Linux系列:聊一聊 SystemV 下的進程間共享內存
一、背景
1. 講故事
昨天在分析一個 linux 的 dump 時,看到了這么一話警告,參考如下:
0:000> !eeheap -gc
*** WARNING: Unable to verify timestamp for SYSV10cf21d1 (deleted)對,就是上面的 SYSV10cf21d1,拆分一下為 System V + 10cf21d1 ,前者的System V表示共享內存機制,后面的 10cf21d1 表示共享內存中用到的唯一鍵key,所以這表示當前的 .net 程序直接或者間接的使用了 System V的進程間共享內存,我對 Linux 不是特別熟悉,所以稍微研究了下就有了這篇文章。
二、System V 研究
1. 什么是進程間通信
其實在 Linux 中有很多中方式進行 IPC(進程間通信),我用大模型幫我做了一下匯總,截圖如下:
 圖片
圖片
現如今Linux使用最多的還是 POSIX 標準,而 System V 相對來說比較老,為了研究我們寫一個小例子觀察下基本實現。
2. System V 的一個小例子
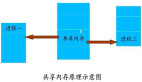
為了能夠實現進程間通信,開啟兩個進程(writer,reader)端,一個是往共享內存寫入,一個從共享內存中讀取,畫個簡圖如下:
 圖片
圖片
接下來在內存段的首位置設置控制flag,后面跟著傳輸的 content 內容,然后創建一個key與申請的內存段進行綁定,參考代碼如下:
1)writer.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define SHM_SIZE 1024 // 共享內存段大小
int main()
{
key_t key;
int shmid;
char *shm_ptr;
// 生成key值 - 使用當前目錄和項目ID
if ((key = ftok(".", 'x')) == -1)
{
perror("ftok");
exit(1);
}
// 創建共享內存段
if ((shmid = shmget(key, SHM_SIZE, IPC_CREAT | 0666)) == -1)
{
perror("shmget");
exit(1);
}
// 附加到共享內存
if ((shm_ptr = shmat(shmid, NULL, 0)) == (void *)-1)
{
perror("shmat");
exit(1);
}
printf("Writer: 連接到共享內存段 %d\n", shmid);
// 第一個字節作為標志位,其余部分存儲數據
char *flag_ptr = shm_ptr;
char *data_ptr = shm_ptr + 1;
// 初始化標志位
*flag_ptr = 0;
// 寫入數據到共享內存
char message[] = "Hello from writer process!";
strncpy(data_ptr, message, sizeof(message));
// 設置標志位表示數據已準備好
*flag_ptr = 1;
printf("Writer: 已寫入消息: \"%s\"\n", message);
// 等待讀取進程完成
printf("Writer: 等待讀取進程確認...\n");
while (*flag_ptr != 2)
{
sleep(1);
}
// 分離共享內存
if (shmdt(shm_ptr) == -1)
{
perror("shmdt");
exit(1);
}
// 刪除共享內存段
if (shmctl(shmid, IPC_RMID, NULL) == -1)
{
perror("shmctl");
exit(1);
}
printf("Writer: 完成\n");
return0;
}接下來就是 gcc 編譯并運行,參考如下:
root@ubuntu2404:/data2# gcc -g writer.c -o writer
root@ubuntu2404:/data2# ls
writer writer.c
root@ubuntu2404:/data2# ./writer
Writer: 連接到共享內存段 2
Writer: 已寫入消息: "Hello from writer process!"
Writer: 等待讀取進程確認...從輸出看已經將 "Hello from writer process!" 寫到了共享內存,接下來可以用 ipcs -m 觀察共享內存段列表,以及虛擬地址段。
root@ubuntu2404:/proc# ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x780300023 root 666 1024 1
root@ubuntu2404:/proc# ps -ef | grep writer
root 7711 7593010:41 pts/1 00:00:00 ./writer
root 7714 7618010:41 pts/2 00:00:00 grep --color=auto writer
root@ubuntu2404:/proc# cat /proc/7711/maps
5b412c9bc000-5b412c9bd000 r--p 0000000008:031966088 /data2/writer
5b412c9bd000-5b412c9be000 r-xp 0000100008:031966088 /data2/writer
5b412c9be000-5b412c9bf000 r--p 0000200008:031966088 /data2/writer
5b412c9bf000-5b412c9c0000 r--p 0000200008:031966088 /data2/writer
5b412c9c0000-5b412c9c1000 rw-p 0000300008:031966088 /data2/writer
5b415ad13000-5b415ad34000 rw-p 0000000000:000 [heap]
...
7c755ce80000-7c755ce81000 rw-s 0000000000:013 /SYSV78030002 (deleted)
...
ffffffffff600000-ffffffffff601000 --xp 0000000000:000 [vsyscall]
root@ubuntu2404:/proc#上面輸出的 /SYSV78030002 (deleted) 便是,哈哈,現在回頭看這句 WARNING: Unable to verify timestamp for SYSV10cf21d1 (deleted) 是不是豁然開朗啦。。。
接下來繼續聊,另一個進程要想讀取共享內存,需要通過同名的key尋找,即下面的 shmget 方法。
2)reader.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define SHM_SIZE 1024 // 共享內存段大小
int main()
{
key_t key;
int shmid;
char *shm_ptr;
// 生成相同的key值
if ((key = ftok(".", 'x')) == -1)
{
perror("ftok");
exit(1);
}
// 獲取共享內存段
if ((shmid = shmget(key, SHM_SIZE, 0666)) == -1)
{
perror("shmget");
exit(1);
}
// 附加到共享內存
if ((shm_ptr = shmat(shmid, NULL, 0)) == (void *)-1)
{
perror("shmat");
exit(1);
}
printf("Reader: 連接到共享內存段 %d\n", shmid);
// 第一個字節是標志位,其余是數據
char *flag_ptr = shm_ptr;
char *data_ptr = shm_ptr + 1;
// 等待數據準備好
printf("Reader: 等待數據...\n");
while (*flag_ptr != 1)
{
sleep(1);
}
// 讀取數據
printf("Reader: 接收到消息: \"%s\"\n", data_ptr);
// 通知寫入進程已完成讀取
*flag_ptr = 2;
// 分離共享內存
if (shmdt(shm_ptr) == -1)
{
perror("shmdt");
exit(1);
}
printf("Reader: 完成\n");
return0;
}如果有朋友對綁定邏輯(shmget)的底層感興趣,可以觀察 Linux 中的 ipcget_public 方法,其中的 rhashtable_lookup_fast 便是。
static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
/*
* Take the lock as a writer since we are potentially going to add
* a new entry + read locks are not "upgradable"
*/
down_write(&ids->rwsem);
ipcp = ipc_findkey(ids, params->key);
...
}
static struct kern_ipc_perm *ipc_findkey(struct ipc_ids *ids, key_t key)
{
struct kern_ipc_perm *ipcp;
ipcp = rhashtable_lookup_fast(&ids->key_ht, &key,
ipc_kht_params);
if (!ipcp)
returnNULL;
rcu_read_lock();
ipc_lock_object(ipcp);
return ipcp;
}最后就是相同方式的編譯運行,截一張圖如下:
 圖片
圖片
三、總結
哈哈,dump分析之旅就是這樣,在分析中不斷的學習新知識,再用新知識指導dump分析,就這樣的不斷的螺旋迭代,樂此不疲。