一文揭秘專為 RAG 打造的高性能開(kāi)源圖向量數(shù)據(jù)庫(kù):HelixDB
在人工智能技術(shù)尤其是大語(yǔ)言模型(LLM)蓬勃發(fā)展的浪潮中,檢索增強(qiáng)生成(Retrieval-Augmented Generation,簡(jiǎn)稱 RAG)正迅速成為提升生成式 AI 系統(tǒng)內(nèi)容準(zhǔn)確性、實(shí)時(shí)性與上下文相關(guān)性的核心手段。RAG 通過(guò)將外部知識(shí)檢索與語(yǔ)言模型推理相結(jié)合,顯著緩解了模型“幻覺(jué)”問(wèn)題,使其在問(wèn)答系統(tǒng)、智能助手、企業(yè)知識(shí)中臺(tái)等應(yīng)用中展現(xiàn)出廣闊前景。

然而,隨著業(yè)務(wù)需求的不斷升級(jí),傳統(tǒng) RAG 系統(tǒng)所依賴的扁平向量表示與單一類型數(shù)據(jù)庫(kù)架構(gòu),已難以滿足對(duì)復(fù)雜語(yǔ)義結(jié)構(gòu)建模與海量非結(jié)構(gòu)化數(shù)據(jù)高效檢索的雙重需求。在面對(duì)多跳推理、實(shí)體關(guān)系鏈構(gòu)建、跨領(lǐng)域知識(shí)聯(lián)想等場(chǎng)景時(shí),現(xiàn)有方案普遍存在語(yǔ)義理解淺層、數(shù)據(jù)組織松散、查詢性能瓶頸等問(wèn)題,嚴(yán)重制約了 RAG 技術(shù)的進(jìn)一步演進(jìn)。
HelixDB 的誕生正是為破解這一瓶頸而來(lái)。作為一款以 Rust 語(yǔ)言打造的高性能開(kāi)源圖向量數(shù)據(jù)庫(kù),HelixDB 以其原生支持圖結(jié)構(gòu)與向量語(yǔ)義的深度融合、面向 AI 應(yīng)用場(chǎng)景的架構(gòu)設(shè)計(jì)、以及卓越的并發(fā)查詢性能,為下一代 RAG 系統(tǒng)提供了堅(jiān)實(shí)的底座。它不僅能夠精確建模實(shí)體之間的復(fù)雜語(yǔ)義關(guān)系,還能在保留圖拓?fù)湫畔⒌幕A(chǔ)上,實(shí)現(xiàn)高維向量相似度檢索,真正實(shí)現(xiàn)“語(yǔ)義+結(jié)構(gòu)”雙驅(qū)動(dòng)的智能檢索能力。
1. 什么是 HelixDB ?以及如何破局傳統(tǒng) RAG 的痛點(diǎn) ?
眾所周知,傳統(tǒng) RAG(Retrieval Augmented Generation)方法主要依賴于向量相似性搜索來(lái)從知識(shí)庫(kù)中檢索信息。雖然這種方法對(duì)于找到與查詢語(yǔ)義相似的內(nèi)容塊非常有效,但在處理更復(fù)雜、更具結(jié)構(gòu)化的數(shù)據(jù)時(shí)存在一些固有的痛點(diǎn):
(1) 難以利用數(shù)據(jù)之間的結(jié)構(gòu)化關(guān)系
純粹的向量搜索將知識(shí)庫(kù)中的所有文本塊視為孤立的點(diǎn),無(wú)法 natively 理解或利用數(shù)據(jù)片段、實(shí)體、概念或文檔之間存在的顯式關(guān)系(如引用、包含、屬于、依賴、上下位關(guān)系、調(diào)用關(guān)系等)。
(2) 檢索到的上下文缺乏深度和關(guān)聯(lián)性
傳統(tǒng)的僅僅返回與查詢最相似的 Top-K 個(gè)文本塊,這些塊可能是碎片化的,缺乏必要的上下文來(lái)讓 LLM 準(zhǔn)確理解或生成全面答案。
(3) 難以處理需要關(guān)系推理的復(fù)雜查詢
通常而言,回答那些需要跨越多個(gè)數(shù)據(jù)點(diǎn)、沿著關(guān)系鏈進(jìn)行推理的復(fù)雜問(wèn)題,是純向量搜索無(wú)法做到的。
(4) 難以表示和利用知識(shí)圖譜等結(jié)構(gòu)化知識(shí)
知識(shí)圖譜包含了大量結(jié)構(gòu)化的實(shí)體和關(guān)系信息,這對(duì) LLM 理解世界至關(guān)重要。但在純向量 RAG 中,通常只能將知識(shí)圖譜的文本描述或子圖信息向量化,丟失了其固有的結(jié)構(gòu)。

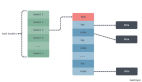
作為一款高性能的圖向量數(shù)據(jù)庫(kù),HelixDB 專為下一代人工智能與向量驅(qū)動(dòng)的應(yīng)用場(chǎng)景打造,兼顧卓越的開(kāi)發(fā)者體驗(yàn)與極致的運(yùn)行效率。基于 Rust 語(yǔ)言開(kāi)發(fā),HelixDB 以其高效、安全與內(nèi)存優(yōu)化的特性,結(jié)合成熟的 LMDB 存儲(chǔ)引擎,完美融合了穩(wěn)定可靠的存儲(chǔ)能力與前沿的圖向量混合查詢功能,為復(fù)雜語(yǔ)義關(guān)系的檢索與處理提供了強(qiáng)大支持。

特別值得一提的是,HelixDB 通過(guò) Heed3(由 Meilisearch 團(tuán)隊(duì)精心打造的 Rust 封裝庫(kù))與 LMDB 無(wú)縫集成,進(jìn)一步提升了開(kāi)發(fā)效率與系統(tǒng)性能。這種獨(dú)特的設(shè)計(jì)不僅加速了數(shù)據(jù)處理流程,還為開(kāi)發(fā)者提供了靈活、可擴(kuò)展的工具,助力構(gòu)建更智能、更高效的 RAG(檢索增強(qiáng)生成)及其他 AI 應(yīng)用。HelixDB 的出現(xiàn),正重新定義圖向量數(shù)據(jù)庫(kù)的行業(yè)標(biāo)桿,為開(kāi)發(fā)者開(kāi)啟了無(wú)限可能。
以下為一個(gè)構(gòu)建藍(lán)圖 - 在 schema.hx 文件中定義數(shù)據(jù)庫(kù)模式 (Schema)的參考示例,具體:
N::User {
name: String,
age: U32,
email: String,
created_at: I32,
updated_at: I32,
}
N::Post {
content: String,
created_at: I32,
updated_at: I32,
}
E::Follows {
From: User,
To: User,
Properties: {
since: I32,
}
}
E::Created {
From: User,
To: Post,
Properties: {
created_at: I32,
}
}上述代碼段用于創(chuàng)建或更新 HelixDB 數(shù)據(jù)庫(kù)模式的腳本片段(例如保存在 schema.hx 文件中)。它使用了 HelixDB 特定的一種模式定義語(yǔ)言,通過(guò)清晰的語(yǔ)法來(lái)聲明不同類型的節(jié)點(diǎn)(Nodes)和關(guān)系(Edges)。
2. HelixDB 具備哪些核心特性 ?
HelixDB 憑借其獨(dú)特的設(shè)計(jì)理念和用 Rust 語(yǔ)言構(gòu)建的強(qiáng)大底層架構(gòu),為解決現(xiàn)代 AI 和 RAG 應(yīng)用中的數(shù)據(jù)存儲(chǔ)挑戰(zhàn)提供了革命性的能力,已成為下一代 RAG 的理想選擇。基于其如下核心特性,以使得它能在眾多數(shù)據(jù)庫(kù)中脫穎而出:
(1) 極致性能與高效率
HelixDB 天生為卓越性能而設(shè)計(jì)。得益于其底層高效實(shí)現(xiàn)和 Rust 語(yǔ)言帶來(lái)的內(nèi)存安全與并發(fā)優(yōu)勢(shì),在處理圖數(shù)據(jù)操作時(shí)展現(xiàn)出驚人的速度。
根據(jù)當(dāng)前測(cè)試結(jié)果,其在某些圖查詢場(chǎng)景下的性能可比傳統(tǒng)圖數(shù)據(jù)庫(kù) Neo4j 快 1000 倍,比 TigerGraph 快 100 倍。同時(shí),作為一款圖向量數(shù)據(jù)庫(kù),HelixDB 在向量相似性搜索方面的表現(xiàn)也毫不遜色,性能可與業(yè)界領(lǐng)先的純向量數(shù)據(jù)庫(kù) Qdrant 相媲美。這種在圖和向量?jī)煞矫娴碾p重高性能,確保我們所構(gòu)建的 AI 和 RAG 應(yīng)用能夠以最低的延遲進(jìn)行高吞吐量的數(shù)據(jù)檢索和處理。
(2) RAG 應(yīng)用原生優(yōu)化
HelixDB 并非在現(xiàn)有數(shù)據(jù)庫(kù)基礎(chǔ)上簡(jiǎn)單疊加向量功能,而是從設(shè)計(jì)之初就將 RAG (Retrieval Augmented Generation) 和各類 AI 應(yīng)用的需求放在首位。它原生支持圖數(shù)據(jù)類型和向量數(shù)據(jù)類型,這消除了在不同數(shù)據(jù)庫(kù)之間同步數(shù)據(jù)或進(jìn)行復(fù)雜橋接的需要。
這種緊密的原生集成,使其成為構(gòu)建能夠理解數(shù)據(jù)間復(fù)雜關(guān)系和內(nèi)容內(nèi)容相似性的下一代 RAG 應(yīng)用的最理想、最直接且最高效的數(shù)據(jù)存儲(chǔ)基礎(chǔ)設(shè)施。
(3) 強(qiáng)大的圖向量一體能力
HelixDB 最具創(chuàng)新性和競(jìng)爭(zhēng)力的優(yōu)勢(shì)在于其無(wú)縫融合圖結(jié)構(gòu)和向量數(shù)據(jù)的能力。它在一個(gè)統(tǒng)一的數(shù)據(jù)庫(kù)中,提供了一種前所未有、最便捷直觀的方式來(lái)存儲(chǔ)和管理數(shù)據(jù)——不僅可以輕松存儲(chǔ)和查詢節(jié)點(diǎn)之間的復(fù)雜關(guān)系(傳統(tǒng)圖數(shù)據(jù)庫(kù)的核心),也能存儲(chǔ)和查詢向量之間的相似性關(guān)系(傳統(tǒng)向量數(shù)據(jù)庫(kù)的核心)。
此外,更能在一個(gè)統(tǒng)一模型中存儲(chǔ)和查詢節(jié)點(diǎn)與向量之間的復(fù)雜關(guān)聯(lián),從而極大地簡(jiǎn)化了需要結(jié)合結(jié)構(gòu)化關(guān)系(如知識(shí)圖譜中的實(shí)體連接、文檔分塊之間的引用)和內(nèi)容相似性(如段落的向量表示、圖片特征向量)的應(yīng)用開(kāi)發(fā),完美契合了下一代 RAG 對(duì)多模態(tài)、多關(guān)系復(fù)雜數(shù)據(jù)的高級(jí)檢索需求。
(4) 堅(jiān)固可靠的數(shù)據(jù)存儲(chǔ)層
HelixDB 的底層存儲(chǔ)引擎由廣受好評(píng)的 LMDB (Lightning Memory-Mapped Database) 提供支持。LMDB 是一個(gè)以其零管理、高性能、極高可靠性著稱的鍵值存儲(chǔ)庫(kù),直接通過(guò)內(nèi)存映射文件工作,最大限度地減少了系統(tǒng)調(diào)用和數(shù)據(jù)拷貝,非常高效。LMDB 為 HelixDB 提供了穩(wěn)定、持久、不易損壞的數(shù)據(jù)存儲(chǔ)基礎(chǔ),即使在意外斷電或系統(tǒng)崩潰的情況下,也能確保您的寶貴數(shù)據(jù)安全可靠。
(5) 嚴(yán)格遵循 ACID 特性
作為一款為關(guān)鍵 AI 應(yīng)用設(shè)計(jì)的基礎(chǔ)設(shè)施,數(shù)據(jù)完整性至關(guān)重要。HelixDB 完全兼容并嚴(yán)格遵循 ACID(原子性 Atomicity,一致性 Consistency,隔離性 Consistency,持久性 Durability)事務(wù)原則,從而確保了所有數(shù)據(jù)操作(讀、寫、更新)都具備高度的完整性和一致性。
因此,無(wú)論系統(tǒng)面臨高并發(fā)寫入還是突發(fā)故障,HelixDB 都能保證數(shù)據(jù)的準(zhǔn)確無(wú)誤和狀態(tài)的可靠轉(zhuǎn)換,為構(gòu)建在之上的企業(yè)級(jí) AI/RAG 應(yīng)用提供了堅(jiān)實(shí)的數(shù)據(jù)可靠性保障。
3. HelixDB 經(jīng)典應(yīng)用場(chǎng)景解析
作為一款專為人工智能與檢索增強(qiáng)生成(RAG)優(yōu)化的圖向量數(shù)據(jù)庫(kù),Helix 以其靈活性和高效性,為多種復(fù)雜應(yīng)用場(chǎng)景提供了強(qiáng)有力的支持。具體可參考如下:
(1) 代碼文檔智能化檢索
不僅僅是簡(jiǎn)單的文本搜索, HelixDB 能夠深度理解您的代碼庫(kù)和文檔。利用其圖能力存儲(chǔ)代碼文件、函數(shù)、類、變量之間的引用、繼承、調(diào)用等結(jié)構(gòu)關(guān)系,結(jié)合向量能力存儲(chǔ)代碼注釋、文檔描述、甚至代碼片段的語(yǔ)義向量。
我們可以基于自然語(yǔ)言進(jìn)行查詢,AI Agent 可以通過(guò) HelixDB 同時(shí)利用語(yǔ)義相似性(向量搜索)和代碼結(jié)構(gòu)關(guān)系(圖遍歷)來(lái)查找最相關(guān)的文檔片段、代碼示例或解釋。這極大地提升了 AI Agent 理解和輔助編寫復(fù)雜代碼的效率和準(zhǔn)確性,超越了傳統(tǒng)的關(guān)鍵詞或純向量搜索工具。
(2) 增強(qiáng)型語(yǔ)義搜索
將自然語(yǔ)言搜索帶入新的維度。 在海量非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)(如企業(yè)內(nèi)部文檔、客戶反饋、研究報(bào)告、電子郵件)中實(shí)現(xiàn)基于自然語(yǔ)言的深度語(yǔ)義搜索。HelixDB 不僅能高效存儲(chǔ)并索引數(shù)據(jù)的語(yǔ)義向量,還能捕捉數(shù)據(jù)實(shí)體之間、文檔片段之間或概念之間的隱藏關(guān)聯(lián)關(guān)系。
通過(guò)結(jié)合向量搜索和圖遍歷,搜索結(jié)果不再僅僅是與查詢語(yǔ)義相似的孤立文檔,而是能夠結(jié)合這些結(jié)構(gòu)關(guān)系,找到與查詢概念緊密關(guān)聯(lián)的、上下文更豐富、洞察更深入的信息集合,提供更智能、更符合人類思維方式的搜索體驗(yàn)。
(3) 結(jié)構(gòu)化與語(yǔ)義化代碼庫(kù)索引
為代碼庫(kù)構(gòu)建一個(gè)既理解結(jié)構(gòu)又理解語(yǔ)義的智能索引。 傳統(tǒng)代碼索引側(cè)重于關(guān)鍵詞匹配或簡(jiǎn)單的文件層級(jí)結(jié)構(gòu)。HelixDB 允許您將代碼庫(kù)的每一個(gè)重要組成部分(文件、函數(shù)、類、變量、注釋等)及其對(duì)應(yīng)的語(yǔ)義向量存儲(chǔ)為圖中的節(jié)點(diǎn),同時(shí)將它們之間的真實(shí)結(jié)構(gòu)關(guān)系(如文件包含、函數(shù)調(diào)用、類繼承、模塊依賴等)存儲(chǔ)為圖中的邊。
基于所構(gòu)建的一個(gè)豐富且可查詢的圖結(jié)構(gòu)代碼知識(shí)庫(kù),結(jié)合向量能力,可以支持基于語(yǔ)義和結(jié)構(gòu)的復(fù)雜代碼搜索、依賴分析、影響范圍快速評(píng)估、潛在代碼問(wèn)題檢測(cè)等高級(jí)功能,是構(gòu)建智能化代碼理解和自動(dòng)化工具的堅(jiān)實(shí)基礎(chǔ)。
(4) 智能知識(shí)庫(kù)構(gòu)建與檢索
打造一個(gè)易于維護(hù)、檢索精準(zhǔn)且能呈現(xiàn)知識(shí)關(guān)聯(lián)的智能知識(shí)庫(kù)。 利用 HelixDB,您可以輕松地將企業(yè)的技術(shù)文檔、FAQ、手冊(cè)、研究資料等知識(shí)資產(chǎn)進(jìn)行切塊、向量化并存儲(chǔ)為帶有語(yǔ)義向量的節(jié)點(diǎn)。更重要的是,您可以存儲(chǔ)這些知識(shí)塊之間的引用關(guān)系、上下位概念、相關(guān)主題關(guān)聯(lián)等圖結(jié)構(gòu)信息。
用戶進(jìn)行自然語(yǔ)言查詢時(shí),系統(tǒng)可以先進(jìn)行向量搜索找到語(yǔ)義相關(guān)的知識(shí)塊,然后沿著圖關(guān)系進(jìn)行擴(kuò)展和遍歷,智能地找到與原始知識(shí)塊高度相關(guān)聯(lián)、提供補(bǔ)充上下文或更深層解釋的信息。這使得知識(shí)庫(kù)檢索更加全面、精準(zhǔn),并能以結(jié)構(gòu)化的方式呈現(xiàn)知識(shí)之間的關(guān)聯(lián),極大地提升了知識(shí)發(fā)現(xiàn)和利用的效率。
(5) 靈活支持傳統(tǒng) RAG 模式
無(wú)論是純向量還是純圖 RAG,HelixDB 都能輕松應(yīng)對(duì)。 HelixDB 的原生設(shè)計(jì)同時(shí)支持高性能的向量存儲(chǔ)與查詢以及靈活高效的圖結(jié)構(gòu)存儲(chǔ)與遍歷。這意味著我們可以根據(jù)具體需求,選擇獨(dú)立地使用 HelixDB 作為高性能的純向量數(shù)據(jù)庫(kù)來(lái)構(gòu)建傳統(tǒng)的向量相似性 RAG,或者獨(dú)立地使用它作為強(qiáng)大的圖數(shù)據(jù)庫(kù)來(lái)構(gòu)建基于結(jié)構(gòu)化關(guān)系的 RAG。這種靈活性使得在技術(shù)選型和架構(gòu)設(shè)計(jì)上擁有更多選擇,并可以根據(jù)項(xiàng)目演進(jìn)平滑過(guò)渡。
(6) 構(gòu)建更強(qiáng)大、更準(zhǔn)確的混合 RAG (Hybrid RAG)
作為 HelixDB 的核心優(yōu)勢(shì)所在,開(kāi)啟下一代 RAG 的大門。 HelixDB 最強(qiáng)大的能力在于其能夠在一個(gè)統(tǒng)一的數(shù)據(jù)庫(kù)和一次查詢中無(wú)縫融合和同時(shí)利用向量相似性搜索結(jié)果與基于圖結(jié)構(gòu)的關(guān)聯(lián)信息。我們可以先通過(guò)向量搜索找到語(yǔ)義相關(guān)的初始知識(shí)點(diǎn),然后智能地沿著圖關(guān)系進(jìn)行遍歷和擴(kuò)展,獲取到與初始知識(shí)點(diǎn)在結(jié)構(gòu)上緊密關(guān)聯(lián)、上下文更豐富、信息更全面的知識(shí)集合。
這種向量與圖的深度協(xié)同檢索,能夠顯著提升 RAG 系統(tǒng)獲取知識(shí)的準(zhǔn)確性、相關(guān)性和豐富度,從而使 LLM 生成的回復(fù)更加精準(zhǔn)、可靠且具有深度,真正實(shí)現(xiàn)下一代 RAG 的強(qiáng)大能力。
(7) 智能查找與兼容性分析
高效管理復(fù)雜產(chǎn)品數(shù)據(jù),智能查找部件并進(jìn)行兼容性分析。 在管理復(fù)雜產(chǎn)品(如電子設(shè)備、機(jī)械裝配、軟件組件)的部件庫(kù)時(shí),查找特定部件、了解其組成結(jié)構(gòu)或找到與之兼容的部件是一項(xiàng)挑戰(zhàn)。
利用 HelixDB,我們可以將產(chǎn)品部件及其屬性(包括文本描述或規(guī)格的向量)存儲(chǔ)為節(jié)點(diǎn),同時(shí)將部件之間的組成關(guān)系(例如“包含于”)、兼容關(guān)系、替代關(guān)系、供應(yīng)商關(guān)系等存儲(chǔ)為圖中的邊。用戶可以基于自然語(yǔ)言或部件 ID 進(jìn)行查詢,HelixDB 能夠結(jié)合部件的語(yǔ)義屬性(向量搜索)和部件之間的結(jié)構(gòu)關(guān)系(圖遍歷),快速、準(zhǔn)確地查找最相關(guān)的部件、其所屬的父組件、依賴的子組件,以及所有兼容或可替代的部件。這極大地提高了復(fù)雜產(chǎn)品數(shù)據(jù)管理的效率和智能化水平,廣泛應(yīng)用于制造業(yè)、供應(yīng)鏈管理、IT 資產(chǎn)管理等領(lǐng)域。
(8) 賦能高級(jí) AI 編程代理
為下一代 AI 編程代理提供強(qiáng)大的“大腦”與“記憶”。 高級(jí)的 AI 編程代理(如輔助編寫、調(diào)試、重構(gòu)、代碼審查的 Agent)需要對(duì)整個(gè)代碼庫(kù)有深刻且細(xì)致的理解。HelixDB 可以作為 AI 編程代理的外部、可交互的知識(shí)源。
代理可以通過(guò)自然語(yǔ)言或代碼上下文向 HelixDB 發(fā)送查詢,數(shù)據(jù)庫(kù)利用其圖向量一體能力,不僅能快速找到與查詢代碼片段語(yǔ)義最相似的代碼(向量搜索),還能立即獲取與該代碼片段相關(guān)聯(lián)的函數(shù)定義、調(diào)用方、被調(diào)用方、所屬的類、使用的庫(kù)等結(jié)構(gòu)化上下文(圖遍歷)。這種結(jié)合了語(yǔ)義和結(jié)構(gòu)的高級(jí)代碼檢索能力,能為 AI 代理提供比傳統(tǒng)方法更全面、更精準(zhǔn)、更具操作性的代碼上下文,顯著提升其編程輔助、問(wèn)題診斷和代碼生成能力。
Reference :https://www.helix-db.com