Redis 主從復制技術:理論基礎、運行邏輯與應用場景
在當今數字化時代,數據量呈爆炸式增長,對于應用程序而言,保障數據的高可用性和高性能變得至關重要。在眾多的解決方案中,Redis憑借其豐富的特性脫穎而出,而主從復制便是其中一項關鍵技術。
想象一下,一個大型電商平臺在促銷活動期間,海量的用戶請求如潮水般涌來。此時,單一的Redis實例很難應對如此巨大的流量壓力,而且一旦出現故障,整個系統可能會陷入癱瘓。Redis主從復制機制就如同為系統搭建了一道堅固的防線,通過復制主節點的數據到多個從節點,不僅提升了系統的讀取性能,還增強了數據的可靠性。
Redis主從復制是如何巧妙地實現數據同步的?在實際應用中又該如何進行配置和管理?不同節點之間的角色是如何協同工作的?接下來,就讓我們一同深入Redis主從復制的世界,揭開其神秘的面紗,探尋其中的奧秘。

一、詳解Redis主從復制
1. 主從復制的基本概念
主從復制就是將主節點(master)的數據復制到從節點(slave),讓多個節點承載用戶的請求:
主從復制具備以下幾個特點:
- 數據冗余:主節點的數據都會同步到從節點上,所以多個節點都會有相同數據,從而實現數據冗余。
- 故障恢復:主節點出現故障后,從節點可以繼續承載用戶的請求,做到服務上的冗余。
- 負載均衡:主從復制機制實現主節點接收用戶寫請求,從節點承載用戶讀請求,對于讀多寫少的場景,這種機制可以大大提高redis的并發量。
- 高負載:主從復制+哨兵機制可以實現高負載,這點后文會介紹到。
2. 主從復制使用示例
首先我們先來介紹一下一主二從,即搭建一個主節點和兩個從節點,主節點負責寫入請求,從節點同步數據對外提供數據讀服務:
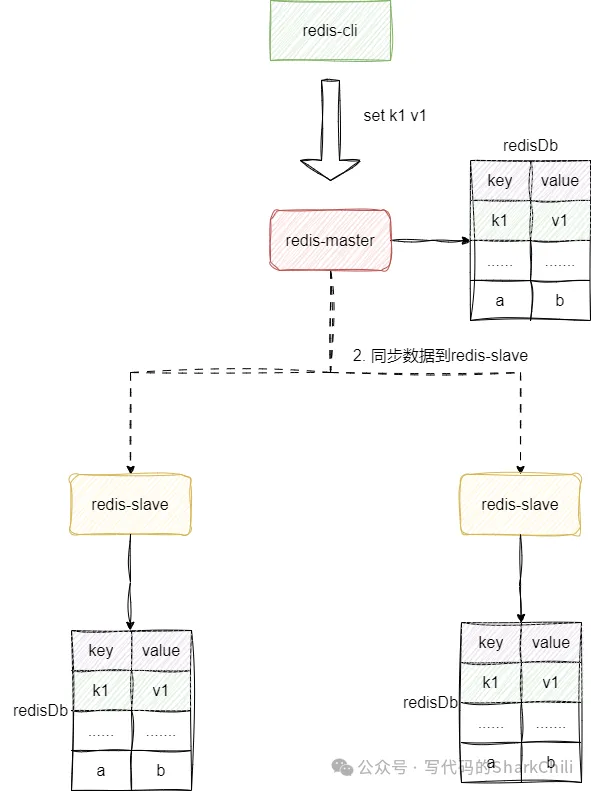
創建3個redis配置文件,以筆者為例,名字分別為redis6379.conf、redis6380.conf、redis6381.conf,同時我們將6379這個端口號的redis作為主節點,配置內容如下:
# 引入redis基本配置,注意這個配置只支持RDB
include /root/redis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
# 設置RDB文件名
dbfilename dump6379.rdb從節點以6380,配置如下:
# 引入redis基本配置,注意這個配置只支持RDB
include /root/redis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
# 作為6379的主節點
slaveof 127.0.0.1 6379分別啟動這幾個redis:
redis-server /root/redis/conf/redis6379.conf
redis-server /root/redis/conf/redis6380.conf
redis-server /root/redis/conf/redis6381.conf完成配置后,我們就可以開始測試了,首先對清空主節點數據,并設置一些值進去:
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set master_key value
OK
127.0.0.1:6379>我們看看從節點是否存在這個key值,可以發現這個值確實存在。
# 可以看到主節點的key來了
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> keys *
1) "master_key"
127.0.0.1:6380>再使用命令看看6380,發現其角色也確實是從節點:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
.... 略3. 演示主從復制運行時異常
從節點掛掉,在啟動,數據不會丟失,照樣是主節點的從節點,這個點我們也可以拿個例子來展示一下,首先我們可以將從節點掛掉:
# 強制掛掉從節點
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> SHUTDOWN
not connected>清空數據主節點設置一些新數據,再次啟動從節點,可以發現它還是從節點的角色:
# 啟動 發現數據都在,并且角色也是slave
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6380.conf
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
.....略主節點掛了,從節點仍然是從節點,主節點恢復后仍然是主節點。
這個例子,首先我們也是需要將主節點掛掉:
# 強制掛掉主節點
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected>完成后再次將主節點啟動,然后進行操作,發現角色仍然是master,而且進行各種set操作80這個從節點也會同步復制。
# 再次啟動主節點,發現key都在并且角色仍然是master,設置一個k2值
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6379.conf
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli
127.0.0.1:6379> set key2 v2
OK
127.0.0.1:6379>
# 從節點仍然可以收到,說明主節點仍然是6379
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> keys *
1) "key2"
2) "master_key"
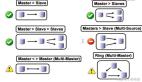
127.0.0.1:6380>4. 主從復制下的薪火相傳
如果大量主節點配合大量從節點,會導致主節點會導致數據同步時長增加,所以我們可以將部分從節點掛到某部分從節點下面,以此類推,作為從節點的從節點:

以筆者本次示例為例,我們將81作為80的從節點:
# 為了方便,筆者使用命令的形式,讀者也可以使用conf文件配置
127.0.0.1:6381> SLAVEOF 127.0.0.1 6380
OK
127.0.0.1:6381>再次查看80節點,可以看到slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=1,由此可知從節點的從節點配置完成:
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave
# 6381變為它的從節點
slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=15. 反客為主
對著從節點鍵入下面在這段命令,即直接讓從節點停止復制并直接晉升為主節點:
slaveof no one二、、主從復制進階知識點
1. 主從復制的原理
主從復制有兩種模式,我就先來說說全量復制吧,如下圖,整體步驟為:
- 從節點向主節點發送同步請求,因為不知道主庫的runID,并且不知道同步的偏移量是多少,所以參數分別為? -1,同步請求的指令為psync
- 主庫執行bgsave指令生成rdb指令,將數據發送給從庫,從庫為了保證數據一致性,會將數據清空,然后加載rdb文件,完成數據同步。在此期間,主庫收到的新數據都會被存入replication buffer中。
- 主庫會將replication buffer發送給從庫,完成最新數據的同步。

從 Redis 2.8 開始,因為網絡斷開導致數據同步中斷的情況,會采用增量復制的方式完成數據補充。
需要了解的是,當主從同步過程中因為網絡等問題發生中斷,repl_backlog_buffer會保存兩者之間差異的數據,如果從庫長時間沒有恢復,很可能出現該環形緩沖區數據被覆蓋進而出現增量復制失敗,只能通過全量復制的方式實現數據同步。
需要一個概念replication buffer,這個緩沖區用于存放用戶寫入的新指令,完成全量復制之后的數據都是通過這個buffer的數據傳輸實現數據增量同步。
2. 主服務器不進行持久化復制存在什么問題
設想下面這樣一個場景,主節點沒有使用RDB持久化,數據沒有持久化到磁盤,在此期間主節點掛掉又立刻恢復了,此時主節點所有數據都丟失了,從節點很可能會因此清空原本數據進而導致數據丟失。
3. 為什么主從復制使用RDB而不是AOF
RDB是二進制且壓縮過的文件,傳輸速度以及加載速度都遠遠快速AOF。且AOF存的都是指令非常耗費磁盤空間,加載時都是重放每個寫命令,非常耗時。需要注意的是RDB是按照時間間隔進行持久化,對于數據不敏感的場景我們還是建議使用RDB。
4. 什么是無磁盤復制模式
數據同步不經過主進程以及硬盤,直接創建一個新進程dump RDB數據到從節點。對于磁盤性能較差的服務器可以使用這種方式。配置參數為:
repl-diskless-sync no # 決定是否開啟無磁盤復制模式
repl-diskless-sync-delay 5 # 決定同步的時間間隔5. 為什么會有從庫的從庫設計
由上可知,主庫執行數據同步時,需要執行如下步驟:
- 生成rdb文件。
- 傳輸數據給從庫。
為避免主庫因為頻繁為大量從庫做同步導致性能下降,于是我們才引入從庫的從庫這一設計方案分散同步壓力:
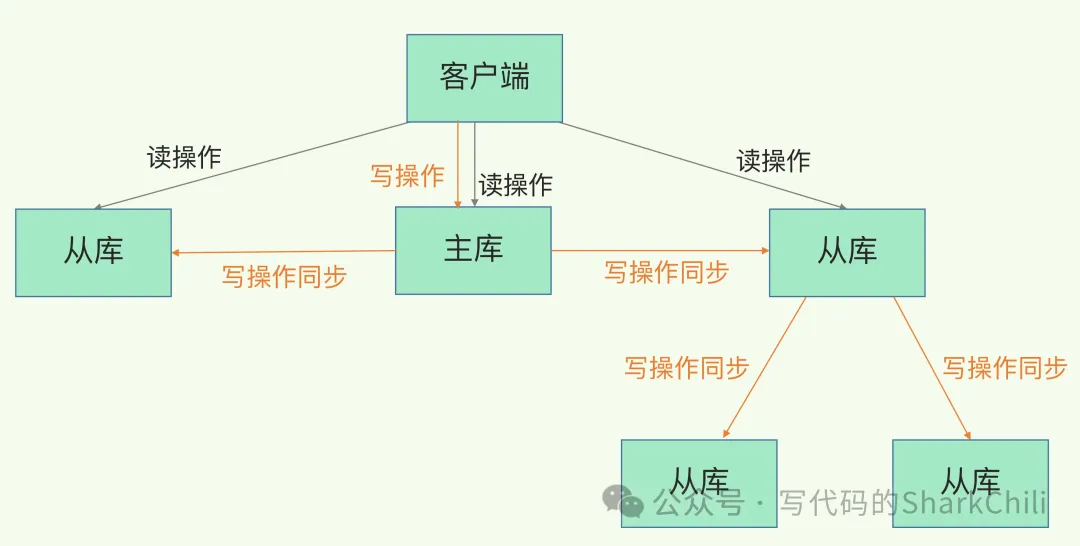
6. 讀寫分離及其中的問題
大抵需要考慮以下這些問題:
- 延遲與不一致問題:如果對數據一致性容忍度較低,網絡延遲導致數據不一致問題只能通過提高網絡帶寬,或者通知應用不在通過該節點獲取數據
- 數據過期問題,從節點很可能在某一時刻某些過期數據被讀取到了,這就會給用戶造成很詭異的場景。
- 故障切換問題
7. 如果在網絡斷開期間,repl_backlog_buffer 環形緩沖區寫滿之后,是進行全量還是增量復制
針對這個問題我們必須要了解repl_backlog_buffer是什么,它是redis主從同步時master的一個環形緩沖區,在master節點同步指令給slave時,這個緩沖區也會臨時緩沖這部分數據以保證slave斷線重連后的數據補償,針對該問題,我們需要分兩種情況說:
- 若主庫的repl_backlog_buffer的slave_repl_offset已經被覆蓋,那么同步就需要全量復制了
- 從庫會通過psync命令把自己記錄的slave_repl_offset發給主庫,主庫根據復制進度決定是增量復制還是全量復制。
8. 1主2從redis架構如何抗住1000w的qps
結合redis官方給出壓測報告來看,redis的qps基本在8w~15w這個區間,所以如果需要應對1000w的qps我們就需要考慮水平復制數據并拓展,按照壓測的情況并結合只需要抗住qps的需求,我們可以得出第一個方案——通過薪火相傳的架構來保證數據同步。
按照單機10w的qps來換算,我們可以通過100個redis節點搭建一個薪火相傳的架構抗住并發壓力:
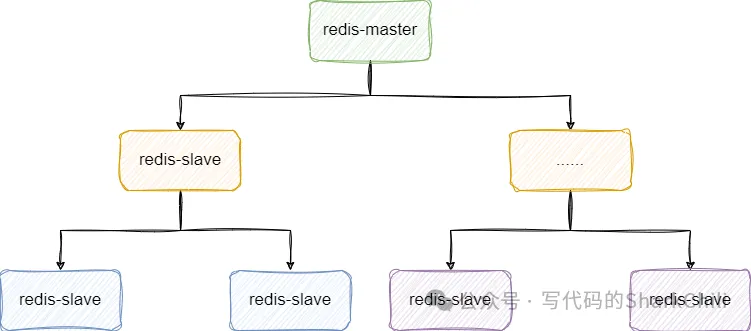
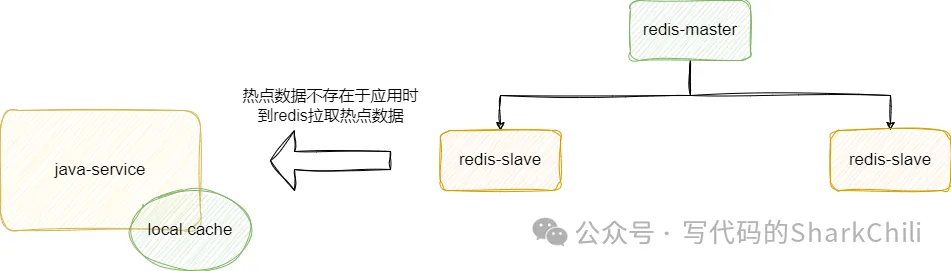
當然考慮到100個節點的成本可能不切實際,所以我們也可以采取另一套相對折中的方案,結合服務器資源部署一套redis主從架構+哨兵架構保證高可用,然后各個服務模塊基于本地內存到redis中同步熱點數據,讓應用直接對外提供緩存數據檢索,由此節約了資源成本還間接的減小的接口響應的RT: