一文讀懂: AI 智能體的架構原則、三高架構、 存儲架構的核心方案
一、為啥 AI 架構設計這么關鍵?
如今,AI 應用那可是雨后春筍般地冒出來。‘
從 ChatGPT 、到AI智能體應用,到每天服務上千萬人的智能客服,再到處理億級數據的推薦系統,要想讓這些 AI 玩意兒在實際場景里落地生根,高可用、高性能、靈活擴展的系統架構是關鍵。
這就好比蓋房子,地基不牢,房子能穩嗎?
就好比一個購物網站,推薦系統要是沒有好架構支撐,可能給你推的商品亂七八糟,用戶體驗差得很。AI 應用想在網絡世界站穩腳跟,背后的架構設計就是它茁壯成長的根基。
接下來,咱們就來好好扒一扒 AI 智能體應用的系統架構設計的核心原則、關鍵能力和實際應用場景。
一塊一塊地拼湊,讓您明白一個能扛住業務壓力的 AI 智能體應用是怎么設計出來的,又該怎么優化和進化。
二、架構設計核心原則:為變化而生,為復雜而解
1.1 演進式法則
AI 系統的業務變化快得讓人眼花繚亂。
模型不斷迭代更新,算法日新月異,業務場景也說變就變。
一開始可能是文本問答系統,后來要擴展到語音識別,再后來又要搞圖像生成,甚至多模態融合。要是架構沒有良好可演進性,每次迭代都得大動干戈,技術債一發不可收拾,系統脆弱得很,稍有風吹草動可能就崩潰。
所以,AI 系統架構設計得考慮到各種機制。
版本控制就像給系統留了個 “后悔藥”,發現新版本有問題還能退回舊版本。模塊熱插拔就像搭積木,某個模塊出問題或者需要升級,直接換掉,不影響其他部分。
灰度發布就像拿一小部分用戶 “試水”,看看新功能靠不靠譜,沒啥問題再推廣給所有用戶。
模型注冊就像給模型辦 “身份證”,方便管理和調用。通過這些機制,每個 AI 能力就像 “插件”,能靈活組合。
比如有個做智能語音助手的公司,一開始只做簡單語音問答,后來想加入語音播報新聞功能。
架構設計得好,直接把新的語音播報模塊插進去,稍微調整,就能輕松實現新功能,不用把整個系統都折騰一遍。這就像是搭積木,想加個新造型,直接往上搭就行,不用把原來的積木全部拆掉。
1.2 先進性法則
在 AI 系統里,引入先進技術。
先進技術, 比如像容器化部署、微服務架構、服務網格、模型加速(如 TensorRT、ONNX)、低延遲通信協議(如 gRPC)等,不是為了顯擺技術厲害,而是為了應對未來可能出現的挑戰,比如高并發、高吞吐、多模型部署、多租戶這些問題。
比如要部署一個千億參數的大模型,這可是個大家伙。
得合理規劃 A100 GPU 資源池,就像給它安排個 “豪華套房”,讓它舒舒服服運行。
還得安排好 RPC 推理通道和異步隊列調度。
RPC 推理通道就像給它修專屬高速公路,讓數據飛快跑進去跑出來。異步隊列調度就像給數據安排 “排隊系統”,
讓它們一個一個來,別亂成一團。只有用這些前瞻性技術手段,系統才能像未雨綢繆的將軍,提前做好準備,應對未來各種挑戰。
比如,有個做圖像識別的公司,知道以后要處理的圖像數據會越來越多,場景可能復雜,像在不同光照條件下識別物體。
他們提前采用這些先進技術,這樣當數據量突然增加或者場景復雜時,系統能從容應對,不會手忙腳亂。
1.3 領域驅動原則
搞AI平臺最怕技術員自嗨。就跟開飯店似的,不能先買個豪華灶臺再想賣啥。得從業務出發,先想明白是要賣火鍋還是賣燒烤。
AI平臺的底層能力(如模型服務、數據標注、評估監控)都應圍繞具體業務構建。
就像蓋房子先確定用途,是為了住人、開商店還是建工廠,不同用途決定房子設計。構建 AI 平臺也不是從技術出發,把各種模塊堆上去,而是從業務出發,建立 “領域服務” 模型。
構建AI平臺并非從技術出發堆疊模塊,而是從業務出發建立“領域服務”模型:一個“客服意圖識別”領域服務,就可能包含“語義分類模型 + 上下文管理器 + 多輪推理狀態機”。
比如,一個電商公司的客服系統采用這個原則,他們圍繞電商業務,把各個模塊緊密結合起來。當客戶問 “我買的手機啥時候到貨”,系統里的語義分類模型迅速判斷出是詢問物流信息,上下文管理器立刻調出之前下單相關信息,多輪推理狀態機就能給出準確到貨時間。整個過程流暢又高效,客戶體驗那叫一個棒。
1.4 SRP 與松耦合原則
單一責任原則(SRP)和松耦合設計,就像給系統上了一份 “高擴展保險”。
單一責任原則說白了就是各過各的。 把系統里的每個模塊安排得明明白白,每個模塊只負責自己那一畝三分地的事兒。
比如把 “模型調用模塊” 從 “數據預處理模塊” 解耦出來,就像把做飯的和洗碗的安排在不同區域,各干各的,互不干擾。
這樣一來,以后想換推理框架或者加載不同版本模型,就能輕松搞定,不用牽一發而動全身。
有個做 AI 醫療影像分析的團隊,把圖像預處理和模型推理分成兩個完全獨立模塊。后來發現圖像預處理算法在某些情況下效果不好,他們就可以只替換圖像預處理模塊,不用動模型推理模塊,節省時間和精力,系統也能更快適應新需求。
1.5 分層架構與 CAP 法則
架構分層就像把復雜的大蛋糕切成好幾層,每層都有自己的任務,防止邏輯混亂和性能瓶頸。
系統架構要像生日蛋糕分三層:
- 最上層是門衛(API網關),管進進出出
- 中間層是廚師(業務服務),炒菜做飯
- 底層是倉庫(基礎設施),屯糧存貨
比如,一個在線教育平臺剛開始的時候,所有東西堆一塊,結果學生上課卡成PPT。 分層之后,直播、課件、練習各走各的道,就跟商場分電影院、餐飲區、購物區似的,誰也不耽誤誰。
在 AI 系統里,一般分成接入層(如 API 網關),就像系統 “門衛”,所有外部請求先經過它;服務層(如 NLP 服務、推薦服務),就像蛋糕中間層,處理各種核心業務邏輯;基礎設施層(數據、模型、緩存),是蛋糕底層,給上面的層提供堅實基礎。
除此之外,在分布式部署中,必須權衡 CAP 原則:一致性(C)、可用性(A)、分區容錯性(P),就像三個瓶子,只能同時抓住兩個。AI 平臺往往更偏向可用性和分區容錯性,因為 AI 系統面對海量用戶和數據,得保證有些節點掛了,系統還能繼續用。所以使用最終一致性策略來平衡復雜性與性能,就像足球比賽中,某個隊員受傷,其他隊員迅速補位,保證比賽繼續進行。
有個大型 AI 在線教育平臺,采用分層架構,接入層處理學生登錄、課程選擇等請求;服務層負責教學內容推薦和智能答疑;基礎設施層管理教學資源和學生數據。
分布式部署時考慮網絡分區問題,采用最終一致性策略,先保證學生正常上課和提問,等網絡恢復再同步數據。這樣學生上課基本不受影響,保證良好學習體驗。
1.6 高并發法則
數據庫這玩意兒就跟春運的綠皮車似的,擠上兩三千人就廢了。
想扛住億級請求?得有三板斧:
(1) Redis緩存當黃牛:常見結果直接賣"二手票"
(2) Kafka隊列當候車室:先把人囤起來慢慢放
(3) 異步處理叫號機:讓用戶邊逛邊等結果
某AI繪畫APP去年爆火,全靠這三招扛住單日500萬請求。就跟火車站分售票窗、候車廳、叫號系統似的,再多人也不亂。
說的淺顯一點,高并發也很簡單。
剛開始系統都是連接數據庫的,但是要知道數據庫支撐到每秒并發兩三千的時候,基本就快完了。所以才有說,很多公司,剛開始干的時候,技術比較 low,結果業務發展太快,有的時候系統扛不住壓力就掛了。
那咋辦呢?這里有三個關鍵招數:
- 利用 Redis 做模型調用結果緩存。這就像是給系統開了個 “快捷通道”,把之前計算過的結果暫存起來,下次有人問同樣的問題,就不用重新計算了,直接把結果給他,速度一下子就上去了。
- 使用分布式消息隊列(比如 Kafka)削峰填谷。這就像是在系統前挖了個 “緩沖池”,當請求特別多的時候,先把它們放到池子里,等系統有空了再慢慢處理,這樣就能避免系統被瞬間壓垮。
- 把那些需要很長時間才能生成的任務異步處理,前端輪詢返回。這就像是讓顧客先去休息區等著,等他們的任務處理完了,再通知他們來取結果,這樣就不會把前臺給堵死了。
舉個例子,有個很火的 AI 繪畫小程序,一到周末,用戶量就特別大。他們就用了這些辦法,把生成繪畫的任務先放在消息隊列里,等有空了再處理。同時用 Redis 緩存一些常見的繪畫風格和圖案,這樣就能很快地響應用戶的請求,讓用戶不用等太久。
1.7 高可用法則
高可用是命根子:系統掛了算我輸!
多節點集群就像組隊吃雞,隊友倒了立馬換人。K8s自愈機制堪比醫療兵,pod掛了秒復活。健康檢查就是隨身心率帶,節點涼了馬上報警。
去年某翻譯平臺主節點被挖斷光纜,備用節點秒切換,用戶壓根沒察覺。就跟家里停電自動切換發電機似的,燈泡都不帶閃的。
AI系統一般都部署在多節點集群里,這就像是給系統安排了個“小團隊”,每個節點都是團隊成員。為了保證系統不掛,這個團隊得有點“真本事”,具備故障轉移、實例重啟、健康檢查這些高可用能力。
比如說K8s的pod自愈機制,這就像是給系統安排了個“小護士”,一旦發現某個pod(可以理解為系統里的一個小工人)生病了,這個“小護士”就會自動把它修好或者重新啟動。服務探針探活呢,就像是給每個節點安排了個“哨兵”,時刻盯著節點的狀態,要是發現哪個節點不行了,就趕緊報警。SLB多可用區部署,這就像是在不同的地方安排了多個“服務點”,要是某個地方出問題了,用戶還能去其他地方的服務點繼續用服務。
舉個例子,有個提供AI翻譯服務的公司。他們的系統分布在不同的服務器節點上。當某個節點因為網絡問題或者硬件故障掛了,系統里的健康檢查機制能立刻發現,然后把流量轉移到其他健康的節點上。同時,K8s的自愈機制會嘗試修復那個掛掉的節點,要是修不好,就會重新啟動一個新的節點來頂替它。這樣一來,用戶在使用翻譯服務的時候,幾乎感覺不到系統出了問題,服務還是照樣進行。
1.8 高性能法則
咱再聊聊高性能,這可是個大話題。
你琢磨琢磨,為啥AI搜索非得100ms出結果?就跟追公交車似的,晚一秒門就關了!用戶可沒耐心等啊,人家要的是"唰"一下答案就蹦出來。
比如說一個 AI 搜索結果引擎,必須在 100ms 內返回結果,這時間短得就像是一眨眼的工夫。為啥非得這么快呢?因為用戶都希望瞬間就能得到答案,誰愿意在那兒干等著啊?
那到底咋做到呢?說破天就四招:
(1) 模型加速,好比給系統裝氮氣——模型加速,比如用TensorRT把算法壓榨到極致,就跟跑車掛S檔一個道理
(2) 緩存預熱,像極了考前劃重點——熱門股票數據提前塞進Redis,用戶一來秒出結果
(3) 索引設計,堪比超市貨架管理——比如說 milvus 的分層小世界導航 索引, 使得向量搜索的速度,扛扛的
(4) 批量處理,就像外賣湊單——把零散請求打包送貨,省得一趟趟跑腿
比如說有個做 AI 股票分析的平臺。
他們通過模型加速技術,把數據處理的流程優化了一遍,這就好比是給汽車的發動機做了個大保養,讓它能跑得更快。這樣一來,模型就能更快地分析股票走勢。
同時,他們提前把一些熱門股票的數據放到緩存里預熱。這就像是在考試前把重點知識都復習了一遍,等用戶查詢這些股票的時候,幾乎不用等就能看到結果。
通過這些手段,他們的系統就能在很短的時間內給用戶準確的股票分析,幫助用戶做出投資決策。
三、高并發架構設計
高并發架構設計 的兩大 銀彈:
- 讀靠緩存
- 寫靠異步
最后咱嘮嘮高并發讀寫,這又是咋回事呢?
先說讀數據——成千上萬人同時查資料咋辦?直接懟數據庫?那不得炸了!這時候就得請redis 這位緩存大神,進行數據的緩存。Redis緩存當黃牛:常見結果直接賣"二手票"。
那寫數據突然暴增呢?好比雙十一零點搶購,十萬用戶同時下單咋整?硬剛數據庫絕對死翹翹!這時候祭出三件套:
(1) 消息隊列當候車室(Kafka先囤著請求)
(2) 批處理像打包發貨(攢夠1000單一起處理)
(3) 分庫分表好比多開收銀臺(按用戶ID散到不同數據庫)
去年有個社交APP就栽過跟頭。某明星官宣結婚,粉絲瘋狂評論直接把數據庫干崩了。
后來上了這套組合拳,現在每秒十萬條彈幕都不帶喘的。這就跟春運火車站分售票窗、候車廳、檢票口一個道理,再多人也得給我排明白了!
舉個例子,有個做 AI 社交媒體的網站。
當用戶發布狀態或者評論的時候,這些寫請求先放到消息隊列里。等積累到一定數量后,系統就開始忙活,把它們打包處理,然后根據用戶的不同,把數據分散到不同的數據庫表里。
對于讀請求呢,比如說用戶想看別人的狀態 ,系統就用 redis 來快速定位到相關內容。這樣一來,無論是讀還是寫,系統都能順暢地運行,不會出現堵塞的情況。
四、高擴展架構設計
4.1 垂直擴展:升級硬件,撐起初始版本
先說說垂直擴展,這就好比是給系統升級裝備。
剛創業那會咋整?當然是可勁兒堆硬件啊!這就跟租房子先買張豪華床墊似的——A100顯卡懟上,128G內存拉滿,GPU加速庫調教到起飛。簡單粗暴但見效快啊!
當系統剛開始的時候,請求量還不算太大,這時候可以選擇垂直擴展的方式。比如說用 A100 服務器,這就像是給系統住的 “小房子” 升級成 “大房子”,讓它能容納更多的東西。擴充內存呢,就像是給系統多添了幾張 “辦公桌”,讓它能同時處理更多的任務。GPU 加速庫優化,這就像是給系統裝了個 “助力器”,讓它能更快地跑起來。
舉個真實案例,某AI繪畫小作坊起家時就一臺服務器。用戶從每天100漲到1萬時,他們瘋狂升級配置:顯卡從2080換成A100,內存從32G加到256G,活生生把"單間"改造成"一居室"。不過后來用戶破10萬時就抓瞎了——服務器再牛也扛不住,這就要換思路了。
4.2 水平擴展:模塊化部署,集群調度
隨著接入的客戶越來越多,服務橫向擴展就成了必然的選擇。
這就像是從一個人單打獨斗變成一個團隊一起干活。利用 Kubernetes 部署多個副本服務,這就像是安排了很多個 “小兵” 來分擔任務。結合服務注冊與發現、灰度發布、負載均衡策略,就能實現多租戶隔離與資源分配。
舉個例子,有個做智能客服系統的公司。他們把客服模型和文檔問答模型分別部署成兩個微服務。這就像是安排了兩個專門的 “小分隊”,一個負責客服,一個負責回答文檔相關的問題。通過路由控制來分發流量,每個小分隊可以獨立擴容。要是客服咨詢的人多了,就多安排幾個客服小分隊的 “士兵” 來處理請求,文檔問答那邊要是壓力大了,就給文檔問答小分隊增加人手。這樣一來,整個系統就能根據不同的需求靈活調整,不會出現某個部分被壓垮的情況。
五、高性能架構設計
5.1 緩存:快速響應的秘密武器
在 AI 系統里,緩存就像是給系統裝了個 “超級大腦”,能把經常用到的信息暫存起來,方便隨時取用。使用 CDN 緩存模型前端資源,這就像是在離用戶最近的地方放了個 “倉庫”,讓用戶能快速拿到他們需要的東西。瀏覽器本地緩存用戶配置,這就像是給用戶自己留了個 “小抽屜”,放他們自己的個性化設置。Redis 緩存熱門問題的推理結果,這就像是給系統開了個 “熱門問題專區”,那些大家都在問的問題,答案早就準備好了,能直接甩給用戶,這樣可以大大降低請求延遲。
舉個例子,有個很受歡迎的 AI 聊天機器人。他們把一些常見的問題答案緩存在 Redis 里,比如 “今天天氣怎么樣”“你叫啥名字” 這類問題。這樣一來,當用戶問這些問題的時候,系統不用重新推理,直接把答案拿出來就行,速度超快。同時,他們用 CDN 把這些模型的前端資源分散存儲在各個地方,不管用戶在哪兒,都能很快地加載這些資源,讓聊天界面快速顯示出來。
5.2 隊列 + 批處理:應對突發寫入壓力
在大模型訓練平臺上,大量數據標簽、樣本上傳寫入集中發生時,采用 “寫入隊列 + 定時批處理 + 分區提交” 架構,有效避免數據庫寫入擁堵。這就像是在高峰時段,把要上菜的任務先放到一個隊列里,等到稍微空閑一點,再一起把菜做好,分批次端給客人,這樣就不會讓廚房忙得不可開交。
舉個例子,有個做 AI 圖像訓練的公司。當很多用戶同時上傳圖像數據進行標注時,這些寫入請求先放到一個隊列里。系統每隔一段時間就把隊列里的任務打包處理,把數據分散提交到不同的數據庫分區。這樣一來,即使有很多用戶同時上傳數據,系統也不會被瞬間壓垮,能有條不紊地處理這些數據。
5.3 內存池與對象池:減少重復開銷
模型調用涉及大量臨時對象(如 Tokenizer、Context 對象),使用對象池技術可避免 GC 抖動。這就像是在廚房里準備了一堆盤子,用完了直接放回去,下次還能用,不用每次都去洗新的盤子或者買新的盤子,節省時間和資源。
舉個例子,有個做自然語言處理的 AI 系統。他們在處理文本時需要用到大量的 Tokenizer 對象。通過對象池技術,這些用過的 Tokenizer 對象被暫存起來,下次需要的時候直接拿來用,不用重新創建。這樣一來,系統的性能就得到了提升,處理文本的速度也加快了。
所以說啊,高可用、高性能和高并發讀寫,這三者就像是 AI 系統的三大護法,缺一不可。只有把這三者都搞定了,AI 系統才能穩穩地運行,給用戶提供一個又快又穩的服務體驗。這背后啊,都是那些架構設計者們默默付出,想盡各種辦法,用各種巧妙的技術手段來保障系統的穩定和高效。咱們下次再用 AI 系統的時候,不妨也想想這些背后的努力,是不是覺得這技術也挺有意思呢?
六、高可用架構設計
高可用架構設計 ,主要是容錯與容災設計,在系統出問題時,做到 用戶無感
6.1 冗余機制:關鍵服務至少雙活
系統為啥要搞雙活?簡單說就是不能一棵樹上吊死!這就好比給每個重要服務都準備了個替身演員。健康探針就像片場的場記,時刻盯著主演狀態:"哥們還能演不?不行趕緊換替身上!"
舉個真事,某AI圖像平臺去年服務器被黑客攻擊。你猜怎么著?人家背后五個備胎節點瞬間頂上,用戶刷圖的功夫,攻擊流量全被引流到蜜罐系統了。用戶只當是網絡卡了一下,完全不知道后臺在打仗。
AI平臺中,推理服務必須多活部署,并結合健康探針做流量剔除,實現請求的自動轉移。這就像是給系統安排了多個“保鏢”,當一個保鏢被干掉的時候,另一個能立刻頂上,保護用戶的安全。
舉個例子,有個提供AI圖像識別服務的公司。他們的推理服務在多個服務器節點上同時運行。每個節點都有健康探針,就像給每個保鏢配了個“體檢儀”,時刻監測他們的狀態。要是某個節點的探針發現這個節點不太對勁,就會自動把流量切換到其他健康的節點上,保證用戶還能繼續用服務,不會因為某個節點出問題就全軍覆沒。
6.2 數據容災:不能丟的模型與日志
數據丟了咋整?就跟祖傳菜譜燒了似的要命!所以得搞多地備份,像老財主藏寶——床底埋一份,地窖藏一份,城外莊子再存一份。AWS S3跨區同步就是干這個的。
某語音公司吃過血虧,當年機房漏水模型全泡湯。現在學精了,北京存一份,杭州備一份,連成都機房都存著三個月前的版本。就跟咱手機云相冊似的,刪了也能找回來。
使用多地S3同步備份模型、使用異地數據庫災備策略,確保即使主機房斷電,模型服務仍可遷移啟動。這就像是給重要的文件做了多個副本,放在不同的地方,萬一一個地方著火了,其他地方還有備份,不會讓公司的核心資產付之一炬。
舉個例子,有個做AI語音助手的公司。他們在不同的地區都安排了數據備份。本地的機房里有主要的模型和數據,同時在另一個城市的機房里也有備份。一旦本地機房因為某些不可抗力因素掛了,他們可以迅速切換到異地的備份機房,繼續為用戶提供更智能的語音助手服務,用戶幾乎感覺不到中間的切換,服務不會中斷。
6.3 健康檢查與心跳監控:實時掌控狀態
結合Prometheus + Grafana實現全鏈路可視化監控。
這就像是給系統里的每個節點安排了個“健康管家”,它們之間會互相傳遞消息,告訴彼此自己的狀態。要是某個節點覺得自己不太舒服,就會通過 Prometheus和Grafana 告訴大家。
Prometheus和Grafana就像是監控室里的大屏幕,把每個節點的狀態都實時顯示出來,方便運維人員隨時查看。
舉個例子,有個大型的AI云計算平臺。他們的各個服務節點之間 互相傳遞健康狀態信息。要是某個節點因為負載過高或者網絡問題“生病”了,其他節點會立刻知道,并且把這個“生病”的節點從服務列表里摘除,不再給它分配任務。
同時,Prometheus收集各個節點的指標數據,通過Grafana生成直觀的圖表,運維人員在監控室里就能清楚地看到每個節點的CPU使用率、內存占用、請求響應時間等等。一旦發現某個指標異常,就能及時處理,保證整個系統的健康運行。
6.4 熔斷機制:快速失敗避免系統拖垮
系統壓力山大怎么辦?跟家里跳閘一個道理!設置個閾值,比如模型響應超過3秒的就直接掐電。某翻譯軟件就這么干的——高峰期每秒掐掉20%的非緊急請求,保住了核心用戶的體驗。
這就跟醫院急診分診臺似的,輕傷的先等著,重傷的優先處理。雖然有點殘酷,但總比全體癱瘓強。
當模型推理服務超時率超過閾值,自動熔斷,短暫拒絕請求,保護系統不被壓垮。這就像是給系統安了個“緊急制動閥”,當發現情況不對的時候,能立刻剎車,避免系統因為過度負載而徹底崩潰。
舉個例子,有個做AI實時翻譯的系統。在高峰時段,如果翻譯服務的超時率突然飆升,超過了設定的閾值,熔斷機制就會啟動。系統會暫時拒絕一部分新的翻譯請求,同時把現有的任務處理完。這樣可以給系統一點喘息的時間,等壓力稍微緩解之后,再恢復正常服務,避免系統被大量的請求徹底拖垮。
6.5 隔離機制:資源分域、流量分層
為啥要給模型分"包間"?你想想夜店VIP區為啥跟散臺分開?就怕土豪客戶被醉漢影響啊!某AI平臺給每個客戶單獨分配GPU隊列,A客戶的圖像訓練再燒顯卡,也影響不到B客戶的語音識別。
就跟小區供水系統似的,你家水管爆了不會淹了整棟樓。這種隔離設計,讓故障就像被關在玻璃房里的鞭炮——響聲再大也炸不到外面。
將AI模型分租戶隔離運行,每個模型有獨立的GPU Queue、獨立緩存,避免一個模型影響全局。這就像是在商場里給不同的店鋪劃分了獨立的區域,每個店鋪都有自己的收銀臺和倉庫,不會因為某個店鋪的促銷活動導致整個商場的收銀系統癱瘓。
舉個例子,有個提供多種AI模型服務的云平臺。他們把不同的模型分配到不同的租戶里,每個租戶有自己的GPU資源隊列和緩存。比如,一個租戶在做圖像識別模型訓練,另一個租戶在做自然語言處理模型推理。這兩個租戶互不干擾,一個租戶的模型出現故障或者負載過高,不會影響到另一個租戶的模型運行。這樣整個系統的穩定性就大大提高了,不會因為某個模型的“小毛病”導致全局的“大癱瘓”。
6.6 全鏈路監控體系
想知道系統哪里卡殼?得有個上帝視角!QPS像車速表,GPU溫度像油溫表,慢查詢就是發動機故障燈。再加上Jaeger這類追蹤工具,就跟行車記錄儀似的,隨時回看哪段路出了問題。
某在線教育平臺就靠這個,發現半夜兩點總有波峰。一查原來是爬蟲在偷課程數據,立馬上了反爬策略。現在他們的監控大屏,運維小哥看得比股票走勢還認真。
監控指標應包括:請求QPS、推理耗時、GPU使用率、服務錯誤碼、數據庫慢查詢日志等。結合鏈路追蹤(如Skywalking),定位每一次性能抖動。這就像是給系統的每個環節都裝了“攝像頭”,從用戶請求進來,到系統處理,再到返回結果,每個步驟都能被監控到。要是哪個環節出了問題,通過鏈路追蹤就能迅速找到“案發現場”。
舉個例子,有個AI在線教育平臺。他們的全鏈路監控體系能實時監測每個課程的訪問請求量(QPS)、模型推理的耗時、GPU資源的使用情況等等。
一旦發現某個課程的推理耗時突然增加,通過鏈路追蹤工具Skywalking,運維人員就能快速定位到是哪個服務節點或者哪個模型出了問題。比如說,他們發現是因為某個新上線的模型在處理某些特定類型的題目時出現了性能瓶頸,于是就能針對性地進行優化,保證課程的流暢運行。
6.7 API網關與限流控制
誰來把住系統大門?網關就是那個揣著測溫槍的保安。免費用戶每秒只能進10個人(QPS限制),VIP客戶走快速通道。遇到黃牛黨(惡意請求)直接拉黑,見到熟客(帶正確token的)笑臉相迎。
某開放平臺最近逮到個刷API的,每秒請求500次想白嫖算力。網關直接祭出限流大法,把這貨的IP送進小黑屋。就跟超市防小偷似的,門禁系統該狠就得狠。
通過API網關聚合入口,設置QPS限制、認證策略、動態配置,實現靈活、安全的服務訪問控制。這就像是在系統的門口安排了個“門神”,所有的請求都得先經過他。要是請求太多,他就得限制流量,防止系統被擠爆;同時還得驗證每個請求的身份,保證只有合法的請求才能進入系統。
舉個例子,有個做AI開放平臺的公司。他們的API網關會對每個接入的第三方應用進行流量限制。
比如說,一個免費版的應用可能每秒只能發送10次請求,而付費版的可以每秒發送100次。
同時,API網關會對每個請求進行認證,檢查是否攜帶了有效的令牌。如果某個應用超過了流量限制或者令牌無效,API網關就會拒絕這個請求。這樣既能保證系統的穩定運行,又能靈活地管理不同用戶的服務級別。
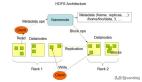
七、數據存儲架構設計
7.1 多類型數據存儲:適配多模態 AI 業務
先來想想,一個 AI 教育平臺,可能會同時處理文本問答、教學視頻、語音評分等任務。這就像是一個餐館要同時做中餐、西餐、日料一樣,得有不同的 “廚房” 來處理不同的食材。
所以說,他們得用不同的存儲方式。
AI平臺數據跟食材似的,得分門別類存放:
- MySQL像冰箱放鮮肉(交易記錄這些規整數據)
- MongoDB是調料架(各種JSON配置隨便塞)
- MinIO當冷庫(視頻音頻這些大家伙)
- Milvus堪比智能櫥柜(特征向量分門別類放)
舉個例子,有個在線語言學習平臺。課程表放MySQL,教學視頻扔MinIO,學生語音特征存Milvus。
這就跟后廚分區管理似的,找啥食材都不會手忙腳亂。
比如說,MySQL 存儲結構化事務數據。這就像是用文件柜來存放那些有固定格式的文件,比如學生的成績、課程安排這些有明確結構的信息。
MongoDB 存儲復雜 JSON 配置。這就像是用一個大雜燴的鍋來煮那些形狀不規則的食材,比如一些復雜的系統配置信息,可能有各種嵌套和不規則的結構。
MinIO 存儲音視頻大文件。這就像是給大件行李安排了個專門的倉庫,專門存放那些體積大的音視頻文件,方便管理和快速取用。
Milvus 存儲向量數據用于相似度檢索。這就像是有個專門用來找相似物品的工具,比如說要找和某個教學視頻風格相似的其他視頻,Milvus 就能快速幫你找出來。
7.2 數據索引與檢索優化:為每一次查詢節省毫秒
找數據最怕啥?大海撈針唄!
在搞 AI 這行當的,都知道構建向量檢索時,把倒排索引和分片機制結合起來,就能像給圖書館的書同時編了索引和分了不同的區域一樣,能顯著提升召回效率。
Elasticsearch就是活地圖,給所有文檔貼標簽、做索引。
Milvus 更絕,直接給向量數據裝GPS,找相似內容比相親匹配還快。
某寫作平臺去年被用戶罵檢索慢,上了FAISS后現在找相似文章只要0.5秒。這就跟從紙質地圖升級到高德導航,效率直接起飛。
舉個例子,有個做 AI 寫作輔助的平臺。他們用 Elasticsearch 來搜索大量的文本資料,比如書籍、文章等,當用戶輸入一個關鍵詞或者短語,系統能快速地在這些文本里找到相關內容。
同時,他們用 Milvus來加速向量檢索,比如說當用戶上傳一篇自己寫的作文,系統能通過向量檢索找到和這篇作文風格相似的其他作文示例,給用戶更多參考和靈感。
7.3 分片策略:靈活擴容的保證
分片策略就像是給數據安排了不同的 “住宿方式”,讓它能根據不同的情況靈活調整。就好比是根據客人的不同需求,把他們安排在不同的房間類型里。
常用的分片策略有:
- Range 分片:這就像是按照時間順序來安排住處,適合那些有明顯時間序列的數據,比如說按照日期來存儲交易記錄。
- Hash 取模分片:這就像是把客人隨機均勻地分配到不同的房間,適合那些需要均勻分布的數據,比如說用戶的基本信息。
- 一致性哈希:這就像是給客人安排了可以靈活調整的房間,方便在動態擴容時,不會讓大部分客人需要換房間。
數據分片就跟租房選戶型似的:
- 時間分片像長租公寓(按年月歸檔日志)
- 哈希分片是合租房(把用戶打散均分)
- 一致性哈希像靈活短租(擴容時不折騰)
舉個例子,有個做電商 AI 推薦系統的平臺。他們用 Range 分片來存儲用戶的購買記錄,按照購買時間來分片,這樣在查詢某個時間段的購買記錄時能很快找到。對于用戶的個人信息,則采用 Hash 取模分片,均勻地分布到不同的數據庫節點上,保證查詢效率。當需要增加新的服務器節點時,采用一致性哈希策略,這樣只有少量的數據需要遷移,不會對系統造成太大影響。
八、高效能架構設計
高效能架構設計,主要是 自動化流水線, DevOps與CI/CD
模型咋從實驗室跑到線上?
DevOps就是自動傳送帶!模型注冊掃碼入庫,驗簽就像奶茶店檢查原料保質期,CI/CD流水線就是全自動封口機。某AI團隊現在每天能上線20個新模型,跟奶茶店出新品速度有一拼。
模型部署流程從模型注冊、模型驗簽、上線發布全部自動化,讓模型迭代速度跟得上業務。這就像是給模型的生產、測試、上線安排了一條自動化流水線,模型就像一個個產品,經過注冊、驗簽、測試等一系列工序后,自動上線發布,不用人工一點點去操作,大大提高了效率。
舉個例子,有個AI科研團隊。他們每天都有新的模型需要部署上線。通過DevOps和CI/CD流程,當模型訓練完成后,自動進行注冊,然后系統會自動對模型進行驗簽,檢查模型是否符合安全標準和質量要求。驗簽通過后,模型會自動上線發布,整個過程不需要人工過多干預。這樣,模型的迭代速度就能跟上業務發展的步伐,科研人員可以更專注于模型的研發,而不是被繁瑣的部署流程拖住后腿。
8大AI系統架構的總結
搞架構設計就像開車,新手只管踩油門,老司機得懂看路況預判風險。你說那些熔斷、隔離、雙活的設計,不就是給系統系安全帶、裝安全氣囊嗎?
見過太多團隊前期圖省事,后期天天救火。就跟裝修不舍得買好電線,住進去三天兩頭跳閘。所以說啊,架構師的眼光得比業務跑得快半步,既要扛得住今天的量,還要兜得住明天的險。
這行當最迷人的地方就在這兒——你設計的每個決策,都在默默守護著千萬用戶的體驗。當用戶絲滑地用著AI功能時,哪知道后臺經歷過多少驚心動魄的戰役?這份深藏功與名的成就感,不就是技術人最好的獎賞嗎?
只有真正理解業務發展背后的節奏變化,洞察架構各層之間的動態關系,系統才能具備持久的生命力。
在每一次并發暴漲、模型熱更、異常故障、業務爆發的背后,都是架構設計者一次次為系統筑牢的“隱形護城河”。
好的架構師就是那位經驗豐富的船長,提前預判風浪,加固船身,讓船能平穩地穿越各種惡劣天氣,安全抵達目的地。
最后,尼恩在這個 祝愿大家都成為一個 架構師, 徹底脫離中年危機,逆天改命。