RAG(七)Chain-of-Note:筆記鏈讓檢索增強型語言模型更強大!

現(xiàn)有的檢索增強型語言模型(Retrieval-Augmented Language Models, RALMs)在處理外部知識時存在一定的局限性。這些模型有時會因為檢索到不相關或不可靠的信息而產(chǎn)生誤導性的回答,或者在面對檢索信息和模型內(nèi)在知識的干擾時,無法正確選擇使用哪一種知識。此外,在檢索信息不足或完全不存在的情況下,標準的RALMs可能會嘗試生成一個答案,即使它們并不具備足夠的信息來準確作答。因此,來自Tecent AI Lab的一篇工作,提出CHAIN-OF-NOTE(CON),旨在通過生成一系列閱讀筆記來增強RALMs的魯棒性。
1、方法介紹
CHAIN-OF-NOTE的核心思想是通過創(chuàng)建順序閱讀筆記來對每個檢索文檔進行評估。這種方法不僅評估了每個文檔與查詢的相關性,還確定了這些文檔中最關鍵和可靠的信息。這個過程有助于過濾掉不相關或可信度較低的內(nèi)容,從而導致更準確和上下文相關的響應。
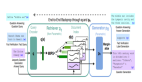
給定一個輸入問題x和k個檢索到的文檔 ,模型的目標是生成包含多個段落的文本輸出
,模型的目標是生成包含多個段落的文本輸出 。其中,
。其中, 表示第i個段落的標記,代表相應文檔
表示第i個段落的標記,代表相應文檔 的閱讀筆記,如圖2所示。在生成各個閱讀筆記后,模型綜合這些信息以生成最終的響應y。Chain-of-Note (CoN)的實現(xiàn)包括三個關鍵步驟:(1) 設計筆記
的閱讀筆記,如圖2所示。在生成各個閱讀筆記后,模型綜合這些信息以生成最終的響應y。Chain-of-Note (CoN)的實現(xiàn)包括三個關鍵步驟:(1) 設計筆記 ,(2) 收集數(shù)據(jù),(3) 訓練模型。
,(2) 收集數(shù)據(jù),(3) 訓練模型。

筆記設計
CON 主要構建三種類型的閱讀筆記,基于檢索文檔與輸入問題的相關性:
- 直接回答型筆記:當一個文檔直接回答了查詢時,模型基于此相關信息制定最終響應。(圖2a)
- 間接推斷型筆記:如果檢索文檔沒有直接回答查詢但提供了有用的上下文,模型利用這些信息及其內(nèi)在知識推斷答案。(圖2b)
- 未知型筆記:在檢索文檔無關且模型缺乏足夠知識的情況下,默認回復“未知”。(圖2c)
這種細致的方法模擬了人類信息處理的方式,在直接檢索、推理以及承認知識空白之間取得平衡。
數(shù)據(jù)收集
為了使模型能夠生成這樣的閱讀筆記,需要收集適當?shù)挠柧殧?shù)據(jù)。由于手動注釋資源密集,研究團隊使用 GPT-4 來生成筆記數(shù)據(jù)。具體步驟如下:
- 問題選取:首先從 NQ 數(shù)據(jù)集隨機抽取 10000 個問題。
- 筆記生成:然后用特定指令和情境例子提示 GPT-4 生成不同類型的筆記,確保覆蓋所有三種類型。

- 質(zhì)量評估:對小部分生成的數(shù)據(jù)進行人工評估以保證質(zhì)量。
模型訓練
使用這些數(shù)據(jù)訓練LLaMa2 7B模型,將指令、問題和文檔連接起來作為提示,模型學習順序生成每個文檔的閱讀筆記,以評估它們與輸入查詢的相關性,并基于文檔的相關性生成回答。
另外,為了減少CON推理成本,使用了一種稱為混合訓練的策略,將50%的訓練時間分配給標準RALM(直接生成答案,不使用筆記),另外50%分配給使用CON的RALM。這種策略允許模型在訓練期間內(nèi)化中間推理步驟。
在推理階段僅使用標準 RALM 提示來指導模型輸出答案,而不依賴顯式的閱讀筆記。這使得模型可以在保持相同推理速度的同時,只略微降低性能。
2、實驗結果
數(shù)據(jù)集
為了全面評估 Chain-of-Note 的性能,除NQ外,還在三個額外的開放域數(shù)據(jù)集上測試了其性能,包括TriviaQA、WebQ和RealTimeQA,展示了其對域外(OOD)數(shù)據(jù)的泛化能力。
- NQ (Natural Questions):一個大型的問答數(shù)據(jù)集,包含來自搜索引擎的真實用戶查詢。
- TriviaQA:一個涵蓋多個領域的事實性問題數(shù)據(jù)集。
- WebQ:一個基于網(wǎng)絡的問題回答數(shù)據(jù)集,主要涉及簡單的事實性問題。
- Real-TimeQA:作為特殊情況用于評估“未知”穩(wěn)健性,該數(shù)據(jù)集包括了2023年5月之后收集的問題,這些問題超出了 LLaMa-2 的預訓練知識范圍。
為了全面評估模型性能,實驗分為兩個部分:
- 全集評估:使用測試集中的所有問題來評估整體 QA 性能。文檔通過 DPR(Dense Passage Retrieval)檢索,并將 top-k 文檔輸入生成器。
- 子集評估:為了評估模型的噪聲穩(wěn)健性和未知穩(wěn)健性,從上述測試集中提取包含相關文檔的子集。根據(jù)噪音比率 r 確定相關和無關文檔的數(shù)量。例如,當噪音比率是 20% 且需要 top-5 文檔時,則 4 個為相關文檔,1 個為無關文檔。

整體 QA 性能評估
表2展示了不同模型在 NQ、TriviaQA 和 WebQ 上的整體表現(xiàn)。實驗結果表明,裝備CON的RALM在所有三個數(shù)據(jù)集上的平均EM分數(shù)提高了1.97%。
當DPR檢索到相關文檔時,平均改進為+1.2,當DPR未檢索到相關文檔時,NQ數(shù)據(jù)集的平均改進為+2.3。這一差異表明,CoN在檢索階段獲取更多噪聲文檔的情況下提高了RALM的性能。

噪聲穩(wěn)健性評估
實驗結果顯示,CON 方法在引入噪聲文檔后仍能保持較好的性能。在不同噪聲比例下,CON始終優(yōu)于標準RALM,尤其是在完全噪聲文檔的情況下。表明 CON 可以有效過濾無關信息,提高模型對噪聲數(shù)據(jù)的容忍度。

未知穩(wěn)健性評估
針對 Real-TimeQA 數(shù)據(jù)集的評估表明,CON 方法在面對超出預訓練知識范圍的問題時具有更好的“未知”穩(wěn)健性。具體表現(xiàn)為更高的拒絕率(RR),這意味著模型更傾向于承認自己的知識局限,而不是嘗試猜測答案。這一特性對于實際應用尤為重要,因為它減少了誤導性響應的風險。

混合訓練策略的效果
最后,混合訓練策略的效果也得到了驗證。實驗表明,經(jīng)過混合訓練的模型能夠在保持與純 CON 方法相似性能的同時,實現(xiàn)與標準 RALM 相同的推理時間。這意味著混合訓練不僅有效地降低了推理成本,還保留了 CON 在處理復雜查詢方面的優(yōu)勢。

3、總結
Chain-of-Note 技術通過構建詳細的閱讀筆記數(shù)據(jù)集,模擬人類的思考總結過程,增強了模型的推理能力。它在提高模型對噪聲數(shù)據(jù)的容忍度、增強未知穩(wěn)健性以及保持推理效率等方面表現(xiàn)出色,為檢索增強型語言模型的發(fā)展提供了新的思路和方法。然而,需要注意的是,微調(diào)可能會改變模型的參數(shù)分布,對于模型的通用能力的影響還有待進一步評估。
未來的研究可以關注如何更好地平衡模型的推理能力和通用能力,以及如何進一步優(yōu)化 Chain-of-Note 技術,使其在更多領域和應用場景中發(fā)揮更大的作用。