Python接口優化,性能飆升25倍!

背景
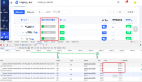
我們負責的一個業務平臺,有次在發現設置頁面的加載特別特別地慢,簡直就是令人發指
讓用戶等待 36s 肯定是不可能的,于是我們就要開啟優化之旅了。
投石問路
既然是網站的響應問題,可以通過 Chrome 這個強大的工具幫助我們快速找到優化方向。
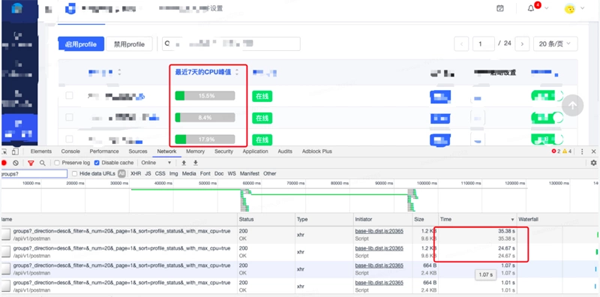
通過 Chrome 的 Network 除了可以看到接口請求耗時之外,還能看到一個時間的分配情況,選擇一個配置沒有那么多的項目,簡單請求看看:
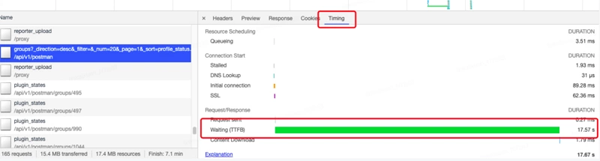
雖然只是一個只有三條記錄的項目,加載項目設置都需要 17s,通過 Timing, 可以看到總的請求共耗時 17.67s ,但有 17.57s 是在 Waiting(TTFB) 狀態。
- TTFB 是 Time to First Byte 的縮寫,指的是瀏覽器開始收到服務器響應數據的時間(后臺處理時間+重定向時間),是反映服務端響應速度的重要指標。
Profile 火焰圖 + 代碼調優
那么大概可以知道優化的大方向是在后端接口處理上面,后端代碼是 Python + Flask 實現的,先不盲猜,直接上 Profile:

第一波優化:功能交互重新設計
說實話看到這段代碼是絕望的:完全看不出什么?只是看到很多 gevent 和 Threading,因為太多協程或者線程?
這時候一定要結合代碼來分析(為了簡短篇幅,參數部分用 “...” 代替):
- def get_max_cpus(project_code, gids):
- """
- """
- ...
- # 再定義一個獲取 cpu 的函數
- def get_max_cpu(project_setting, gid, token, headers):
- group_with_machines = utils.get_groups(...)
- hostnames = get_info_from_machines_info(...)
- res = fetchers.MonitorAPIFetcher.get(...)
- vals = [
- round(100 - val, 4)
- for ts, val in res['series'][0]['data']
- if not utils.is_nan(val)
- ]
- maxmax_val = max(vals) if vals else float('nan')
- max_cpus[gid] = max_val
- # 啟動線程批量請求
- for gid in gids:
- t = Thread(target=get_max_cpu, args=(...))
- threads.append(t)
- t.start()
- # 回收線程
- for t in threads:
- t.join()
- return max_cpus
通過代碼可以看到,為了更加快速獲取 gids 所有的 cpu_max 數據,為每個 gid 分配一個線程去請求,最終再返回最大值。
這里會出現兩個問題:
- 在一個 web api 做線程的 創建 和 銷毀 是有很大成本的,因為接口會頻繁被觸發,線程的操作也會頻繁發生,應該盡可能使用線程池之類的,降低系統花銷;
- 該請求是加載某個 gid (群組) 下面的機器過去 7 天的 CPU 最大值,可以簡單拍腦袋想下,這個值不是實時值也不是一個均值,而是一個最大值,很多時候可能并沒有想象中那么大價值;
既然知道問題,那就有針對性的方案:
- 調整功能設計,不再默認加載 CPU 最大值,換成用戶點擊加載(一來降低并發的可能,二來不會影響整體);
- 因為 1 的調整,去掉多線程實現;
再看第一波優化后的火焰圖:
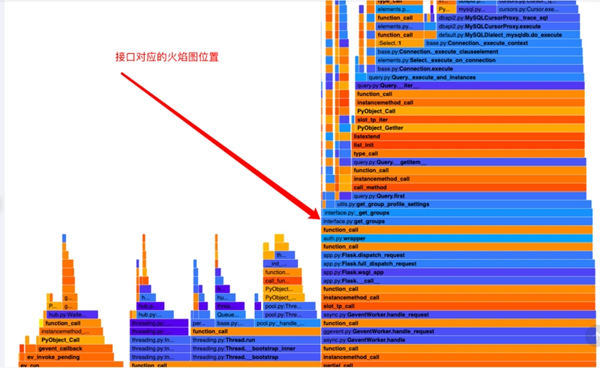
這次看的火焰圖雖然還有很大的優化空間,但起碼看起來有點正常的樣子了。
第二波優化:Mysql 操作優化處理
我們再從頁面標記處(接口邏輯處)放大火焰圖觀察:

看到好大一片操作都是由 utils.py:get_group_profile_settings 這個函數引起的數據庫操作熱點。
同理,也是需要通過代碼分析:
- def get_group_profile_settings(project_code, gids):
- # 獲取 Mysql ORM 操作對象
- ProfileSetting = unpurview(sandman.endpoint_class('profile_settings'))
- session = get_postman_session()
- profile_settings = {}
- for gid in gids:
- compound_name = project_code + ':' + gid
- result = session.query(ProfileSetting).filter(
- ProfileSetting.name == compound_name
- ).first()
- if result:
- resultresult = result.as_dict()
- tag_indexes = result.get('tag_indexes')
- profile_settings[gid] = {
- 'tag_indexes': tag_indexes,
- 'interval': result['interval'],
- 'status': result['status'],
- 'profile_machines': result['profile_machines'],
- 'thread_settings': result['thread_settings']
- }
- ...(省略)
- return profile_settings
看到 Mysql ,第一個反應就是 索引問題,所以優先去看看數據庫的索引情況,如果有索引的話應該不會是瓶頸:
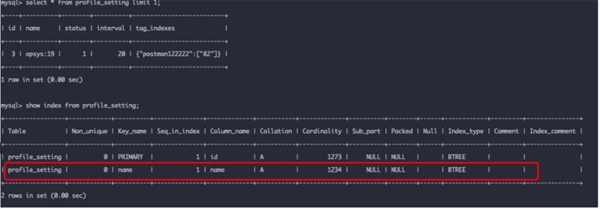
很奇怪這里明明已經有了索引了,為什么速度還是這個鬼樣子呢!
正當毫無頭緒的時候,突然想起在 第一波優化 的時候, 發現 gid(群組)越多的影響越明顯,然后看回上面的代碼,看到那句:
- for gid in gids:
- ...
我仿佛明白了什么。
這里是每個 gid 都去查詢一次數據庫,而項目經常有 20 ~ 50+ 個群組,那肯定直接爆炸了。
其實 Mysql 是支持單字段多值的查詢,而且每條記錄并沒有太多的數據,我可以嘗試下用 Mysql 的 OR 語法,除了避免多次網絡請求,還能避開那該死的 for
正當我想事不宜遲直接搞起的時候,余光瞥見在剛才的代碼還有一個地方可以優化,那就是:

看到這里,熟悉的朋友大概會明白是怎么回事。
GetAttr 這個方法是Python 獲取對象的 方法/屬性 時候會用到,雖然不可不用,但是如果在使用太過頻繁也會有一定的性能損耗。
結合代碼一起來看:
- def get_group_profile_settings(project_code, gids):
- # 獲取 Mysql ORM 操作對象
- ProfileSetting = unpurview(sandman.endpoint_class('profile_settings'))
- session = get_postman_session()
- profile_settings = {}
- for gid in gids:
- compound_name = project_code + ':' + gid
- result = session.query(ProfileSetting).filter(
- ProfileSetting.name == compound_name
- ).first()
- ...
在這個遍歷很多次的 for 里面,session.query(ProfileSetting) 被反復無效執行了,然后 filter 這個屬性方法也被頻繁讀取和執行,所以這里也可以被優化。
總結下的問題就是:
- 1. 數據庫的查詢沒有批量查詢;
- 2. ORM 的對象太多重復的生成,導致性能損耗;
- 3. 屬性讀取后沒有復用,導致在遍歷次數較大的循環體內頻繁 getAttr,成本被放大;
那么對癥下藥就是:
- def get_group_profile_settings(project_code, gids):
- # 獲取 Mysql ORM 操作對象
- ProfileSetting = unpurview(sandman.endpoint_class('profile_settings'))
- session = get_postman_session()
- # 批量查詢 并將 filter 提到循環之外
- query_results = query_instance.filter(
- ProfileSetting.name.in_(project_code + ':' + gid for gid in gids)
- ).all()
- # 對全部的查詢結果再單條處理
- profile_settings = {}
- for result in query_results:
- if not result:
- continue
- resultresult = result.as_dict()
- gid = result['name'].split(':')[1]
- tag_indexes = result.get('tag_indexes')
- profile_settings[gid] = {
- 'tag_indexes': tag_indexes,
- 'interval': result['interval'],
- 'status': result['status'],
- 'profile_machines': result['profile_machines'],
- 'thread_settings': result['thread_settings']
- }
- ...(省略)
- return profile_settings
優化后的火焰圖:
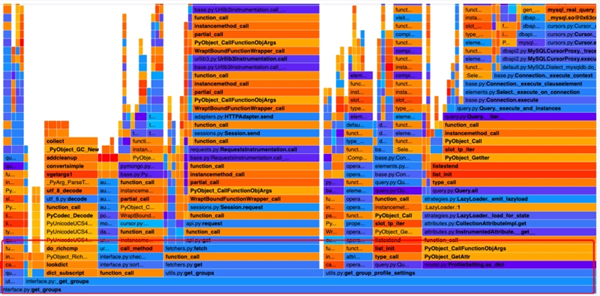
對比下優化前的相同位置的火焰圖:

明顯的優化點:優化前的,最底部的 utils.py:get_group_profile_settings 和 數據庫相關的熱點大大縮減。
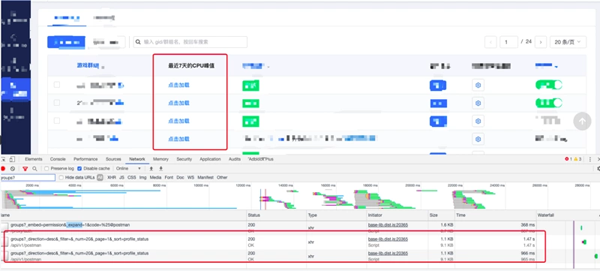
優化效果
同一個項目的接口的響應時長從 37.6 s 優化成 1.47s,具體的截圖:
優化總結
如同一句名言:
- 如果一個數據結構足夠優秀,那么它是不需要多好的算法。
在優化功能的時候,最快的優化就是:去掉那個功能!
其次快就是調整那個功能觸發的 頻率 或者 復雜度!
從上到下,從用戶使用場景去考慮這個功能優化方式,往往會帶來更加簡單高效的結果,嘿嘿!
當然很多時候我們是無法那么幸運的,如果我們實在無法去掉或者調整,那么就發揮做程序猿的價值咯:Profile
針對 Python 可以嘗試:cProflile + gprof2dot
而針對 Go 可以使用: pprof + go-torch
很多時候看到的代碼問題都不一定是真正的性能瓶頸,需要結合工具來客觀分析,這樣才能有效直擊痛點!
其實這個 1.47s,其實還不是最好的結果,還可以有更多優化的空間,比如:
- 前端渲染和呈現的方式,因為整個表格是有很多數據組裝后再呈現的,響應慢的單元格可以默認先顯示 菊花,數據返回再更新;
- 火焰圖看到還有挺多細節可以優化,可以替換請求數據的外部接口,比如再優化徹底 GetAttr 相關的邏輯;
- 更極端就是直接 Python 轉 GO;
但是這些優化已經不是那么迫切了,因為這個 1.47s 是比較大型項目的優化結果了,絕大部分的項目其實不到 1s 就能返回
再優化可能付出更大成本,而結果可能也只是從 500ms 到 400ms 而已,結果并不那么高性價比。
所以我們一定要時刻清晰自己優化的目標,時刻考慮 投入產出比,在有限的時間做出比較高的價值(如果有空閑時間當然可以盡情干到底)