MongoDB從入門到實戰之MongoDB工作常用操作命令
今天我們主要是了解一下在日常工作中 MongoDB 一些常用的操作命令,主要是在Docker中的MongoDB容器中做演示,大多數命令在Navicat中也是可以直接執行的。

1. 進入創建的MongoDB容器
docker ps -- 查看MongoDB容器
docker exec -it mongo-test mongosh -- 進入MondoDB容器中
2. 數據庫常用命令
(1) Help指令幫助
help #命令提示符
db.help() #數據庫方法幫助信息
db.mycoll.help() #集合方法幫助信息
(2) 切換/創建數據庫
#假如已經存在的數據庫會直接切換到指定的數據庫
use testDb
#當創建一個新的數據庫需要創建一個集合(table)的時候才會把數據庫持久化到磁盤中
【可能一開始創建數據庫時,是在內存中的,還沒有持久化到磁盤。新建集合時,就持久化了】
use testDb
db.createCollection("mybooks")(3) 數據庫查看
show dbs #查看所有數據庫
db 或 db.getName() #查看當前使用的數據庫(4) 顯示當前db狀態
db.stats()(5) 查看當前db版本
db.version()(6) 查看當前db的連接服務器機器地址
db.getMongo()(7) 刪除當前使用數據庫
db.dropDatabase()(8) 查詢之前的錯誤信息和清除
db.getPrevError()
db.resetError()3. Collection集合創建、查看、刪除
(1) 集合創建
db.createCollection("MyBooks") #MyBooks集合名稱(2) 查看當前數據庫中的所有集合
show collections(3) 集合刪除
db.MyBooks.drop() #MyBooks要刪除的集合名稱4. Document文檔增刪改查
(1) 文檔插入
① insert多個文檔插入:
MongoDB使用insert() 方法向集合中插入一個或多個文檔,語法如下:
db.COLLECTION_NAME.insert(document)注意:insert(): 若插入的數據主鍵已經存在,則會拋 org.springframework.dao.DuplicateKeyException 異常,提示主鍵重復,不保存當前數據。
② 示例:
添加數據源:
[{
name: "追逐時光者",
phone: "15012454678"
}, {
name: "王亞",
phone: "18687654321"
}, {
name: "大姚",
phone: "13100001111"
}, {
name: "小袁",
phone: "131054545541"
}]多條文檔數據插入:
db.Contacts.insert([{
name: "追逐時光者",
phone: "15012454678"
}, {
name: "王亞",
phone: "18687654321"
}, {
name: "大姚",
phone: "13100001111"
}, {
name: "小袁",
phone: "131054545541"
}])
查看插入文檔數據:
db.Contacts.find()
③ insertOne一個文檔插入:
insert() 方法可以同時插入多個文檔,但如果您只需要將一個文檔插入到集合中的話,可以使用 insertOne() 方法,該方法的語法格式如下:
db.COLLECTION_NAME.insertOne(document)④ 示例:
添加數據源:
{
bookName: "平凡的世界",
author: "路遙"
}添加示例:
db.MyBooks.insertOne({
bookName: "平凡的世界",
author: "路遙"
})
(2) 文檔更新
update() 方法用于更新已存在的文檔。語法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)參數說明:
- query:update的查詢條件,類似sql update查詢內where后面的。
- update:update的對象和一些更新的操作符(如$、$inc...)等,也可以理解為sql update查詢內set后面的。
- upsert:可選,這個參數的意思是,如果不存在update的記錄,是否插入objNew,true為插入,默認是false,不插入。
- multi:可選,mongodb 默認是false,只更新找到的第一條記錄,如果這個參數為true,就把按條件查出來多條記錄全部更新。
- writeConcern:可選,拋出異常的級別。
示例:
更改bookName:"平方的世界"書籍名稱改成“平方的世界”

db.MyBooks.update({'bookName':'平方的世界'},{$set:{'bookName':'平凡的世界'}})修改成功后的結果:

(3) 文檔查詢
MongoDB 查詢數據的語法格式如下:
db.collection.find(query, projection)- query:可選,使用查詢操作符指定查詢條件
- projection:可選,使用投影操作符指定返回的鍵。查詢時返回文檔中所有鍵值,只需省略該參數即可(默認省略)。
如果你需要以易讀的方式來讀取數據,可以使用 pretty() 方法,語法格式如下:
db.col.find().pretty()pretty() 方法以格式化的方式來顯示所有文檔。
① 查詢Contacts集合中的所有數據:
db.Contacts.find().pretty()
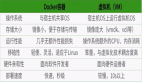
② MongoDB 與 RDBMS Where 語句比較:
如果你熟悉常規的 SQL 數據,通過下表可以更好的理解 MongoDB 的條件語句查詢:

③ MongoDB AND 條件:
MongoDB 的 find() 方法可以傳入多個鍵(key),每個鍵(key)以逗號隔開,即常規 SQL 的 AND 條件。
語法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()④ 查詢集合(Contacts)中name="小袁" 和 phnotallow="131054545541"記錄:
db.Contacts.find({"name":"小袁", "phone":"131054545541"}).pretty()
⑤ MongoDB OR 條件:
MongoDB OR 條件語句使用了關鍵字 $or,語法格式如下:
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()查詢集合(Contacts)中name="小袁" 或 name="大姚"記錄:
db.Contacts.find({$or:[{"name":"小袁"},{"name": "大姚"}]}).pretty()
⑥ AND 和 OR 聯合使用:
以下實例演示了 AND 和 OR 聯合使用,類似常規 SQL 語句為: 'where age>18 AND ("name"="小袁" OR "name"="大姚")':
db.Contacts.find({"age": {$gt:18}, $or: [{"name":"小袁"},{"name": "大姚"}]}).pretty()
(4) 文檔刪除
remove() 方法的基本語法格式如下所示:
db.collection.remove(
<query>,
{
justOne: <boolean>, writeConcern: <document>
}
)參數說明:
- query:必選項,是設置刪除的文檔的條件。
- justOne:布爾型的可選項,默認為false,刪除符合條件的所有文檔,如果設為 true,則只刪除一個文檔。
- writeConcem:可選項,設置拋出異常的級別。
① 根據某個_id值刪除數據:
#_id為字符串的話,可以直接這樣
db.collection.remove({"_id":"你的id"});
#_id由MongoDB自己生成時
db.collection.remove({'_id':ObjectId("636680729003374f6a6c7add")})
② 移除 title 為“MongoDB”的文檔:
db.colection.remove({'title': 'MongoDB'})5. MongoDB Limit與Skip方法
(1) Contacts集合數據展示

(2) MongoDB Limit方法
如果你需要在MongoDB中讀取指定數量的數據記錄,可以使用MongoDB的Limit方法,limit()方法接受一個數字參數,該參數指定從MongoDB中讀取的記錄條數。
語法:
limit()方法基本語法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER)示例:
查詢Contacts集合中的前兩條數據:
注意:如果沒有指定limit()方法中的參數則顯示集合中的所有數據。
db.Contacts.find().limit(2)
(3) MongoDB Skip方法
我們除了可以使用limit()方法來讀取指定數量的數據外,還可以使用skip()方法來跳過指定數量的數據,skip方法同樣接受一個數字參數作為跳過的記錄條數。
語法:skip() 方法腳本語法格式如下:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)示例:
查詢Contacts集合中的第2條數據:
# 顯示一條如何在跳過一條
db.Contacts.find().limit(1).skip(1)
6. MongoDB排序
在MongoDB 中使用 sort() 方法對數據進行排序,sort() 方法可以通過參數指定排序的字段,并使用 1 和 -1 來指定排序的方式,其中 1 為升序排列,而 -1 是用于降序排列。
語法:
sort()方法基本語法如下所示:
db.COLLECTION_NAME.find().sort({KEY:1})示例:
在Contacts集合中讓name按照降序來排列:
db.Contacts.find().sort({"name":-1})
7. MongoDB索引
(1) 說明
- 索引通常能夠極大的提高查詢的效率,如果沒有索引,MongoDB在讀取數據時必須掃描集合中的每個文件并選取那些符合查詢條件的記錄。
- 這種掃描全集合的查詢效率是非常低的,特別在處理大量的數據時,查詢可以要花費幾十秒甚至幾分鐘,這對網站的性能是非常致命的。
- 索引是特殊的數據結構,索引存儲在一個易于遍歷讀取的數據集合中,索引是對數據庫表中一列或多列的值進行排序的一種結構。
(2) 語法
createIndex()方法基本語法格式如下所示:
注意:語法中 Key 值為你要創建的索引字段,1 為指定按升序創建索引,如果你想按降序來創建索引指定為 -1 即可。
db.collection.createIndex(keys, options)(3) createIndex() 接收可選參數,可選參數列表如下:

① 為Contacts集合中的name字段按降序設置索引:
db.Contacts.createIndex({"name":-1})
② 為Contacts集合中的name字段和phone字段同時按降序設置索引(關系型數據庫中稱作復合索引):
db.Contacts.createIndex({"name":-1,"phone":-1})
③ 以后臺方式給Contacts集合中的phone字段按降序設置索引:
db.Contacts.createIndex({"phone": 1}, {background: true})8. MongoDB聚合
MongoDB 中聚合(aggregate)主要用于處理數據(諸如統計平均值,求和等),并返回計算后的數據結果。
類似SQL語句中的 count(*)。
(1) 語法
aggregate() 方法的基本語法格式如下所示:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)(2) 首先創建一個BlogCollection集合,并批量插入多個文檔數據:
#創建集合
use BolgCollection
#批量插入集合文檔數據
db.BlogCollection.insert([{
title: '學習MongoDB',
description: 'MongoDB is no sql database',
by_user: '時光者',
likes: 100
},
{
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: '時光者',
likes: 10
},
{
title: 'Docker入門學習',
description: 'Docker入門學習教程',
by_user: '時光者',
likes: 100
},
{
title: '.Net Core入門學習',
description: '.Net Core入門學習',
by_user: '大姚',
likes: 750
},
{
title: 'Golang入門學習',
description: 'Golang入門學習',
by_user: '小藝',
likes: 750
}])
#查詢集合所有文檔數據
db.BlogCollection.find()(3) $sum分組統計以上BlogCollection集合每個作者所寫的文章數:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
(3) 類似于SQL語句:
select by_user, count(*) from BlogCollection group by by_user(4) $sum 計算likes的總和:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
(5) $avg 計算Likes的平均值:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
(6) $min 獲取集合中所有文檔對應值得最小值:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
$max 獲取集合中所有文檔對應值得最大值:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])