能以高可用性和強一致性滿足各種工作負載需求,為用戶提供靈活、高效且無需妥協的數據庫解決方案。
從結果來看,Amazon Aurora DSQL 不僅提供了卓越的一致性,還將讀寫速度提升了 4 倍,實現了 99.999% 的多區域可用性,具備幾乎無限的可擴展性,且完全消除了管理基礎設施的負擔。
云數據庫領域變革:AI 驅動的創新力量
如果說不斷突破傳統束縛是亞馬遜云科技持續領跑的基礎,那么對行業趨勢的前瞻把握則是保持競爭力的關鍵。進入 AI 時代,各個垂直領域都在尋找與 AI 的融合之道,云數據庫領域也不例外。
《2024 年 Gartner 云數據庫管理系統魔力象限報告》指出,“云數據庫管理系統(DBMS)市場依舊充滿活力,并且正在進行重大變革,特別是在生成式人工智能(AI)的應用,以及數據庫管理系統與其他數據管理組件的交互方式上。”
因此,亞馬遜云科技認為,越來越多的用戶將不再孤立地使用單一的數據分析和處理工具,而是結合分析、ML 和生成式 AI 從而獲取洞察并為用戶提供新體驗。為此,亞馬遜云科技在2024 re:Invent 全球大會上推出了新一代 Amazon SageMaker 作為統一的“工作室”,為用戶提供單一的數據和 AI 開發環境,助力用戶更好地在 AI 時代持續創新發力。
具體來說, Amazon SageMaker Unified Studio 融合了 Amazon Bedrock、Amazon EMR、Amazon Redshift、Amazon Glue 以及現有 Amazon SageMaker Studio 中備受用戶青睞的一系列獨立“工作室”、查詢編輯器和可視化工具等功能。它為用戶打造了一個一站式的數據和 AI 開發環境,讓用戶能夠輕松地訪問和使用這些強大的工具,從而高效地完成數據發現與準備、查詢編寫、數據處理以及機器學習模型的構建。
結語
云數據庫領域的十年霸榜之路,亞馬遜云科技始終在證明:真正的行業領導者不僅要具備解決“既要、又要、還要”復雜需求的技術實力,更要擁有突破傳統思維定式的創新勇氣。未來,亞馬遜云科技將持續尋找突破成本、性能、易用性和功能極限的創新路徑,為用戶帶來更全面和強大的產品使用體驗。