Redis集群全解析:從原理到實戰,如何構建高可用分布式緩存
作者:禿頭老W
Redis集群是應對高并發、大數據的利器,但“沒有銀彈”——需根據業務特點選擇方案。對于大多數企業,Redis Cluster是平衡性能與擴展性的最優解。如果你還在為單機Redis的性能焦慮,不妨從搭建一個3主3從的集群開始,邁向分布式緩存的新世界!
在大數據和高并發場景下,單機Redis的性能和容量逐漸捉襟見肘。如何實現數據的高可用、高擴展和高性能?Redis集群成為破局的關鍵。
1.Redis集群三大核心方案
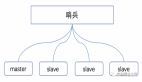
主從復制:簡單冗余背后的「心跳危機」
- 全量復制與增量復制主從首次連接時觸發全量復制:主節點通過BGSAVE生成RDB快照,同步期間新寫入命令存入復制緩沖區。從節點清空舊數據加載RDB后,主節點推送緩沖區積壓的增量命令完成同步。
- 致命缺陷:全量復制時主節點內存翻倍(生成RDB時fork子進程拷貝內存頁表),若主節點內存達10GB,復制期間可能導致OOM崩潰。
- 級聯復制緩解壓力通過“主-從-從”架構分攤壓力:指定高配從節點作為二級主節點,其他從節點向二級節點同步數據,避免主節點被多個從節點全量復制拖垮。
哨兵模式:高可用的「智能裁判」
- 主觀下線與客觀下線單個哨兵連續PING主節點超時(默認30秒)觸發主觀下線;當半數以上哨兵確認主節點故障,則升級為客觀下線。
- 腦裂防護:通過quorum參數控制故障判定閾值(如3哨兵集群需2票確認),避免網絡抖動誤判。
- 領導者選舉與故障轉移哨兵節點通過Raft協議選舉領導者,由領導者觸發故障轉移:
- 篩選健康從節點(數據同步偏移量最大者優先)
- 執行SLAVEOF NO ONE提升為新主節點
- 通知其他從節點切換主節點并更新客戶端路由。
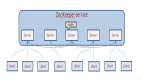
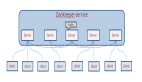
Redis Cluster:分布式架構的「終極答案」
數據分片:哈希槽的精密設計
- 16384槽位:采用CRC16算法計算鍵哈希值,取模16384確定槽位。槽位數量固定為16384(而非2的冪次)以降低元數據體積(僅需2KB存儲槽分布)。
- 槽分配策略:支持手動指定(CLUSTER ADDSLOTS)或自動均衡,適用于異構硬件環境(如SSD節點分配更多槽)。
橫向擴展:動態遷移的零停機藝術
- 新節點入群:redis-cli --cluster add-node將新節點加入集群
- 槽位重分配:redis-cli --cluster reshard交互式抽取舊節點槽位(如從3節點遷移4096槽至新節點)
- 原子遷移:逐個槽位遷移鍵值,期間客戶端訪問舊數據觸發ASK重定向,新數據直接寫入目標節點
- 元數據廣播:通過Gossip協議同步新槽位分布至全集群。
遷移性能優化
- 并行遷移:通過--cluster-from和--cluster-to指定多組源/目標節點并行遷移不同槽位
- 帶寬控制:redis-cli --cluster reshard時設置--cluster-pipeline參數限制批量傳輸大小。
故障自愈:主從切換的「無感體驗」
- 主節點宕機時,其從節點觸發選舉(基于配置紀元遞增),超過半數主節點投票后晉升為新主節點。客戶端通過MOVED重定向自動切換連接,全程業務無感知。
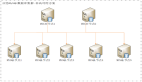
2.集群搭建實戰:從零到高可用
以Redis Cluster為例,6節點(3主3從)搭建步驟
配置節點
# 關鍵配置項(每個節點)
cluster-enabled yes # 啟用集群模式
cluster-config-file nodes.conf # 集群狀態文件
cluster-node-timeout 15000 # 節點超時時間(毫秒)[2,10](@ref)啟動集群
redis-cli --cluster create \
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 \
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1 # 每個主節點配1個從節點[3,10](@ref)驗證集群狀態
redis-cli -c -p 7000 cluster nodes # 查看節點與槽位分布
redis-cli --cluster check 127.0.0.1:7000 # 檢查健康狀態避坑指南:
- 端口開放:除服務端口(如7000)外,需開放集群總線端口(如17000)。
- 數據遷移:擴容時使用redis-cli --cluster reshard平滑遷移槽位,避免服務中斷。
3.選型與優化:告別“拍腦袋”決策
方案對比
方案 | 可用性 | 擴展性 | 運維復雜度 | 適用場景 |
主從復制 | 中 | 低 | 簡單 | 讀多寫少、容災要求低 |
哨兵模式 | 高 | 中 | 中等 | 中小規模高可用 |
Redis Cluster | 極高 | 高 | 復雜 | 大數據量、高并發 |
性能優化技巧
- 熱點數據:監控槽位負載,通過CLUSTER REBALANCE平衡數據分布。
- 內存控制:啟用appendonly yes持久化,避免節點重啟數據丟失。
- 網絡優化:集群節點部署在同一機房,減少跨網絡分區延遲。
4.Redis集群的典型應用場景
電商秒殺:集群分片扛住瞬時10萬級QPS。
實時推薦:分布式緩存支撐用戶畫像實時計算。
社交feed流:海量數據分片存儲,動態擴容應對用戶增長。
5.小結
Redis集群是應對高并發、大數據的利器,但“沒有銀彈”——需根據業務特點選擇方案。對于大多數企業,Redis Cluster是平衡性能與擴展性的最優解。如果你還在為單機Redis的性能焦慮,不妨從搭建一個3主3從的集群開始,邁向分布式緩存的新世界!
責任編輯:武曉燕
來源:
JAVA充電