救命!我的 K8s GPU 節點被 AI 訓練“吃”崩了!三招讓運維和開發握手言和
作者:劉俊夏
在現在的 AI 大模型的橫行時代,如果你們公司的關聯著 AI 大模型的 K8s 集群資源出現了問題,你們應該如何解決呢?
引言
在現在的 AI 大模型的橫行時代,如果你們公司的關聯著 AI 大模型的 K8s 集群資源出現了問題,你們應該如何解決呢?
開始
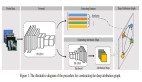
一、場景深度拆解:GPU節點的內存迷宮
1.1 GPU節點的資源隔離特性
GPU節點資源池:
├─ 設備資源(顯存):由NVIDIA/k8s-device-plugin管理,顯存分配嚴格隔離
├─ 系統內存:受cgroups控制,進程間可能發生隱性爭搶
└─ 內核資源:Page Cache、Socket Buffer等共享區域易被忽視1.2 典型矛盾點分析
 圖片
圖片
二、技術診斷:四步定位資源黑洞
2.1 節點級診斷(kubectl describe node)
# 查看節點資源分配詳情
kubectl describe node gpu-node-01 | grep -A 15 "Allocated resources"
---
Allocated resources:
(Total limits may be over 100 percent)
Resource Requests Limits
-------- -------- ------
cpu 48 (61%) 60 (76%)
memory 128Gi (85%) 150Gi (99%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
nvidia.com/gpu 8 8關鍵字段解析:
? Memory Limits總和接近100%:存在超售風險
? nvidia.com/gpu無超分:顯存隔離正常
? 實際使用量(需結合監控):可能出現請求/限制設置不合理
2.2 Pod級內存分析(結合docker stats)
# 獲取容器級實時內存占用
docker stats --no-stream --format "{{.Name}}\t{{.MemUsage}}"
---
ai-training-pod-1 15.2GiB / 16GiB
data-preprocess-pod 62GiB / 64GiB # 異常點!
model-serving-pod 3GiB / 4GiB異常識別技巧:
? 非GPU負載內存膨脹:如數據預處理Pod占用62GiB
? 內存用量接近Limit:觸發cgroup OOM的風險極高
2.3 內核級內存審計
# 查看Slab內存分配
cat /proc/meminfo | grep -E "SReclaimable|SUnreclaim"
---
SReclaimable: 123456 kB # 可回收內核對象
SUnreclaim: 789012 kB # 不可回收部分
# 檢查Page Cache占用
free -h | grep -E "total|Mem"
---
total used free shared buff/cache available
Mem: 251Gi 234Gi 2.0Gi 1.5Gi 14Gi 3.5Gi診斷結論:
? buff/cache異常低:Page Cache被強制回收,說明內存壓力極大
? SUnreclaim過高:可能存在內核對象泄漏
2.4 進程級內存分布
# 按內存排序進程
ps aux --sort=-%mem | head -n 5
---
USER PID %CPU %MEM VSZ RSS COMMAND
ai 1234 320 25% 100.3g 62g /usr/bin/python train.py # 數據預處理進程三、跨團隊協作:如何用數據說服各方
3.1 制作可視化證據鏈
// 提交給AI團隊的證據報告示例
{
"timestamp":"2024-03-20T14:00:00Z",
"node":"gpu-node-01",
"incident":"OOM Kill",
"evidence":{
"system_memory":{
"total":"251Gi",
"used":"234Gi (93.2%)",
"process_breakdown":{
"ai-training":"62Gi",
"data-preprocess":"128Gi",// 異常點!
"kernel":"44Gi"
}
},
"gpu_memory":{
"total":"80Gi",
"used":"64Gi (80%)"
}
}
}3.2 爭議焦點應對話術
? AI團隊質疑:"我們的模型顯存需求確實在合理范圍內"
? 運維團隊回應:
"數據顯示數據預處理階段的pandas操作占用了128Gi系統內存,這是顯存之外的獨立消耗。建議:
- 1. 為數據預處理Pod添加內存限制
- 2. 使用Dask替代pandas進行分塊處理
- 3. 增加預處理節點專項資源池"
四、緊急調度方案:三線應急措施
4.1 第一優先級:防止級聯故障
# 臨時驅逐非核心Pod(需確認業務容忍度)
kubectl drain gpu-node-01 --ignore-daemonsets --delete-emptydir-data --force
# 設置驅逐保護閾值
kubectl edit node gpu-node-01
---
apiVersion: v1
kind: Node
metadata:
annotations:
node.kubernetes.io/memory-pressure: "false" # 關閉kubelet驅逐4.2 第二優先級:關鍵負載保障
# 為AI訓練Pod設置最高優先級
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: ultra-high-priority
value: 1000000
globalDefault: false
description: "用于關鍵AI訓練任務"
# 應用優先級到Pod
spec:
priorityClassName: ultra-high-priority
containers:
- name: ai-training
resources:
limits:
memory: 16Gi
nvidia.com/gpu: 1
requests:
memory: 14Gi # 留出2Gi緩沖空間4.3 第三優先級:資源約束優化
# 數據預處理Pod的資源限制示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-preprocess
spec:
template:
spec:
containers:
- name: preprocess
resources:
limits:
memory: 32Gi # 原64Gi減半
cpu: "8"
requests:
memory: 28Gi
cpu: "6"
env:
- name: OMP_NUM_THREADS # 控制OpenMP并行度
value: "4"五、長效機制建設
5.1 資源配額分級策略
# 按團隊劃分GPU資源池
apiVersion: quotas.openshift.io/v1
kind: ClusterResourceQuota
metadata:
name: ai-team-quota
spec:
quota:
hard:
requests.nvidia.com/gpu: "16"
limits.memory: 200Gi
selector:
annotations:
team: ai5.2 動態調度優化
# 使用Descheduler平衡負載
kubectl apply -f https://github.com/kubernetes-sigs/descheduler/raw/master/kubernetes/base/crds/cluster-crd.yaml
# 配置策略文件
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
HighMemoryUtilization:
enabled: true
params:
nodeMemoryUtilizationThresholds:
thresholds:
memory: 855.3 監控體系增強
# Prometheus告警規則示例
- alert: MemoryFragmentation
expr: (node_memory_SUnreclaim / node_memory_MemTotal) > 0.3
for: 30m
labels:
severity: warning
annotations:
summary: "節點 {{ $labels.instance }} 內核內存碎片過高"六、根因修復建議
6.1 代碼級優化
# 數據預處理內存優化技巧
import dask.dataframe as dd # 替代pandas
# 分塊讀取數據
ddf = dd.read_parquet('input/', blocksize="256MB")
result = ddf.map_partitions(process_partition)6.2 內核參數調優
# 調整vm.swappiness減少OOM概率
echo 'vm.swappiness=10' >> /etc/sysctl.conf
# 擴大TCP緩沖區預防內核泄漏
echo 'net.ipv4.tcp_mem = 10240 87380 134217728' >> /etc/sysctl.conf6.3 硬件層解決方案
? 內存擴展:升級節點至1TB內存
? 存儲加速:配置Intel Optane持久內存作為Swap
? 分離部署:獨立數據預處理節點池
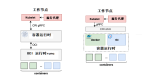
七、跨部門協作SOP
 圖片
圖片
通過以上方案,可將原本需要跨部門多日爭論的問題壓縮到4小時內解決,并建立預防性機制。具體實施時需根據業務場景調整參數,如需某環節的詳細操作手冊可進一步展開。
責任編輯:武曉燕
來源:
云原生運維圈