英偉達再破世界紀錄,每秒1000 token!剛剛,全球最快Llama 4誕生
你以為,AI推理的速度已經夠快了?
不,英偉達還能再次顛覆你的想象——就在剛剛,他們用Blackwell創下了AI推理的新紀錄。

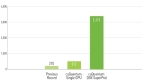
僅僅采用單節點(8顆Blackwell GPU)的DGX B200服務器,英偉達就實現了Llama 4 Maverick模型每秒單用戶生成1000個token(TPS/user)的驚人成績!

單節點使用8塊B200 GPU
這項速度記錄,由AI基準測試服務Artificial Analysis獨立測量。

而且,更令人咋舌的是,單臺服務器(GB200 NVL72,配備72顆Blackwell GPU)的整體吞吐量,已經達到了72,000 TPS!

GB200 NVL72液冷機架原型機
這場速度革命的幕后,是一整套精心布局的技術組合拳——
- 使用TensorRT-LLM優化框架和EAGLE-3架構訓練推測解碼草稿模型;
- 在GEMM、MoE及Attention計算中全面應用FP8數據格式,有效縮小模型體積并提高計算效率;
- 應用CUDA內核優化技術(如空間分區、GEMM權重重排、Attention內核并行優化、程序化依賴啟動(PDL)等);
- 運算融合(如FC13+SwiGLU、FC_QKV+attn_scaling、AllReduce+RMSnorm融合)。
由此,Blackwell的性能潛力徹底被點燃,一舉實現了4倍加速,直接把之前的最強Blackwell基線甩在身后!
迄今測試過最快Maverick實現
這次優化措施在保持響應準確度的同時,顯著提升了模型性能。
英偉達針對GEMM(通用矩陣乘法)、MoE(混合專家模型)及Attention(注意力)運算運用了FP8數據類型,旨在減小模型體積,并充分利用Blackwell Tensor Core技術所帶來的高FP8吞吐量優勢。
如下表所示,采用FP8數據格式后,模型在多項評估指標上的準確度可與Artificial Analysis采用BF16數據格式(進行測試)所達到的準確度相媲美:

為何減少延遲至關重要?
大部分用生成式AI的場景,都要在吞吐量(throughput)和延遲(latency)之間找一個平衡點,好讓很多用戶同時使用時,都能有個「還不錯」的體驗。
但是,有些關鍵場景,比如要迅速做出重要決策的時候,「響應速度」就變得特別重要,哪怕一點延遲都可能帶來嚴重后果。
無論你想要的是同時處理盡可能多的請求,還是希望既能處理很多請求、響應又比較快,還是只想最快地服務單個用戶(即最小化單個用戶的延遲),Blackwell的硬件都是最佳選擇。
下圖概述了英偉達在推理過程中應用的內核優化和融合(以紅色虛線框標示)。

英偉達實現了若干低延遲GEMM內核,并應用了各種內核融合(如FC13+SwiGLU、FC_QKV+attn_scaling以及AllReduce+RMSnorm),從而使Blackwell GPU在最小延遲場景下表現出色。
CUDA內核優化與融合
在內核優化與融合方面,英偉達采用了以下幾項關鍵技術:
- 空間分區與高效內存加載
利用空間劃分(也稱為warp專業化)并設計GEMM內核,可以高效的方式從內存中加載數據,從而最大限度地利用NVIDIA DGX所提供的巨大內存帶寬——總計64TB/s。
- GEMM權重重排
將GEMM權重以一種優化的swizzled格式進行重排。
由此可以確保在使用Blackwell第五代Tensor Core完成矩陣乘法計算后,從Tensor內存加載計算結果時能夠獲得更理想的數據布局。
- Attention內核并行優化
通過沿K和V張量的序列長度維度對計算進行劃分,優化了Attention內核的性能,使得計算任務能夠在多個CUDA線程塊上并行執行。
此外,還利用分布式共享內存機制,在同一線程塊集群內的不同線程塊之間高效地進行結果規約,從而避免了訪問全局內存的需要。
- 運算融合
通過啟用不同運算之間的融合,來減少內核執行間的開銷以及內存加載/存儲的次數。
例如,將AllReduce運算與緊隨其后的RMSNorm運算及量化(Quantize)運算融合成單一的CUDA內核,以及將SwiGLU運算與其前置的GEMM運算進行融合。
程序化依賴啟動(PDL)
程序化依賴啟動(PDL)是一項CUDA功能,它能夠減少同一CUDA流上兩個連續CUDA內核執行之間的GPU空閑時間,甚至允許這兩個內核部分重疊執行。
默認情況下,當多個內核在同一個CUDA流上啟動時,第二個內核必須等待第一個內核執行完畢后才能開始。
這種機制會導致兩個主要的性能問題:
- 其一,兩個連續的內核執行之間會產生微小的間隙(如下圖所示),在此期間GPU處于閑置狀態。
- 其二,當第一個內核的執行接近尾聲時,它可能仍會占用一部分流式多處理器(SM)來完成剩余的CUDA塊計算,這使得GPU上的其他SM處于空閑,從而導致GPU整體計算能力的利用率不足。

通過在CUDA中運用程序化依賴啟動API,英偉達允許次級內核(secondary kernel)在主內核(primary kernel)仍在運行時就開始執行。
在初始準備階段(preamble period),次級內核可以執行那些不依賴于主內核執行的計算任務,并加載相應的數據。
這不僅消除了兩個連續內核之間的執行間隙,也顯著提升了GPU的利用率;因為當主內核僅占用GPU上的部分SM時,其余空閑的SM便可以開始運行次級內核。

推測解碼
推測解碼(Speculative Decoding)是一種廣受歡迎的技術,用于在不犧牲生成文本質量的前提下,加速LLM的推理速度。
該技術通過一個規模更小、速度更快的「草稿」模型來預測一個推測token序列,然后由規模更大(通常也更慢)的LLM并行驗證這些token。
其加速效果源于:在目標模型的一次迭代中,有機會生成多個token,代價則是草稿模型帶來的一些額外開銷。

端到端的工作流
首先,在目標模型完成上下文階段(此階段亦會生成token t1)之后,草稿模型會迅速生成一連串潛在的token(例如d2-d4)。
隨后,目標模型進入生成階段,在這一階段,它會針對整個草稿序列,一次性地并行驗證(或生成)每個位置的下一個token。
如圖所示,如果草稿token與目標模型自身將要生成的token相匹配,目標模型便可能「接受」其中的若干token(如d2、d3),同時「拒絕」其他的token(如d4)。
這個循環不斷重復:被接受的token得以保留;若發生拒絕(例如,在d4被拒絕后),目標模型會提供正確的下一個token(如t4);然后,草稿模型會生成一個新的推測序列(例如d5-d7)。
通過并行驗證多個token——而不是依賴(速度較慢的)目標模型逐個生成它們——并充分利用草稿模型的快速推測能力,系統能夠實現顯著的速度提升,尤其是當草稿模型的預測準確率較高時。
「接受長度(AL)」定義為在單次驗證步驟中,平均能夠成功生成的token數量。
AL值越高,加速效果越顯著。
對此,英偉達采用了一種基于EAGLE3的架構作為其推測解碼方法,主要通過調整推測層中前饋網絡(FFN)的大小來優化接受長度(AL)。
在推理過程中,需要在目標模型的前向傳播階段記錄低、中、高三個層級的特征(即初始、中間及末端解碼層輸出的隱藏狀態)。
之后,再將這些隱藏狀態與token嵌入相結合,并將結果輸入到推測層。該推測層隨后以自回歸方式生成一個草稿token序列,供目標模型進行并行驗證。
推測層的開銷雖然不大,但也不可忽視。因此,關鍵的挑戰在于如何在草稿長度與端到端加速效果之間取得理想的平衡。
草稿長度越長,AL通常也越高,但相應地,運行草稿模型所產生的額外成本也會增加。根據英偉達在下方實驗中展示的結果,當草稿長度設置為3時,可獲得最佳的加速效果。

通過CUDA Graph和重疊調度器減少主機端開銷
推測解碼的另一個挑戰在于減少主模型與草稿模型之間的通信和同步開銷。
如果英偉達將采樣/驗證邏輯置于主機端,便會在主機與設備之間引入額外的同步點,進而破壞CUDA Graph的完整性。
因此,英偉達選擇將驗證邏輯保留在設備端,從而能夠將目標模型的前向傳播、驗證邏輯以及草稿模型的前向傳播都整合到同一個CUDA Graph中。
此外,英偉達還啟用了TensorRT-LLM的重疊調度器,以進一步讓當前迭代的模型前向傳播與下一次迭代的輸入準備及CUDA Graph啟動過程實現重疊。
使用torch.compile()優化草稿模型層
由于驗證邏輯是采用Torch原生操作在設備端實現的,這導致英偉達最終生成了大量細小的Torch原生內核。
手動融合這些內核不僅復雜,且容易出錯。
為此,英偉達采用torch.compile(),借助OpenAI Triton的能力來自動完成這部分內核的融合,并生成最優化的版本。
這一舉措幫助英偉達將草稿模型的開銷從25%成功降低到了18%(當草稿長度為3時)。
總結
總的來說,這一創世界紀錄的速度,是強大Blackwell架構、自CUDA層面起直至上層應用的深度軟件優化,以及英偉達量身定制的推測解碼實現所帶來的顯著加速三者結合的成果,它直接響應了下一代AI交互應用對低延遲的迫切需求。
正如英偉達所展示的那樣,這些技術進步確保了即便是超大規模模型,也能夠提供足夠的處理速度和響應能力,以支持無縫的實時用戶體驗和復雜的AI智能體部署場景。
作者介紹
Yilin Fan

Yilin Fan是英偉達的高級深度學習工程師,專注于TensorRT/TensorRT-LLM的性能。
他擁有卡內基梅隆大學的軟件工程碩士學位和北京航空航天大學的學士學位。
在加入英偉達之前,他曾在小馬智行工作,負責優化與部署自動駕駛汽車上的深度學習模型。
Po-Han Huang

Po-Han Huang是英偉達的深度學習軟件工程師。
在過去六年多的時間里,他一直致力于通過TensorRT和CUDA優化來加速已訓練深度神經網絡模型的推理。
他擁有伊利諾伊大學厄巴納-香檳分校的電子與計算機工程碩士學位,專業知識涵蓋深度學習加速、計算機視覺和GPU架構。
Ben Hamm

Ben Hamm是英偉達的技術產品經理,專注于LLM推理性能與優化。
此前,他曾在亞馬遜擔任產品經理,負責Alexa的喚醒詞檢測機器學習棧。之后加入OctoAI并擔任LLM托管服務的產品經理。隨著公司被收購,他也跟著一起來到了英偉達。
有趣的是,作為一名計算機視覺的愛好者,他甚至還發明了一款AI驅動的貓門。