億級核心表如何優雅擴展字段?中臺團隊實戰經驗揭秘
1.導語
億級數據的核心表新增一個字段,遠不止一句簡單的“ALTER TABLE”,鎖表風險、頁分裂、索引性能衰減……每一個問題都可能引發線上事故。如何在不影響業務的前提下,只需簡單的配置,即可實現字段的動態擴展?本文將帶你揭秘中臺團隊的實戰解決方案。
2.背景
軟件行業中,唯一不變的因素就是“變化”。一個新項目上線后,業務需要對現有功能做一些改動或升級,而實現這個功能必須要新增字段。新增字段乍一看無所謂,但如果加上一些前提條件,這張表是一張百億級數據的表,而且是公司的核心熱點表,你還能隨心所欲地加么。拋開加字段過程中的鎖表問題不說,后續隨著字段和數據的不斷增多,還會引發MySQL的頁分裂、碎片化、索引性能衰減等一系列問題。
如何處理這個問題呢?我們最直接能想到的就是兩種方式,擴展字段和擴展表。當然也有人可能會想到用非關系型數據庫解決。而數據庫選型往往是在項目初期時考慮,如果是老項目,實現起來就有不小的難度和風險,并且非關系型數據庫也有自己無能為力的方面。所以其他方式我們暫且先按下不表,下面我們主要討論怎么基于現有條件更優雅地解決這個問題。
3.擴展字段
擴展字段是最容易想到的解決方案,在表中增加一個擴展字段,以JSON格式存儲數據。這也是我們之前一直采用的方式,我們的使用方式是這樣的:
表結構:
order_id | extend |
111 | {"uid":1,"name":"張三"} |
222 | {"uid":2,"name":"李四"} |
... | ... |
偽代碼:
public class Order {
private Long orderId;
private String extend;
/**
* 為擴展字段extend建一個內部類
*/
@Data
public static class ExtendObj implements Serializable {
private Long uId;
private String name;
...
}
/**
* 擴展字段的get、set方法
*/
public void setExtendObj(ExtendObj extendObj) {
// 為展示方便,省略判空等邏輯
this.extend = JSON.toJSONString(extendObj);
}
public ExtendObj getExtendObj() {
// 為展示方便,省略判空等邏輯
return JSON.parseObject(extend, ExtendObj.class);
}
}如代碼所示,為了便于管理字段,我們為擴展字段創建了內部類,并實現get、set方法,以便于使用。如果你是獨立部門,你的數據存儲只服務于自己的系統,在表設計之初可以根據經驗預留一些備用字段,再配合擴展字段,基本上可以做到很少添加字段了。但這個方案也存在一些問題:
- 不可索引。extend里的字段無法建立索引進行檢索。這里有經驗的讀者可能會提出,MySQL 5.7.8版本支持JSON數據類型,可以為擴展字段中的某一個或一部分字段建立索引。是的沒錯,但如果你之前用的是更老的版本,就需要升級,MySQL版本升級也不是說升就能升的,懂的都懂,這里就不展開說了。
- 并發覆蓋。當對extend并發更新的時候,會出現覆蓋問題。這里我們采用了CAS更新的方式去避免,但是隨著extend中的字段不斷增多,沖突問題越來越頻繁,CAS策略就影響到了接口成功率。
- 重復工作。每次新增字段都需要為內部類增加屬性,拉分支,重新打包上線。
如果你是中臺部門,除了上面的硬傷,還有一些更傷腦筋的問題在等著你:
- 數據膨脹。你不可能基于當前的擴展字段,來者不拒地存,字段總有一天會超長,就像一柄達摩克利斯之劍。當然,你擁有的劍還不止一柄,你同樣需要擔心字段不斷膨脹之后的數據庫性能。然而你也不能來者皆拒,業務部門因為你的拒絕,需要為一兩個字段去自己新建一張表存儲維護,成也很高,于是你陷入了兩難。
- 維護黑洞。隨著業務迭代,你的維護成本會越來越高,面對幾百個擴展字段,你無法快速知道這些字段具體是哪個業務、什么場景在用,當前還有沒有在使用、可不可以被下掉。
4.擴展表
另一種方案是擴展表。擴展表將擴展字段中的每個字段轉成一行,存儲到另外一張表中:
order_id | key | value |
111 | uId | 1 |
111 | name | 張三 |
222 | uId | 2 |
222 | name | 李四 |
如果后續新增了age屬性,數據就變為:
order_id | key | value |
111 | uId | 1 |
111 | name | 張三 |
222 | uId | 2 |
222 | name | 李四 |
111 | age | 26 |
222 | age | 38 |
擴展表解決了擴展字段無法索引的問題,由于把字段拆開了存,也很大程度上緩解了并發問題。同時,由于擴展數據不在主表存儲了,也釋放了主表的壓力,讓加字段更從容一些。但也引進來一個新問題:本來一條記錄的許多屬性,變成了多條記錄,行數成倍增加了。為解決這個問題,我們基于主表現有的分庫分表邏輯,對擴展表也進行了分庫和分表。
擴展表方案貌似解決了擴展字段方案的大部分問題,可索引、沒有并發覆蓋問題、不影響主表性能。但還是沒有解決字段維護問題,你還是不知道哪些字段場景在用什么字段,哪些字段可以下線。并且在實踐中,我們還歸納出其他一些使用場景:
場景1:有些業務期望將數據存儲在訂單中臺后,在訂單的后續某個節點傳遞給下游服務。
場景2:有些業務期望擴展字段中的某些字段與主表上的某些字段一起進行檢索。
這兩個場景實現起來比較機械,我們也不希望每次都去開發。
5.現在的方案
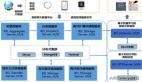
為了滿足上面兩種使用場景,并且實現只需簡單的配置,即可實現字段的動態擴展的愿景,最終,我們將整個系統拆分為三部分:數據管理、數據存儲、數據檢索。數據管理部分用于管理動態字段準入、接口透傳信息、檢索要求、歸屬以及其他基本信息,數據存儲部分核心還是采用擴展表的方案,數據檢索采用ES集群及自研ES管理系統ECP。
 descript
descript
現在,我們來看看當前的系統能做什么:
- 首先,有了管理系統之后,字段的歸屬、作用域、場景都很清晰,不再是一個黑盒,生效狀態也可以進行標記,被標記失效的字段后續就可以逐步下線。
- 對于場景1,業務可以將數據通過下單接口(或其他節點接口)傳入訂單系統,并保存到數據庫。當訂單流轉到對應節點,需要調用相關接口時,會檢查參數透傳信息,搜集需要透傳到當前接口的所有參數數據,然后根據參數路徑,將之前保存的值設置到對應請求參數中透傳下去。
- 對于場景2,為了規避連表查詢,我們還是借助了ES,通過ES合并主表和擴展表數據進行檢索。
至此,業務方再提出新增字段訴求,只需要在數據管理后臺進行配置上線,使用者即可通過指定接口,或接口的指定參數將數據傳入,實現數據的存儲、傳遞、檢索能力,全程無需開發介入。
6.結語
在大數據量表上的動態擴展字段,本質上是靈活性與穩定性的博弈,既要支撐業務快速迭代,又要規避“野蠻生長”的技術風險。基于分治思想,我們將核心數據與擴展數據分離;在系統設計上,對數據管理、數據存儲、數據檢索三部分進行解耦,把問題拆解,降低每一部分的設計難度;而在具體實踐上,我們也將整個系統功能進行了封裝,以便其他有同樣困境的系統能夠快速擴展該項能力。
關于作者王帥 轉轉交易中臺研發工程師