常用模型蒸餾方法:這 N 個核心,你都知道嗎?(上)
Hello folks,我是 Luga,今天我們來聊一下人工智能應用場景 - 構建高效、靈活、健壯的模型技術體系。
隨著深度學習模型規模的爆炸式增長,它們在各種任務上展現出令人驚嘆的性能。然而,龐大的參數量和計算需求也帶來了新的挑戰:如何在資源受限的設備上高效部署這些模型?如何降低推理延遲以滿足實時應用的需求?
模型蒸餾(Model Distillation)正是為解決這些問題而誕生的強大技術。它借鑒了人類學習過程中的“教學”理念,通過將一個大型、高性能的教師模型(Teacher Model)所學到的“知識”,有效地遷移到一個小型、高效的學生模型(Student Model)中。這樣一來,學生模型便能在保持輕量級結構的同時,盡可能地逼近甚至達到教師模型的性能水平,從而實現模型壓縮和加速的目的。
然而,模型蒸餾不僅是簡單的模型瘦身,更是一種深入的知識遷移。但究竟有哪些行之有效的蒸餾方法,能夠幫助我們訓練出“聰明”又“苗條”的學生模型呢?這些方法的核心原理和應用場景又是什么?

一、模型蒸餾(Model Distillation)主要分類
模型蒸餾(Model Distillation)是一種將復雜模型(通常稱為教師模型,Teacher Model)中的知識轉移到更輕量、高效模型(學生模型,Student Model)的技術。根據從教師模型中提取和傳遞信息的方式,模型蒸餾可以分為多種類型,每種類型都采用了獨特的方法來實現知識的遷移,從而在保持性能的同時顯著降低模型的計算復雜度和資源需求。
總體而言,模型蒸餾主要分為三種類型,每種類型都以不同的方式將教師模型的知識傳遞給學生模型,以適應不同的應用場景和性能優化需求。這三種類型分別是:
- 基于響應的蒸餾(Response-based Distillation):專注于模仿教師模型的最終輸出,通常以軟目標(Soft Targets)形式傳遞知識,幫助學生模型學習類別間的細微關系。
- 基于特征的蒸餾(Feature-based Distillation):通過提取教師模型中間層的特征表示(如激活值或特征圖),指導學生模型學習更深層次的語義信息。
- 基于關系的蒸餾(Relation-based Distillation):關注教師模型內部的結構化關系(如層間關系或樣本間關系),使學生模型不僅學習輸出,還能捕捉模型的內在邏輯。

二、基于響應的模型蒸餾(Response-based Model Distillation)
基于響應的模型蒸餾,通常也被稱為 Logit Distillation 或 Soft Target Distillation,是模型蒸餾領域中最經典和基礎的方法。它最早在 Hinton 等人于 2015 年發表的論文 "Distilling the Knowledge in a Neural Network" 中被提出。其核心思想是訓練學生模型去模仿教師模型的最終輸出響應(通常是 softmax 層之前的 logits 或經過溫度縮放后的概率分布),而不是僅僅模仿真實的硬標簽(hard labels)。
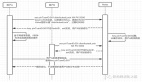
基于響應的模型蒸餾是最常見且易于實現的模型蒸餾類型,它依賴于教師模型的輸出。與直接進行主要預測不同,學生模型的訓練目標是模仿教師模型的預測結果。這一過程分為兩個步驟,如圖 2 所示:

步驟一:首先,訓練教師模型。或者,如前所述,也可以使用預訓練模型,將其蒸餾到更小的模型中。
步驟二:其次,促使教師模型生成“軟目標”(soft targets)。隨后,應用蒸餾算法訓練學生模型,使其預測與教師模型相同的軟標簽,并最小化兩者輸出之間的差異(即蒸餾損失,Distillation Loss,我們稍后會詳細討論)。通過這種方式,學生模型從教師模型的輸出中學習,而不是直接從訓練數據中學習,從而在計算能力和內存使用效率更高的同時,達到與教師模型相似的準確性。
基于響應的蒸餾過程使用一個轉移數據集(transfer data set),從教師模型和學生模型中分別生成邏輯輸出(logits),并根據兩者邏輯輸出之間的差異計算蒸餾損失,以訓練學生模型。具體如圖 2 所示:基于響應的蒸餾過程使用轉移數據集生成教師模型和學生模型的邏輯輸出,并通過計算兩者之間的差異來定義蒸餾損失,以優化學生模型。
模型蒸餾的一個關鍵點在于軟目標(soft targets)的使用。與傳統的硬目標訓練方法(使用獨熱編碼的類別標簽)不同,模型蒸餾采用軟目標,即所有可能類別上的概率分布。
想象一下,你正在訓練一個用于將動物圖像分類為牛、狗、貓和鳥四種類別的模型。在傳統的硬目標訓練中,每個圖像的標簽使用獨熱編碼。例如,對于一張狗的圖像,標簽為 [0, 1, 0, 0]。然而,在使用軟目標的訓練中,教師模型提供所有類別的概率分布。對于狗的圖像,軟目標可能是 [10??, 0.9, 0.1, 10??],反映了教師模型對每個類別的置信度。
這些軟目標提供了類別間關系的細微信息,使學生模型能夠更有效地學習。例如,每個概率可以通過 softmax 函數估算,該函數依賴一個溫度因子 T 來控制目標的“軟度”。溫度因子作用于教師模型的邏輯輸出之前,生成概率分布。較高的溫度產生更柔和的概率分布,而較低的溫度則使分布更尖銳。
隨后,學生模型通過最小化其預測結果與教師模型輸出之間的差異來進行訓練。這涉及最小化損失函數,在訓練過程中,學生模型的目標函數通常包含兩部分:
1. 蒸餾損失 (Distillation Loss):
計算學生模型的輸出響應與教師模型的輸出響應之間的差異。常用的損失函數包括:
KL 散度 (Kullback-Leibler Divergence): 用于衡量兩個概率分布之間的差異。教師和學生的 logits 都會先通過一個帶有“溫度”參數 (τ) 的 softmax 層進行“軟化”,然后計算它們輸出概率分布之間的 KL 散度。溫度 τ>1 會使概率分布更平滑,提供更豐富的類別間關聯信息(即教師模型的“暗知識”)。
均方誤差 (Mean Squared Error): 直接計算教師和學生模型輸出 logits 之間的 MSE。
2. 學生損失 (Student Loss / Hard Target Loss):
計算學生模型的輸出與真實硬標簽之間的差異,通常使用交叉熵損失。
最終的總訓練損失是蒸餾損失和學生損失的加權求和:
Ltotal=αLdistillation+βLstudent
其中 α 和 β 是權重系數,用來平衡兩種損失的重要性。通常在蒸餾訓練中,溫度參數 τ 在蒸餾損失和學生損失的 softmax 計算中都保持一致,但在推理階段,學生模型使用 τ=1 的標準 softmax。
基于上述所述,完整的基于響應的模型蒸餾流程可參考如下所示:

三、基于響應的模型蒸餾(Response-based Model Distillation)
基于響應的模型蒸餾(Response-based Model Distillation)是最經典的蒸餾范式之一,其核心在于指導學生模型模仿教師模型的最終輸出(如 Logits 或軟化的概率分布)。這種方法具有以下優勢
1. 易于實現與集成
基于響應的蒸餾方法因其概念直觀和實現簡單而備受青睞。其核心僅涉及修改損失函數(通過引入軟目標和蒸餾損失),無需調整教師模型或學生模型的網絡架構。這種設計使其能夠無縫集成到現有深度學習訓練流程中,例如 PyTorch 或 JAX 的標準訓練 Pipeline。
開發者只需通過 Hugging Face Transformers 加載預訓練教師模型(如 BERT),即可利用其 logits 生成軟目標,快速啟動蒸餾過程。
2. 增強模型理解力
與硬標簽僅提供單一類別信息不同,教師模型的軟化輸出(通過較高溫度的 softmax 生成)包含了豐富的“暗知識”(Dark Knowledge)。這些知識反映了樣本與其他類別的相似性,例如狗和貓的概率分布可能更接近,而狗和鳥的分布差異較大。這種信息幫助學生模型更好地理解類別邊界和數據結構,從而學習到更魯棒的特征表示。
同時,結合 LangChain 的 Graph Index,學生模型可通過軟目標進一步捕捉樣本間關系,提升語義理解能力。
3. 顯著提升學生模型性能
在分類任務中,基于響應的蒸餾能夠顯著提升學生模型的性能,使其準確率接近甚至達到教師模型的水平,遠超直接使用硬標簽訓練的基線模型。這種性能提升得益于學生模型從教師模型的軟目標中學習到的類別分布信息。
例如,在 CIFAR-10 數據集上,使用軟目標的學生模型可能將準確率從 85%(硬標簽訓練)提升至 92%,接近教師模型的 94%。
4. 廣泛適用于分類任務
基于響應的蒸餾方法天然適配幾乎所有分類任務,包括多分類、情感分析和圖像分類等,其基于概率分布的損失函數設計與分類問題高度契合。
同時結合 JAX 的 jax.vmap 向量化功能,可高效處理大規模分類任務中的批次數據,使得在教育、醫療或金融領域的分類應用中,該方法提供了靈活的解決方案。
基于響應的模型蒸餾以其簡單性、性能提升和正則化效果在分類任務中表現出色,特別適合快速部署和資源優化場景。然而,其對教師模型質量的依賴、信息傳遞的局限性以及對非分類任務的適用性不足限制了其廣泛應用。具體可參考如下:
(1) 訓練過程中教師模型的高計算成本
學生模型的訓練需要持續運行教師模型的前向傳播以生成軟目標,這顯著增加了計算開銷和顯存占用。特別是當教師模型規模龐大(如 GPT-3)或轉移數據集較大時,訓練成本可能成為瓶頸。
因此,即使使用 DeepSpeed 的 ZeRO 技術優化教師模型的分布式訓練,生成軟目標的推理過程仍需占用大量 GPU 資源,例如對百萬條記錄的推理可能需要數小時。
(2) 溫度因子(τ)調優的敏感性
溫度因子(τ)對蒸餾效果的影響較大,需要仔細調優。較低的 τ 使軟目標接近硬標簽,傳遞的信息有限;過高的 τ 則導致概率分布過于平滑,類別間的差異變得不明顯,學生模型難以學習有效的決策邊界。
此外,調優 τ 通常需要多次實驗,例如在 NLP 任務中,τ=2 可能適合小數據集,而 τ=10 更適合大數據集。
(3) 無法充分利用中間特征或樣本間關系
基于響應的蒸餾無法捕捉教師模型中間層的特征表示(如卷積層的特征圖)或樣本間的關系(如樣本相似性),這些信息在基于特征或關系的蒸餾中被證明對性能提升有重要作用。
今天的解析就到這里,欲了解更多關于 Helm-Import 相關技術的深入剖析,最佳實踐以及相關技術前沿,敬請關注我們的微信公眾號:架構驛站,獲取更多獨家技術洞察!
Happy Coding ~
Reference :
- [1] https://dodonam.tistory.com/364
- [2] https://medium.com/data-science-collective/understanding-model-distillation-in-large-language-models-with-code-examples-557b1012d2eb
Adiós !