記一次生產環境中 Kafka 集群面對消息量飆升后獲得五倍性能提升的優化之旅
前幾天我碰到了一個Kafka集群在消息量突然飆升時遇到的性能瓶頸問題,經過幾個小時的苦戰后,集群恢復了平穩運行,性能提升了5倍,本文將詳細闡述從問題發現、分析到最終解決的完整過程。

一、第一部分:問題發現
1. 告警觸發
周一早上9:00,監控系統突然觸發了多項Kafka集群告警:
- 消息積壓量急劇上升,部分主題的消費延遲從毫秒級增加到分鐘級
- 生產者客戶端報告大量請求超時錯誤
- Broker的CPU使用率飆升至90%以上
- 網絡流量激增,接近物理網卡限制
- 磁盤I/O使用率達到峰值
2. 初步情況評估
運維團隊立即展開初步調查,發現:
- 集群配置:5個broker節點,每個節點16核CPU,64GB內存,10Gbps網絡,RAID10磁盤陣列
- 主要業務主題的分區數:30個,副本因子為3
- 正常情況下,集群處理能力約為每秒50,000條消息
- 當前情況:消息生產速率突然飆升至每秒200,000條,是平時的4倍
- 消費者組處理速度明顯滯后,無法跟上生產速度
3. 業務影響評估
- 多個關鍵業務系統報告數據處理延遲
- 用戶交易確認時間延長,部分交易出現超時
- 數據分析平臺無法及時獲取最新數據
- 實時監控系統數據更新滯后
二、第二部分:問題分析
1. 日志分析
首先檢查Kafka服務器日志,發現大量警告和錯誤信息:
WARN [ReplicaManager brokerId=1] Produce request with correlation id 12345 from client client1 on partition topic1-15 failed due to request timeout
ERROR [KafkaRequestHandlerPool-0] Error when handling request: clientId=client2, correlationId=23456, api=PRODUCE
java.lang.OutOfMemoryError: Java heap space
WARN [ReplicaFetcherThread-0-3] Error in fetch from broker 3 for partition topic2-5這些日志表明集群正面臨嚴重的資源壓力,包括請求處理超時、內存不足和副本同步問題。
2. JVM監控分析
通過JVM監控工具分析broker進程:
- 堆內存使用率接近90%,頻繁觸發Full GC
- GC暫停時間從正常的幾十毫秒增加到幾百毫秒
- 年輕代內存分配速率異常高,表明有大量對象創建
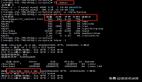
3. 系統資源分析
使用系統監控工具分析各節點資源使用情況:
- CPU:用戶空間使用率85%,系統空間15%,幾乎沒有空閑
- 內存:物理內存使用率95%,部分節點開始使用swap
- 磁盤I/O:寫入速度接近物理極限,讀取隊列長度持續增加
- 網絡:入站流量8.5Gbps,接近10Gbps的物理限制
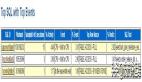
4. Kafka指標分析
通過Kafka內置指標和JMX監控,發現以下關鍵問題:
請求隊列積壓:
- 請求隊列大小(request-queue-size)持續增長,表明網絡線程無法及時處理請求
- 網絡處理線程CPU使用率接近100%
磁盤I/O瓶頸:
- 日志刷盤延遲(log-flush-rate-and-time-ms)顯著增加
- 磁盤寫入操作頻繁阻塞
副本同步問題:
- ISR收縮事件頻繁發生,表明副本無法跟上leader的寫入速度
- 副本同步延遲(replica-lag)持續增加
消息批處理效率低下:
- 平均批次大小(batch-size-avg)遠低于配置的最大值
- 生產者請求頻率過高,導致網絡和處理開銷增加
5. 客戶端配置分析
檢查生產者客戶端配置,發現以下問題:
- 批處理大小(batch.size)設置過小,默認為16KB
- linger.ms設置為0,導致消息立即發送而不等待批處理
- 壓縮類型設置為none,未啟用任何壓縮
- 生產者緩沖區(buffer.memory)設置不足,僅為32MB
檢查消費者客戶端配置:
- 消費者拉取大小(fetch.max.bytes)設置過小,限制了單次拉取的數據量
- 消費者線程數不足,無法充分利用多核處理能力
- 消費者組重平衡策略不合理,導致頻繁的分區重分配
6. 根因分析
綜合以上分析,確定了以下核心問題:
(1) 資源配置不足:
- Broker的JVM堆內存配置不足以應對突發流量
- 網絡線程和I/O線程數量不足,無法充分利用多核CPU
(2) 參數配置不合理:
- 生產者批處理和壓縮配置不合理,導致網絡和處理效率低下
- 消費者拉取配置限制了消費速度
- Broker端隊列大小限制不足以應對突發流量
(3) 主題分區設計不合理:
- 熱點主題分區數量不足,無法充分利用并行處理能力
- 分區分布不均衡,導致部分broker負載過重
(4) 監控預警不及時:
- 缺乏對生產速率變化的有效監控和預警機制
- 沒有針對突發流量的自動擴容策略
三、第三部分:緊急優化方案
基于上述分析,制定了分階段的緊急優化方案:
1. 第一階段:立即緩解壓力(0-2小時)
(1) 增加關鍵資源配置
增加JVM堆內存:
# 修改Kafka啟動腳本中的KAFKA_HEAP_OPTS
export KAFKA_HEAP_OPTS="-Xms16G -Xmx16G"優化GC配置:
# 添加以下GC參數
export KAFKA_JVM_PERFORMANCE_OPTS="-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent"增加網絡和I/O線程數:修改server.properties配置
# 增加網絡線程數,從默認的3增加到16
num.network.threads=16
# 增加I/O線程數,從默認的8增加到32
num.io.threads=32
# 增加請求隊列大小
queued.max.requests=1000調整請求處理參數:
# 增加socket接收緩沖區
socket.receive.buffer.bytes=1048576
# 增加socket發送緩沖區
socket.send.buffer.bytes=1048576
# 增加最大請求大小
max.request.size=10485760(2) 優化生產者客戶端配置
為主要生產者應用緊急推送配置更新:
# 增加批處理大小
batch.size=131072
# 設置linger.ms使消息有時間進行批處理
linger.ms=50
# 啟用壓縮
compression.type=lz4
# 增加生產者緩沖區
buffer.memory=536870912
# 增加重試次數和重試間隔
retries=10
retry.backoff.ms=100(3) 優化消費者客戶端配置
為主要消費者應用緊急推送配置更新:
# 增加單次拉取大小
fetch.max.bytes=52428800
# 增加最大拉取等待時間
fetch.max.wait.ms=500
# 增加消費者緩沖區大小
max.partition.fetch.bytes=10485760(4) 臨時限流措施
為非關鍵業務實施臨時限流:
// 在生產者客戶端實施限流
Properties props = new Properties();
props.put("throttle.rate", "10000"); // 每秒限制10000條消息2. 第二階段:系統優化(2-6小時)
(1) 增加熱點主題分區數
為熱點主題增加分區數,提高并行處理能力:
# 使用kafka-topics.sh工具增加分區數
bin/kafka-topics.sh --bootstrap-server broker1:9092 --alter --topic hot-topic --partitions 60(2) 重平衡分區分配
執行分區重分配,優化分區在broker間的分布:
# 生成分區重分配計劃
bin/kafka-reassign-partitions.sh --bootstrap-server broker1:9092 --generate --topics-to-move-json-file topics.json --broker-list "1,2,3,4,5"
# 執行分區重分配
bin/kafka-reassign-partitions.sh --bootstrap-server broker1:9092 --execute --reassignment-json-file reassignment.json(3) 優化日志配置
修改server.properties配置,優化日志處理:
# 增加日志段大小,減少小文件數量
log.segment.bytes=1073741824
# 優化日志刷盤策略,避免頻繁刷盤
log.flush.interval.messages=50000
log.flush.interval.ms=10000
# 優化日志清理線程數
log.cleaner.threads=4(4) 調整副本同步參數
# 增加副本拉取線程數
num.replica.fetchers=8
# 增加副本拉取大小
replica.fetch.max.bytes=10485760
# 調整ISR收縮時間,避免頻繁的ISR變化
replica.lag.time.max.ms=30000(5) 實施動態配置調整
利用Kafka的動態配置功能,無需重啟即可調整關鍵參數:
# 使用kafka-configs.sh工具動態調整配置
bin/kafka-configs.sh --bootstrap-server broker1:9092 --entity-type brokers --entity-name 1 --alter --add-config "num.io.threads=32,num.network.threads=16"3. 第三階段:架構優化(6-24小時)
(1) 擴展集群規模
緊急添加新的broker節點,擴展集群處理能力:
# 配置新的broker節點
# server.properties for new brokers
broker.id=6
listeners=PLAINTEXT://new-broker:9092
...
# 啟動新節點
bin/kafka-server-start.sh config/server.properties(2) 實施主題分區遷移
將部分熱點主題的分區遷移到新節點:
# 生成遷移計劃,將部分分區遷移到新節點
bin/kafka-reassign-partitions.sh --bootstrap-server broker1:9092 --generate --topics-to-move-json-file hot-topics.json --broker-list "1,2,3,4,5,6"
# 執行遷移計劃
bin/kafka-reassign-partitions.sh --bootstrap-server broker1:9092 --execute --reassignment-json-file migration.json(3) 優化存儲架構
將日志目錄分散到多個物理磁盤:
# 配置多個日志目錄,分散I/O壓力
log.dirs=/data1/kafka-logs,/data2/kafka-logs,/data3/kafka-logs,/data4/kafka-logs為不同類型的主題配置不同的存儲策略:
# 為高吞吐量主題配置專用存儲策略
bin/kafka-configs.sh --bootstrap-server broker1:9092 --entity-type topics --entity-name high-throughput-topic --alter --add-config "retention.ms=86400000,cleanup.policy=delete"
# 為需要長期保存的主題配置壓縮策略
bin/kafka-configs.sh --bootstrap-server broker1:9092 --entity-type topics --entity-name archive-topic --alter --add-config "cleanup.policy=compact"(4) 實施客戶端架構優化
改進生產者設計:
// 實現異步批量發送模式
public class OptimizedProducer {
private final KafkaProducer<String, String> producer;
private final ScheduledExecutorService scheduler;
private final ConcurrentLinkedQueue<ProducerRecord<String, String>> messageQueue;
private final int batchSize;
public OptimizedProducer(Properties props, int batchSize) {
this.producer = new KafkaProducer<>(props);
this.scheduler = Executors.newScheduledThreadPool(1);
this.messageQueue = new ConcurrentLinkedQueue<>();
this.batchSize = batchSize;
// 定時批量發送
this.scheduler.scheduleAtFixedRate(this::sendBatch, 100, 100, TimeUnit.MILLISECONDS);
}
public void send(String topic, String key, String value) {
messageQueue.add(new ProducerRecord<>(topic, key, value));
if (messageQueue.size() >= batchSize) {
sendBatch();
}
}
private void sendBatch() {
List<ProducerRecord<String, String>> batch = new ArrayList<>();
ProducerRecord<String, String> record;
while ((record = messageQueue.poll()) != null && batch.size() < batchSize) {
batch.add(record);
}
for (ProducerRecord<String, String> r : batch) {
producer.send(r, (metadata, exception) -> {
if (exception != null) {
// 處理失敗,重新入隊或記錄日志
messageQueue.add(r);
}
});
}
producer.flush();
}
}優化消費者處理模型:
// 實現多線程消費處理模型
public class ParallelConsumer {
private final Consumer<String, String> consumer;
private final ExecutorService executor;
private final int numWorkers;
public ParallelConsumer(Properties props, int numWorkers) {
this.consumer = new KafkaConsumer<>(props);
this.numWorkers = numWorkers;
this.executor = Executors.newFixedThreadPool(numWorkers);
}
public void start(String topic, MessageProcessor processor) {
consumer.subscribe(Collections.singleton(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
// 將記錄分組,并行處理
List<Future<?>> futures = new ArrayList<>();
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
futures.add(executor.submit(() -> {
for (ConsumerRecord<String, String> record : partitionRecords) {
processor.process(record);
}
}));
}
// 等待所有處理完成
for (Future<?> future : futures) {
try {
future.get();
} catch (Exception e) {
// 處理異常
}
}
// 手動提交偏移量
consumer.commitSync();
}
}
}
public interface MessageProcessor {
void process(ConsumerRecord<String, String> record);
}
}(5) 實施主題分區策略優化
根據消息流量特征重新設計分區策略:
# 為高流量主題增加分區數
bin/kafka-topics.sh --bootstrap-server broker1:9092 --alter --topic high-traffic-topic --partitions 100
# 為關鍵業務主題增加副本因子
bin/kafka-topics.sh --bootstrap-server broker1:9092 --alter --topic critical-topic --replica-assignment "1:2:3:4:5,2:3:4:5:1,..."實施自定義分區器,避免熱點分區:
public class BalancedPartitioner implements Partitioner {
private Random random = new Random();
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 隨機分區
return random.nextInt(numPartitions);
} else {
// 使用一致性哈希算法,但避免熱點
int hashCode = Arrays.hashCode(keyBytes);
return Math.abs(hashCode) % numPartitions;
}
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}