深入理解 Linux 內存優化:如何使用屏障提升性能
在當今快節奏的數字時代,無論是運行大型數據庫的服務器,還是流暢播放高清視頻的多媒體設備,亦或是精準控制生產流程的工業控制系統,其背后的 Linux 系統都肩負著高效管理內存的重任。內存管理,作為 Linux 內核的核心職能之一,就如同精密儀器中的齒輪組,有條不紊地協調著數據的存儲與讀取,為上層應用的穩定運行筑牢根基。
然而,隨著計算機硬件性能的突飛猛進,尤其是多核處理器的廣泛普及,內存訪問的復雜性也呈指數級增長。為了充分挖掘硬件潛力,提升系統整體性能,現代計算機往往采用亂序執行、緩存機制等優化手段。但這也帶來了新的挑戰:內存操作的順序可能變得難以捉摸,數據一致性問題時有發生,進而影響到應用程序的正確性與穩定性。
在這一背景下,內存優化屏障應運而生,它宛如一把精準的 “秩序之鎖”,巧妙地控制著內存操作的先后順序,確保在復雜的硬件架構與優化策略下,數據依然能夠按照開發者預期的方式流動。那么,內存優化屏障究竟是如何在 Linux 系統中發揮作用的?它又能為我們的應用性能帶來怎樣的提升?接下來,就讓我們一同揭開 Linux 內存優化屏障的神秘面紗,探尋其中的奧秘 。

一、內存屏障簡介
1. 內存屏障概述
在計算機系統中,為了提升性能,現代 CPU 和編譯器常常會對指令進行重排序。指令重排序是指在不改變程序最終執行結果的前提下,調整指令的執行順序,以充分利用 CPU 的資源,提高執行效率 。例如,當 CPU 執行一系列指令時,如果某些指令之間不存在數據依賴關系,CPU 可能會先執行后面的指令,再執行前面的指令。
在單線程環境下,指令重排序通常不會帶來問題,因為程序的執行結果仍然符合預期。然而,在多線程環境中,指令重排序可能會導致意想不到的結果,因為不同線程之間的操作可能會相互干擾。比如,線程 A 和線程 B 同時訪問共享內存,線程 A 對共享變量的修改可能不會立即被線程 B 看到,這就導致了數據可見性問題。
為了解決這些問題,內存優化屏障應運而生。內存優化屏障是一種特殊的指令或機制,它可以阻止 CPU 和編譯器對特定指令進行重排序,從而保證內存操作的順序性和可見性。通過使用內存優化屏障,程序員可以確保在多線程環境下,內存操作按照預期的順序執行,避免數據競爭和其他并發問題。
2. 為什么會出現內存屏障?
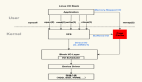
由于現在計算機存在多級緩存且多核場景,為了保證讀取到的數據一致性以及并行運行時所計算出來的結果一致,在硬件層面實現一些指令,從而來保證指定執行的指令的先后順序。比如上圖:雙核cpu,每個核心都擁有獨立的一二級緩存,而緩存與緩存之間需要保證數據的一致性所以這里才需要加添屏障來確保數據的一致性。三級緩存為各CPU共享,最后都是主內存,所以這些存在交互的CPU都需要通過屏障手段來保證數據的唯一性。
內存屏障存在的意義就是為了解決程序在運行過程中出現的內存亂序訪問問題,內存亂序訪問行為出現的理由是為了提高程序運行時的性能,Memory Bariier能夠讓CPU或編譯器在內存訪問上有序。
(1) 運行時內存亂序訪問
運行時,CPU本身是會亂序執行指令的。早期的處理器為有序處理器(in-order processors),總是按開發者編寫的順序執行指令, 如果指令的輸入操作對象(input operands)不可用(通常由于需要從內存中獲取), 那么處理器不會轉而執行那些輸入操作對象可用的指令,而是等待當前輸入操作對象可用。
相比之下,亂序處理器(out-of-order processors)會先處理那些有可用輸入操作對象的指令(而非順序執行) 從而避免了等待,提高了效率。現代計算機上,處理器運行的速度比內存快很多, 有序處理器花在等待可用數據的時間里已可處理大量指令了。即便現代處理器會亂序執行, 但在單個CPU上,指令能通過指令隊列順序獲取并執行,結果利用隊列順序返回寄存器堆(詳情可參考http:// http://en.wikipedia.org/wiki/Out-of-order_execution),這使得程序執行時所有的內存訪問操作看起來像是按程序代碼編寫的順序執行的, 因此內存屏障是沒有必要使用的(前提是不考慮編譯器優化的情況下)。
(2) SMP架構需要內存屏障的進一步解釋
從體系結構上來看,首先在SMP架構下,每個CPU與內存之間,都配有自己的高速緩存(Cache),以減少訪問內存時的沖突采用高速緩存的寫操作有兩種模式:
- 穿透(Write through)模式,每次寫時,都直接將數據寫回內存中,效率相對較低;
- 回寫(Write back)模式,寫的時候先寫回告訴緩存,然后由高速緩存的硬件再周轉復用緩沖線(Cache Line)時自動將數據寫回內存, 或者由軟件主動地“沖刷”有關的緩沖線(Cache Line)。
出于性能的考慮,系統往往采用的是模式2來完成數據寫入;正是由于存在高速緩存這一層,正是由于采用了Write back模式的數據寫入,才導致在SMP架構下,對高速緩存的運用可能改變對內存操作的順序。
已上面的一個簡短代碼為例:
// thread 0 -- 在CPU0上運行
x = 42;
ok = 1;
// thread 1 – 在CPU1上運行
while(!ok);
print(x);這里CPU1執行時, x一定是打印出42嗎?讓我們來看看以下圖為例的說明:
假設,正好CPU0的高速緩存中有x,此時CPU0僅僅是將x=42寫入到了高速緩存中,另外一個ok也在高速緩存中,但由于周轉復用高速緩沖線(Cache Line)而導致將ok=1刷會到了內存中,此時CPU1首先執行對ok內存的讀取操作,他讀到了ok為1的結果,進而跳出循環,讀取x的內容,而此時,由于實際寫入的x(42)還只在CPU0的高速緩存中,導致CPU1讀到的數據為x(17)。
程序中編排好的內存訪問順序(指令序:program ordering)是先寫入x,再寫入y。而實際上出現在該CPU外部,即系統總線上的次序(處理器序:processor ordering),卻是先寫入y,再寫入x(這個例子中x還未寫入)。
在SMP架構中,每個CPU都只知道自己何時會改變內存的內容,但是都不知道別的CPU會在什么時候改變內存的內容,也不知道自己本地的高速緩存中的內容是否與內存中的內容不一致。
反過來,每個CPU都可能因為改變了內存內容,而使得其他CPU的高速緩存變的不一致了。在SMP架構下,由于高速緩存的存在而導致的內存訪問次序(讀或寫都有可能書序被改變)的改變很有可能影響到CPU間的同步與互斥。
因此需要有一種手段,使得在某些操作之前,把這種“欠下”的內存操作(本例中的x=42的內存寫入)全都最終地、物理地完成,就好像把欠下的債都結清,然后再開始新的(通常是比較重要的)活動一樣。這種手段就是內存屏障,其本質原理就是對系統總線加鎖。
回過頭來,我們再來看看為什么非SMP架構(UP架構)下,運行時內存亂序訪問不存在。
在單處理器架構下,各個進程在宏觀上是并行的,但是在微觀上卻是串行的,因為在同一時間點上,只有一個進程真正在運行(系統中只有一個處理器)。
在這種情況下,我們再來看看上面提到的例子:
線程0和線程1的指令都將在CPU0上按照指令序執行。thread0通過CPU0完成x=42的高速緩存寫入后,再將ok=1寫入內存,此后串行的將thread0換出,thread1換入,及時此時x=42并未寫入內存,但由于thread1的執行仍然是在CPU0上執行,他仍然訪問的是CPU0的高速緩存,因此,及時x=42還未寫回到內存中,thread1勢必還是先從高速緩存中讀到x=42,再從內存中讀到ok=1。
綜上所述,在單CPU上,多線程執行不存在運行時內存亂序訪問,我們從內核源碼也可得到類似結論(代碼不完全摘錄)
#define barrier() __asm__ __volatile__("": : :"memory")
#define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
#ifdef CONFIG_SMP
#define smp_mb() mb()
#define smp_rmb() rmb()
#define smp_wmb() wmb()
#define smp_read_barrier_depends() read_barrier_depends()
#define set_mb(var, value) do { (void) xchg(&var, value); } while (0)
#else
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
#define smp_read_barrier_depends() do { } while(0)
#define set_mb(var, value) do { var = value; barrier(); } while (0)
#endif這里可看到對內存屏障的定義,如果是SMP架構,smp_mb定義為mb(),mb()為CPU內存屏障(接下來要談的),而非SMP架構時(也就是UP架構),直接使用編譯器屏障,運行時內存亂序訪問并不存在。
(3) 為什么多CPU情況下會存在內存亂序訪問?
我們知道每個CPU都存在Cache,當一個特定數據第一次被其他CPU獲取時,此數據顯然不在對應CPU的Cache中(這就是Cache Miss)。
這意味著CPU要從內存中獲取數據(這個過程需要CPU等待數百個周期),此數據將被加載到CPU的Cache中,這樣后續就能直接從Cache上快速訪問。
當某個CPU進行寫操作時,他必須確保其他CPU已將此數據從他們的Cache中移除(以便保證一致性),只有在移除操作完成后,此CPU才能安全地修改數據。
顯然,存在多個Cache時,必須通過一個Cache一致性協議來避免數據不一致的問題,而這個通信的過程就可能導致亂序訪問的出現,也就是運行時內存亂序訪問。
受篇幅所限,這里不再深入討論整個細節,有興趣的讀者可以研究《Memory Barriers: a Hardware View for Software Hackers》這篇文章,它詳細地分析了整個過程。
現在通過一個例子來直觀地說明多CPU下內存亂序訪問的問題:
volatile int x, y, r1, r2;
//thread 1
void run1()
{
x = 1;
r1 = y;
}
//thread 2
void run2
{
y = 1;
r2 = x;
}變量x、y、r1、r2均被初始化為0,run1和run2運行在不同的線程中。
如果run1和run2在同一個cpu下執行完成,那么就如我們所料,r1和r2的值不會同時為0,而假如run1和run2在不同的CPU下執行完成后,由于存在內存亂序訪問的可能,這時r1和r2可能同時為0。我們可以使用CPU內存屏障來避免運行時內存亂序訪問(x86_64):
void run1()
{
x = 1;
//CPU內存屏障,保證x=1在r1=y之前執行
__asm__ __volatile__("mfence":::"memory");
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU內存屏障,保證y = 1在r2 = x之前執行
__asm__ __volatile__("mfence":::"memory");
r2 = x;
}二、內存屏障核心原理
1.譯器優化與優化屏障
在程序編譯階段,編譯器為了提高代碼的執行效率,會對代碼進行優化,其中指令重排是一種常見的優化手段。例如,對于下面的 C 代碼:
int a = 1;
int b = 2;在沒有數據依賴的情況下,編譯器可能會將其編譯成匯編代碼時,交換這兩條指令的順序,先執行b = 2,再執行a = 1。在單線程環境下,這種重排通常不會影響程序的最終結果。但在多線程環境中,當多個線程共享數據時,這種重排可能會導致數據一致性問題 。
為了禁止編譯器對特定指令進行重排,Linux 內核提供了優化屏障機制。在 Linux 內核中,通過barrier()宏來實現優化屏障 。barrier()宏的定義如下:
#define barrier() __asm__ __volatile__("" ::: "memory")__asm__表示這是一段匯編代碼,__volatile__告訴編譯器不要對這段代碼進行優化,即不要改變其前后代碼塊的順序 。"memory"表示內存中的變量值可能會發生變化,編譯器不能使用寄存器中的值來優化,而應該重新從內存中加載變量的值。這樣,在barrier()宏之前的指令不會被移動到barrier()宏之后,之后的指令也不會被移動到之前,從而保證了編譯器層面的指令順序。
2. CPU 執行優化與內存屏障
現代 CPU 為了提高執行效率,采用了超標量體系結構和亂序執行技術。CPU 在執行指令時,會按照程序順序取出一批指令,分析找出沒有依賴關系的指令,發給多個獨立的執行單元并行執行,最后按照程序順序提交執行結果,即 “順序取指令,亂序執行,順序提交執行結果” 。
例如,當 CPU 執行指令A需要從內存中讀取數據,而這個讀取操作需要花費較長時間時,CPU 不會等待指令A完成,而是會繼續執行后續沒有數據依賴的指令B、C等,直到指令A的數據讀取完成,再繼續執行指令A的后續操作 。
雖然 CPU 的亂序執行可以提高執行效率,但在某些情況下,這種亂序執行可能會導致問題。比如,在多處理器系統中,一個處理器修改數據后,可能不會把數據立即同步到自己的緩存或者其他處理器的緩存,導致其他處理器不能立即看到最新的數據。為了解決這個問題,需要使用內存屏障來保證 CPU 執行指令的順序 。
內存屏障確保在屏障原語前的指令完成后,才會啟動原語之后的指令操作。在不同的 CPU 架構中,有不同的指令來實現內存屏障的功能。例如,在 X86 系統中,以下這些匯編指令可以充當內存屏障:
- 所有操作 I/O 端口的指令;
- 前綴lock的指令,如lock;addl $0,0(%esp),雖然這條指令本身沒有實際意義(對棧頂保存的內存地址內的內容加上 0),但lock前綴對數據總線加鎖,從而使該條指令成為內存屏障;
- 所有寫控制寄存器、系統寄存器或 debug 寄存器的指令(比如,cli和sti指令,可以改變eflags寄存器的IF標志);
- lfence、sfence和mfence匯編指令,分別用來實現讀內存屏障、寫內存屏障和讀 / 寫內存屏障;
- 特殊的匯編指令,比如iret指令,可以終止中斷或異常處理程序。
在 ARM 系統中,則使用ldrex和strex匯編指令實現內存屏障。這些內存屏障指令能夠阻止 CPU 對指令的亂序執行,確保內存操作的順序性和可見性,從而保證多線程環境下程序的正確執行。
三、內存屏障的多元類型與功能詳解
在 Linux 系統中,內存屏障主要包括通用內存屏障、讀內存屏障、寫內存屏障和讀寫內存屏障,它們各自在保證內存操作的順序性和可見性方面發揮著關鍵作用 。
1. 通用內存屏障
通用內存屏障(mb)確保在其之前的所有內存讀寫操作都在其之后的內存讀寫操作之前完成 。它保證了其前后的讀寫指令順序,防止編譯器和 CPU 對這些指令進行重排序。在 Linux 內核中,mb()函數被定義用來實現通用內存屏障,其定義如下:
#ifdef CONFIG_SMP
#define mb() asm volatile("mfence" ::: "memory")
#else
#define mb() barrier()
#endif在 SMP(對稱多處理)系統中,如果是 64 位 CPU 或支持mfence指令的 32 位 CPU,mb()宏被定義為asm volatile("mfence" ::: "memory") 。mfence指令是 x86 架構下的一條匯編指令,它會使 CPU 等待,直到之前所有的內存讀寫操作都完成,才會執行之后的內存操作,從而保證了內存操作的順序性。
asm volatile表示這是一段匯編代碼,并且禁止編譯器對其進行優化,::: "memory"告訴編譯器內存中的數據可能會被修改,不能依賴寄存器中的舊值 。在單處理器(UP)系統中,mb()被定義為barrier(),barrier()宏通過asm volatile("":::"memory")` 來實現,同樣是為了防止編譯器對內存操作進行重排序 。
2. 讀內存屏障
讀內存屏障(rmb)保證在其之前的所有讀操作都在其之后的讀操作之前完成 。它確保了讀指令的順序,防止讀操作被重排序。在多線程環境中,當多個線程同時讀取共享數據時,讀內存屏障可以保證每個線程讀取到的數據是按照預期的順序更新的 。
例如,在一個多線程程序中,線程 A 和線程 B 都需要讀取共享變量x和y的值,并且要求先讀取x,再讀取y。如果沒有使用讀內存屏障,由于指令重排序,線程 B 可能會先讀取y,再讀取x,導致讀取到的數據不符合預期 。通過在讀取x和y之間插入讀內存屏障,就可以保證線程 B 先讀取x,再讀取y,從而保證了數據的一致性 。
在 Linux 內核中,rmb()函數的定義如下:
#ifdef CONFIG_SMP
#define rmb() asm volatile("lfence" ::: "memory")
#else
#define rmb() barrier()
#endif在 SMP 系統中,如果是 64 位 CPU 或支持lfence指令的 32 位 CPU,rmb()宏被定義為asm volatile("lfence" ::: "memory") 。lfence指令是 x86 架構下的讀內存屏障指令,它保證了在其之前的讀操作都完成后,才會執行之后的讀操作 。在 UP 系統中,rmb()同樣被定義為barrier() 。
3. 寫內存屏障
寫內存屏障(wmb)保證在其之前的所有寫操作都在其之后的寫操作之前完成 。它確保了寫指令的順序,防止寫操作被重排序。在數據更新場景中,寫內存屏障尤為重要。例如,在一個多線程程序中,線程 A 需要先更新共享變量x,再更新共享變量y,并且要求其他線程能夠按照這個順序看到更新后的值 。
如果沒有使用寫內存屏障,由于指令重排序,其他線程可能會先看到y的更新,再看到x的更新,導致數據不一致 。通過在更新x和y之間插入寫內存屏障,就可以保證其他線程先看到x的更新,再看到y的更新,從而保證了數據的一致性 。
在 Linux 內核中,wmb()函數的定義如下:
#ifdef CONFIG_SMP
#define wmb() asm volatile("sfence" ::: "memory")
#else
#define wmb() barrier()
#endif在 SMP 系統中,如果是 64 位 CPU 或支持sfence指令的 32 位 CPU,wmb()宏被定義為asm volatile("sfence" ::: "memory") 。sfence指令是 x86 架構下的寫內存屏障指令,它保證了在其之前的寫操作都完成后,才會執行之后的寫操作 。在 UP 系統中,wmb()也被定義為barrier() 。
4. 讀寫內存屏障
讀寫內存屏障既保證了讀操作的順序,也保證了寫操作的順序 。它確保了在其之前的所有讀寫操作都在其之后的讀寫操作之前完成 。在一些復雜的數據結構讀寫場景中,讀寫內存屏障非常有用。例如,在一個多線程程序中,線程 A 需要先寫入數據到共享數據結構,然后讀取該數據結構中的其他部分;線程 B 則需要先讀取線程 A 寫入的數據,然后再寫入新的數據 。通過在這些讀寫操作之間插入讀寫內存屏障,可以保證線程 A 和線程 B 的讀寫操作按照預期的順序進行,避免數據競爭和不一致的問題 。
在 Linux 內核中,并沒有專門定義一個獨立的讀寫內存屏障函數,通常可以使用通用內存屏障mb()來實現讀寫內存屏障的功能,因為mb()同時保證了讀寫操作的順序 。
四、應用案例深度解析
1. 多核處理器環境下的同步
在多核處理器環境中,每個核心都有自己的高速緩存,當多個核心同時訪問共享內存時,就可能出現緩存一致性問題 。例如,核心 A 修改了共享內存中的數據,并將其寫入自己的緩存,但此時核心 B 的緩存中仍然是舊數據。如果核心 B 繼續從自己的緩存中讀取數據,就會讀到不一致的數據 。
為了解決這個問題,內存屏障被廣泛應用。內存屏障可以確保在屏障之前的內存操作都完成后,才會執行屏障之后的內存操作,從而保證了緩存一致性 。例如,在 X86 架構中,mfence指令可以作為內存屏障,它會使 CPU 等待,直到之前所有的內存讀寫操作都完成,才會執行之后的內存操作 。
在多線程編程中,當一個線程修改了共享數據后,通過插入內存屏障,可以確保其他線程能夠立即看到這個修改 。假設線程 A 和線程 B 共享一個變量x,線程 A 修改了x的值后,插入一個內存屏障,然后線程 B 讀取x的值,由于內存屏障的作用,線程 B 讀取到的一定是線程 A 修改后的最新值 。
2. 設備驅動開發中的應用
在設備驅動開發中,內存屏障也起著關鍵作用。設備驅動程序需要與硬件設備進行交互,而硬件設備的操作通常需要按照特定的順序進行 。例如,在對硬件寄存器進行操作時,必須確保先寫入配置信息,再啟動設備 。如果沒有內存屏障,編譯器和 CPU 可能會對這些操作進行重排序,導致設備無法正常工作 。
以串口驅動為例,在向串口發送數據時,需要先檢查串口發送緩沖區是否為空,然后再將數據寫入緩沖區 。如果這兩個操作被重排序,就可能導致數據丟失 。通過在這兩個操作之間插入內存屏障,可以確保先檢查緩沖區,再寫入數據,從而保證串口通信的正確性 。在 Linux 內核中,串口驅動代碼可能會如下實現:
// 檢查串口發送緩沖區是否為空
while (readl(serial_port + STATUS_REGISTER) & TX_FIFO_FULL);
// 插入寫內存屏障
wmb();
// 將數據寫入串口發送緩沖區
writel(data, serial_port + DATA_REGISTER);在這個例子中,wmb()函數作為寫內存屏障,確保了在寫入數據之前,先完成對緩沖區狀態的檢查,從而保證了串口驅動的正常工作 。
3. RCU 機制中的關鍵角色
RCU(Read - Copy - Update)機制是 Linux 內核中一種高效的同步機制,主要用于讀多寫少的場景 。在 RCU 機制中,內存屏障發揮著至關重要的作用 。
在 RCU 中,讀操作不需要加鎖,這大大提高了讀操作的效率 。然而,為了保證數據的一致性,在寫操作時需要采取一些特殊的措施 。當一個寫者需要更新數據時,它首先會創建一個數據的副本,在副本上進行修改,然后將修改后的副本替換原來的數據 。在這個過程中,內存屏障用于確保讀操作能夠看到正確的數據 。
例如,在 Linux 內核的鏈表操作中,經常會使用 RCU 機制 。當一個線程要向鏈表中插入一個新節點時,它會先創建新節點,設置好節點的指針,然后使用rcu_assign_pointer函數來更新鏈表的指針 。rcu_assign_pointer函數內部會使用內存屏障,確保在新節點的指針設置完成后,其他線程才能看到這個新節點 。這樣,在多線程環境下,讀線程可以在不加鎖的情況下安全地遍歷鏈表,而寫線程也可以在不影響讀線程的情況下更新鏈表,從而提高了系統的并發性能 。
4. 內存一致性模型
內存一致性模型(Memory Consistency Model)是用來描述多線程對共享存儲器的訪問行為,在不同的內存一致性模型里,多線程對共享存儲器的訪問行為有非常大的差別。這些差別會嚴重影響程序的執行邏輯,甚至會造成軟件邏輯問題。
不同的處理器架構,使用了不同的內存一致性模型,目前有多種內存一致性模型,從上到下模型的限制由強到弱:
- 順序一致性(Sequential Consistency)模型
- 完全存儲定序(Total Store Order)模型
- 部分存儲定序(Part Store Order)模型
- 寬松存儲(Relax Memory Order)模型
注意,這里說的內存模型是針對可以同時執行多線程的平臺,如果只能同時執行一個線程,也就是系統中一共只有一個CPU核,那么它一定是滿足順序一致性模型的。
對于內存的訪問,我們只關心兩種類型的指令的順序,一種是讀取,一種是寫入。對于讀取和加載指令來說,它們兩兩一起,一共有四種組合:
- LoadLoad:前一條指令是讀取,后一條指令也是讀取。
- LoadStore:前一條指令是讀取,后一條指令是寫入。
- StoreLoad:前一條指令是寫入,后一條指令是讀取。
- StoreStore:前一條指令是寫入,后一條指令也是寫入。
(1) 順序一致性模型
順序存儲模型是最簡單的存儲模型,也稱為強定序模型。CPU會按照代碼來執行所有的讀取與寫入指令,即按照它們在程序中出現的次序來執行。同時,從主存儲器和系統中其它CPU的角度來看,感知到數據變化的順序也完全是按照指令執行的次序。也可以理解為,在程序看來,CPU不會對指令進行任何重排序的操作。在這種模型下執行的程序是完全不需要內存屏障的。但是,帶來的問題就是性能會比較差,現在已經沒有符合這種內存一致性模型的系統了。
為了提高系統的性能,不同架構都會或多或少的對這種強一致性模型進行了放松,允許對某些指令組合進行重排序。注意,這里處理器對讀取或寫入操作的放松,是以兩個操作之間不存在數據依賴性為前提的,處理器不會對存在數據依賴性的兩個內存操作做重排序。
(2) 完全存儲定序模型
這種內存一致性模型允許對StoreLoad指令組合進行重排序,如果第一條指令是寫入,第二條指令是讀取,那么有可能在程序看來,讀取指令先于寫入指令執行。但是,對于其它另外三種指令組合還是可以保證按照順序執行。
這種模型就相當于前面提到的,在CPU和緩存中間加入了存儲緩沖,而且這個緩沖還是一個滿足先入先出(FIFO)的隊列。先入先出隊列就保證了對StoreStore這種指令組合也能保證按照順序被感知。
我們非常熟悉的X86架構就是使用的這種內存一致性模型。
(3) 部分存儲定序模型
這種內存一致性模型除了允許對StoreLoad指令組合進行重排序外,還允許對StoreStore指令組合進行重排序。但是,對于其它另外兩種指令組合還是可以保證按照順序執行。
這種模型就相當于也在CPU和緩存中間加入了存儲緩沖,但是這個緩沖不是先入先出的。
(4) 寬松存儲模型
這種內存一致性模型允許對上面說的四種指令組合都進行重排序。
這種模型就相當于前面說的,既有存儲緩沖,又有無效隊列的情況。
這種內存模型下其實還有一個細微的差別,就是所謂的數據依賴性的問題。例如下面的程序,假設變量A初始值是0:
CPU 0 | CPU 1 |
A = 1; | Q = P; |
<write barrier> | B = *Q; |
P = &A; |
五、使用注意事項與性能考量
1. 避免過度使用
雖然內存屏障是解決多線程環境下內存一致性問題的有力工具,但過度使用會對系統性能產生負面影響 。內存屏障會阻止 CPU 和編譯器對指令進行重排序,這在一定程度上限制了它們的優化能力,從而增加了指令執行的時間 。在一些不必要的場景中使用內存屏障,會導致性能下降 。
例如,在單線程環境中,由于不存在多線程并發訪問共享數據的問題,使用內存屏障是完全沒有必要的,這只會浪費系統資源 。在多線程環境中,如果共享數據的訪問沒有數據競爭問題,也不應隨意使用內存屏障 。比如,在一個多線程程序中,多個線程只是讀取共享數據,而不進行寫操作,此時使用內存屏障并不能帶來任何好處,反而會降低性能 。因此,在使用內存屏障時,需要仔細分析代碼的執行邏輯和數據訪問模式,確保只在必要的地方使用內存屏障,以避免不必要的性能損失 。
2. 選擇合適的屏障類型
不同類型的內存屏障在功能和適用場景上有所不同,因此根據具體的場景選擇合適的內存屏障類型至關重要 。如果只需要保證讀操作的順序,那么使用讀內存屏障(rmb)即可;如果只需要保證寫操作的順序,使用寫內存屏障(wmb)就足夠了 。在一些復雜的場景中,可能需要同時保證讀寫操作的順序,這時就需要使用通用內存屏障(mb)或讀寫內存屏障 。
例如,在一個多線程程序中,線程 A 需要先讀取共享變量x,再讀取共享變量y,并且要求這兩個讀操作按照順序進行,此時就可以在讀取x和y之間插入讀內存屏障 。如果線程 A 需要先寫入共享變量x,再寫入共享變量y,并且要求其他線程能夠按照這個順序看到更新后的值,那么就應該在寫入x和y之間插入寫內存屏障 。在一些涉及復雜數據結構讀寫的場景中,可能需要使用通用內存屏障來保證讀寫操作的順序 。
比如,在一個多線程程序中,線程 A 需要先寫入數據到共享鏈表,然后讀取鏈表中的其他部分,線程 B 則需要先讀取線程 A 寫入的數據,然后再寫入新的數據,這種情況下就可以使用通用內存屏障來確保線程 A 和線程 B 的讀寫操作按照預期的順序進行 。因此,在使用內存屏障時,需要根據具體的場景和需求,選擇合適的內存屏障類型,以充分發揮內存屏障的作用,同時避免不必要的性能開銷 。
3. 性能監測與優化
為了確保內存屏障的使用不會對系統性能造成過大的影響,使用工具監測內存屏障對性能的影響,并根據監測結果進行優化是很有必要的 。在 Linux 系統中,可以使用 perf 工具來監測內存屏障對性能的影響 。perf 是一個性能分析工具,它可以收集系統的性能數據,包括CPU使用率、內存訪問次數等 。通過使用perf 工具,可以了解內存屏障的使用對系統性能的影響,從而找到性能瓶頸,并進行優化 。
例如,可以使用 perf record 命令來收集性能數據,然后使用 perf report 命令來查看性能報告 。在性能報告中,可以看到各個函數的 CPU 使用率、內存訪問次數等信息,從而找到內存屏障使用較多的函數,并分析其對性能的影響 。如果發現某個函數中內存屏障的使用導致了性能下降,可以嘗試優化該函數的代碼,減少內存屏障的使用,或者選擇更合適的內存屏障類型 。
除了使用 perf 工具外,還可以通過代碼優化、算法改進等方式來提高系統性能 。例如,可以減少不必要的內存訪問,優化數據結構,提高代碼的并行性等 。通過綜合使用這些方法,可以有效地提高系統性能,確保內存屏障的使用不會對系統性能造成過大的影響 。