Linux內存回收機制:系統性能的幕后守護者
在Linux 系統的龐大體系中,內存扮演著極為關鍵的角色,堪稱系統運行的 “血液”。就像血液對于人體,一刻不停地循環流動,為各個器官輸送氧氣和營養物質,維持人體正常運轉一樣,內存為 Linux 系統中的各個進程輸送數據和指令,保障系統的穩定運行。
當我們在 Linux 系統中啟動一個應用程序時,程序的代碼和數據會被加載到內存中。CPU 從內存中讀取這些指令和數據進行處理,處理結果也會暫時存儲在內存中。可以說,內存是連接 CPU 與外部存儲設備(如硬盤)的橋梁。由于 CPU 的運算速度極快,而硬盤等外部存儲設備的讀寫速度相對較慢,如果沒有內存作為數據的臨時存儲和快速交換區域,CPU 在等待數據從硬盤傳輸的過程中會處于空閑狀態,極大地降低系統的整體性能。內存的存在使得 CPU 能夠高效地與外部存儲設備協同工作,讓系統能夠快速響應用戶的操作。
一、內存緊張引發的 “危機”
在 Linux 系統的運行過程中,內存資源并非總是充足的。當系統中運行的進程過多,或者某些進程占用了大量內存時,內存緊張的情況就會出現,這如同人體血液循環不暢,會給系統帶來一系列 “危機”。
最直觀的表現就是系統運行卡頓。當內存緊張時,系統不得不頻繁地將內存中的數據交換到磁盤的虛擬內存(Swap Space)中,這種操作被稱為 Swap。由于磁盤的讀寫速度遠遠低于內存,頻繁的 Swap 會導致系統響應速度大幅下降。比如,在使用 Linux 系統進行多任務處理時,同時打開多個大型文件、運行多個程序,如果內存不足,系統就會出現明顯的卡頓,打開文件的速度變慢,程序之間的切換也變得遲緩,原本流暢的操作變得磕磕絆絆,嚴重影響用戶體驗。
更為嚴重的是,內存緊張還可能導致系統崩潰。當內存資源耗盡,系統無法為新的進程分配內存,也無法滿足現有進程對內存的進一步需求時,就會觸發 OOM(Out Of Memory)機制 ,即內存溢出。OOM Killer 會根據一定的算法選擇并殺死一些占用內存較多的進程,試圖釋放內存資源。但在某些極端情況下,這種方式可能無法有效解決問題,最終導致整個系統崩潰,所有正在運行的程序都將被迫終止,數據丟失,給用戶帶來巨大的損失。
為了避免這些 “危機” 的發生,Linux 系統需要一套高效的內存回收機制,就像人體擁有強大的自我調節能力一樣,及時清理和回收不再使用的內存資源,確保系統的穩定運行。
二、什么時候回收內存?
因為在不同的內存分配路徑中,會觸發不同的內存回收方式,內存回收針對的目標有兩種,一種是針對zone的,另一種是針對一個memcg的,而這里我們只討論針對zone的內存回收,個人把針對zone的內存回收方式分為三種,分別是快速內存回收、直接內存回收、kswapd內存回收。
- 快速內存回收:處于get_page_from_freelist()函數中,在遍歷zonelist過程中,對每個zone都在分配前進行判斷,如果分配后zone的空閑內存數量 < 閥值 + 保留頁框數量,那么此zone就會進行快速內存回收,即使分配前此zone空閑頁框數量都沒有達到閥值,都會進行此zone的快速內存回收。注意閥值可能是min/low/high的任何一種,因為在快速內存分配,慢速內存分配和oom分配過程中如果回收的頁框足夠,都會調用到get_page_from_freelist()函數,所以快速內存回收不僅僅發生在快速內存分配中,在慢速內存分配過程中也會發生。
- 直接內存回收:處于慢速分配過程中,直接內存回收只有一種情況下會使用,在慢速分配中無法從zonelist的所有zone中以min閥值分配頁框,并且進行異步內存壓縮后,還是無法分配到頁框的時候,就對zonelist中的所有zone進行一次直接內存回收。注意,直接內存回收是針對zonelist中的所有zone的,它并不像快速內存回收和kswapd內存回收,只會對zonelist中空閑頁框不達標的zone進行內存回收。并且在直接內存回收中,有可能喚醒flush內核線程。
- kswapd內存回收:發生在kswapd內核線程中,每個node有一個swapd內核線程,也就是kswapd內核線程中的內存回收,是只針對所在node的,并且只會對 分配了order頁框數量后空閑頁框數量 < 此zone的high閥值 + 保留頁框數量 的zone進行內存回收,并不會對此node的所有zone進行內存回收。
這三種內存回收雖然是在不同狀態下會被觸發,但是如果當內存不足時,kswapd內存回收和直接內存回收很大可能是在并發的進行內存回收的。而實際上,這三種回收再怎么不同,進行內存回收的執行代碼是一樣的,只是在內存回收前做的一些處理和判斷不同。
2.1快速內存回收
無論是在快速分配還是慢速分配過程中,只要內核希望從一個zonelist中獲取連續頁框,就必須調用get_page_from_freelist()函數,在此函數中會對zonelist中的所有zone進行判斷,判斷能否從此zone分配連續頁框,而判斷一個zone能否進行分配的唯一標準是:分配后剩余的頁框數量 > 閥值 + 此zone的保留頁框數量。當zone不滿足這個標準,內核會對zone進行快速內存回收,這個快速內存回收的執行路徑是:
get_page_from_freelist() -> zone_reclaim() -> __zone_reclaim() ->shrink_zone()由于篇幅關系,就不列代碼了,之前也說了,/proc/sys/vm/zone_reclaim_mode會影響快速內存回收,在get_page_from_freelist()函數中就有這么一段:
/*
* 判斷是否對此zone進行內存回收,如果開啟了內存回收,則會對此zone進行內存回收,否則,通過距離判斷是否進行內存回收
* zone_allows_reclaim()函數實際上就是判斷zone所在node是否與preferred_zone所在node的距離 < RECLAIM_DISTANCE(30或10)
* 當內存回收未開啟的情況下,只會對距離比較近的zone進行回收
*/
if (zone_reclaim_mode == 0 ||
!zone_allows_reclaim(preferred_zone, zone))
goto this_zone_full;zone_allows_reclaim()用于計算zone與preferred_zone之間的距離,這個跟node距離有關,當距離不滿足時,則不會對此zone進行快速內存回收,也就是當zone_reclaim_mode開啟后,才會對zonelist中的所有zone進行內存回收。
需要注意閥值,之前也說了,在一次分配過程中,可能很多地方會調用get_page_from_freelist()函數,而每次傳入的閥值很可能是不同的,在第一次進行快速分配時,使用的是zone的low閥值進行get_page_from_freelist()調用,在慢速分配過程中,會使用zone的min閥值進行get_page_from_freelist()調用,而在oomkill進行分配過程中,會使用high閥值調用get_page_from_freelist(),當zone的分配后剩余的頁框數量 < 閥值 + 此zone的保留頁框數量 時,則會調用zone_reclaim()對此zone進行內存回收而zone_reclaim()又會調用到__zone_relcaim()。
在__zone_reclaim()中,主要做三件事:初始化一個struct scan_control結構、循環調用shrink_zone()進行對zone的內存回收、從調用shrink_slab()對slab進行回收,struct scan_ control結構初始化如下:
struct scan_control sc = {
/* 最少一次回收SWAP_CLUSTER_MAX,最多一次回收1 << order個,應該是1024個 */
.nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX),
/* 當前進程明確禁止分配內存的IO操作(禁止__GFP_IO,__GFP_FS標志),那么則清除__GFP_IO,__GFP_FS標志,表示不進行IO操作 */
.gfp_mask = (gfp_mask = memalloc_noio_flags(gfp_mask)),
.order = order,
/* 優先級為4,默認是12,會比12一次掃描更多lru鏈表中的頁框,而且掃描次數會比優先級為12的少,并且如果回收過程中回收到了足夠頁框,就會返回 */
.priority = ZONE_RECLAIM_PRIORITY,
/* 通過/proc/sys/vm/zone_reclaim_mode文件設置是否允許將臟頁回寫到磁盤,即使設為允許,快速內存回收也不能對臟文件頁進行回寫操作。
* 當zone_reclaim_mode為0時,在這里是不允許頁框回寫的,
*/
.may_writepage = !!(zone_reclaim_mode & RECLAIM_WRITE),
/* 通過/proc/sys/vm/zone_reclaim_mode文件設置是否允許將匿名頁回寫到swap分區
* 當zone_reclaim_mode為0時,在這里是不允許匿名頁回寫的,我們這里假設允許
*/
.may_unmap = !!(zone_reclaim_mode & RECLAIM_SWAP),
/* 允許對匿名頁lru鏈表操作 */
.may_swap = 1,
/* 本結構還有一個
* .target_mem_cgroup 表示是針對某個memcg,還是針對整個zone進行內存回收的,這里為空,也就是說這里是針對整個zone進行內存回收的
*/
};nr_pages是1<<order。可以看到優先級為4,sc->may_writepage和sc->may_unmap與zone_reclaim_mode有關,這個sc是針對一個zone的,上面也說了,只有當zone不滿足 分配后剩余的頁框數量 > 閥值 + 此zone保留的頁框數量 時,才會對zone進行內存回收,也就是它不是針對整個zonelist進行內存回收的,而是針對不滿足情況的zone進行。再看看循環調用shrink_zone():
do {
/* 對此zone進行內存回收,內存回收的主要函數 */
shrink_zone(zone, &sc);
/* 沒有回收到足夠頁框,并且循環次數沒達到優先級次數,繼續 */
} while (sc.nr_reclaimed < nr_pages && --sc.priority >= 0);可以看到,每次調用shrink_zone后都會sc.priority--,也就是最多進行4次調用shrink_zone(),并且每次調用shrink_zone()掃描的頁框會越來越多,直到回收到了1<<order個頁框為止。
注意:在快速內存回收中,即使zone_reclaim_mode允許回寫,也不會對臟文件頁進行回寫操作的,但是如果zone_reclaim_mode允許,會對非文件頁進行回寫操作。
可以對快速內存回收總結出:
- 開始標志是:此zone分配后剩余的頁框數量 > 此zone的閥值 + 此zone的保留頁框數量(閥值可能是:min,low,high其中一個)。
- 結束標志是:對此zone回收到了本次分配時需要的頁框數量 或者 sc->priority降為0(可能會進行多次shrink_zone()的調用)。
- 回收對象:zone的干凈文件頁、slab、可能會回寫匿名頁
2.2直接內存回收
調用流程:
__alloc_pages_slowpath()
-> __alloc_pages_direct_reclaim()
-> __perform_reclaim()
-> try_to_free_pages()
-> do_try_to_free_pages()
-> shrink_zones() -> shrink_zone()直接內存回收發生在慢速分配中,在慢速分配中,首先喚醒所有node結點的kswap內核線程,然后會調用get_page_from_freelist()嘗試用min閥值從zonelist的zone中獲取連續頁框,如果失敗,則對zonelist的zone進行異步壓縮,異步壓縮之后再次調用get_page_from_freelist()嘗試使用min閥值從zonelist的zone中獲取連續頁框,如果還是失敗,就會進入到直接內存回收。
在進行直接內存回收時,進程是有可能加入到node的pgdat->pfmemalloc_wait這個等待隊列中,當kswapd進行內存回收后如果node空閑內存達到平衡,那么就會喚醒pgdat->pfmemalloc_wait中的進程,其實也就是,加入到pgdat->pfmemalloc_wait這個等待隊列的進程,自身就不會進行直接內存回收,而是讓kswapd進行,之后kswapd會喚醒它們。之后的文章會詳細說明這種情況。
先看初始化的struct scan_control,是在try_to_free_pages()中進行初始化的:
struct scan_control sc = {
/* 打算回收32個頁框 */
.nr_to_reclaim = SWAP_CLUSTER_MAX,
.gfp_mask = (gfp_mask = memalloc_noio_flags(gfp_mask)),
/* 本次內存分配的order值 */
.order = order,
/* 允許進行回收的node掩碼 */
.nodemask = nodemask,
/* 優先級為默認的12 */
.priority = DEF_PRIORITY,
/* 與/proc/sys/vm/laptop_mode文件有關
* laptop_mode為0,則允許進行回寫操作,即使允許回寫,直接內存回收也不能對臟文件頁進行回寫
* 不過允許回寫時,可以對非文件頁進行回寫
*/
.may_writepage = !laptop_mode,
/* 允許進行unmap操作 */
.may_unmap = 1,
/* 允許進行非文件頁的操作 */
.may_swap = 1,
};在直接內存回收過程中,這個sc結構是對zonelist中所有zone使用的,而不是像快速內存回收,是針對zonelist中不滿足條件的一個一個zone進行使用,對于直接內存回收,以下需要注意:
sc的c初始使用的是默認的優先級12,那么就會對遍歷12遍zonelist中的所有zone,每次遍歷后sc->priority--,相當于讓每個zone執行12次shrink_zone()
只有sc->priority == 12時會對zonelist中的所有zone強制執行shrink_zone(),而當sc->priority == 12這輪循環過后,會通過判斷來確定zone是否要執行shrink_zone(),這個判斷標志就是:此zone已經掃描的頁數 < (此zone所有沒有鎖在內存中的文件頁和非文件頁之和 * 6) 。如果掃描頁數超過此值,就說明已經對此zone掃描過太多頁框了,就不對此zone進行shrink_zone()了。
并且當優先級降到10以下時,即使原來sc->may_writepage不允許回寫,這時候會開始允許回寫。這樣做是因為不回寫很難回收到頁框。
只打算回收的頁框為32個,并且在此期間,如果掃描頁數超過(sc->nr_to_reclaim + sc->nr_to_reclaim / 2),則是會根據laptop_mode的情況喚醒flush內核線程的。
直接內存回收無論如何都不會對臟文件頁進行回寫操作,如果sc->may_writepage為1,那么會對非文件頁進行回寫操作
- 會對文件頁和非文件頁進行unmap操作
- 會對非文件頁處理(加入swap cache,unmap,回寫)
- 會先回收在memcg中并且超過所在memcg的soft_limit_in_bytes的進程的內存
- 也會調用shrink_slab()對slab進行回收
個人認為直接內存回收是為了讓更多的頁得到掃描,然后進行回寫操作,也可能是為了后面的內存壓縮回收一些頁框,其實這里不太理解,為什么只回收32個頁框,它并不像直接內存回收,打算回收的頁框數量是1<<order。
可以對直接內存回收總結出:
- 開始標志是:zonelist的所有zone都不能通過min閥值獲取到頁框時。
- 結束標志:回收到32個頁框,或者sc->priority降到0,或者空閑頁框足夠進行內存壓縮了(可能會進行多次shrink_zone()的調用)。
- 回收對象:超過所在memcg的soft_limit_in_bytes的進程的內存、zone的干凈文件頁、slab、匿名頁swap
2.3kswapd內存回收
調用過程:
-> balance_pgdat() -> kswapd_shrink_zone() -> shrink_zone()在分配過程中,只要get_page_from_freelist()函數無法以low閥值從zonelist的zone中獲取到連續頁框,并且分配內存標志gfp_mask沒有標記__GFP_NO_KSWAPD,則會喚醒kswapd內核線程,在當中執行kswapd內存回收,先看初始化的sc結構:
/* 掃描控制結構 */
struct scan_control sc = {
/* (__GFP_WAIT | __GFP_IO | __GFP_FS)
* 此次內存回收允許進行IO和文件系統操作,有可能阻塞
*/
.gfp_mask = GFP_KERNEL,
/* 分配內存失敗時使用的order值,因為只有分配內存失敗才會喚醒kswapd */
.order = order,
/* 這個優先級決定了一次掃描多少隊列 */
.priority = DEF_PRIORITY,
.may_writepage = !laptop_mode,
.may_unmap = 1,
.may_swap = 1,
};由于此sc是針對整個node的所有zone的,這里沒有設置sc->nr_to_reclaim,在確定對某個zone進行內存回收時,這個sc->nr_to_reclaim被設置為:
sc->nr_to_reclaim = max(SWAP_CLUSTER_MAX, high_wmark_pages(zone));可以看到,如果回收的頁框數量達到了zone的high閥值,其實意思就是盡可能的回收頁框了,kswapd內核線程是每個node有一個的,那也意味著,此node的kswapd只會對此node的zone進行內存回收工作,也就不需要zonelist了。
要點:
優先級使用默認為的12,會執行多次遍歷node(并不是node中的所有zone),但并不會每次遍歷都進行sc->priority--,當能夠回收的內存時,才進行sc->priority--以ZONE_HIGHMEM -> ZONE_NORMAL ->ZONE_DMA的順序找出第一個不平衡的zone,平衡條件是: 此zone分配頁框后剩余的頁框數量 > 此zone的high閥值 + 此zone保留的頁框數量。不滿足則表示此zone不平衡。
對第一個不平衡的zone及其后面的zone進行回收在memcg中并且超過所在memcg的soft_limit_in_bytes的進程的內存,比如第一個不平衡的zone是ZONE_NORMAL,那么執行內存回收的zone就是ZONE_NORMAL和ZONE_DMA。
如果zone是平衡的,則不對zone進行內存回收(但是上面那部不會因為zone平衡而不執行),而如果zone是不平衡的,那么會調用shrink_zone()進行內存回收,以及調用shrink_slab()進行slab的回收。
對于node中所有 zone分配后剩余內存 < zone的low閥值 + zone保留的頁框數量 的zone,會進行內存壓縮
檢查node中所有zone是否都平衡,沒有平衡則繼續循環
如果laptop == 0,那么會對文件頁和非文件頁進行回寫操作,如果laptop == 1,那么只有當sc->priority < 10時才會對文件頁和非文件頁進行回寫操作
會對文件頁和非文件頁進行回寫unmap操作
會對非文件頁進行處理(加入swapcache,unmap,回寫)
可以看出來,kswapd內存回收會將node結點中的所有zone的空閑頁框都至少拉高high閥值。
可以對kswapd內存回收總結出:
- 開始標志:zonelist的所有zone都不能通過min閥值獲取到頁框時,會喚醒所有node的kswapd內核線程,然后在kswapd中會對不滿足 zone分配頁框后剩余的頁框數量 > 此zone的high閥值 + 此zone保留的頁框數量 的zone進行內存回收。
- 結束標志:node中所有zone都滿足 zone分配頁框后剩余的頁框數量 > 此zone的high閥值 + 此zone保留的頁框數量(可能會進行多次shrink_zone()的調用)。
- 回收對象:超過所在memcg的soft_limit_in_bytes的進程的內存、zone的干凈的文件頁、zone的臟的文件頁、slab、匿名頁swap
2.4回收哪些內存
(1)Page Cache
CPU如果要訪問外部磁盤上的文件,需要首先將這些文件的內容拷貝到內存中,由于硬件的限制,從磁盤到內存的數據傳輸速度是很慢的,如果現在物理內存有空余,干嘛不用這些空閑內存來緩存一些磁盤的文件內容呢,這部分用作緩存磁盤文件的內存就叫做page cache。
用戶進程啟動read()系統調用后,內核會首先查看page cache里有沒有用戶要讀取的文件內容,如果有(cache hit),那就直接讀取,沒有的話(cache miss)再啟動I/O操作從磁盤上讀取,然后放到page cache中,下次再訪問這部分內容的時候,就又可以cache hit,不用忍受磁盤的龜速了(比內存慢幾個數量級)。
和CPU里的硬件cache是不是很像?兩者其實都是利用的局部性原理,只不過硬件cache是CPU緩存內存的數據,而page cache是內存緩存磁盤的數據,這也體現了memory hierarchy分級的思想。
相對于磁盤,內存的容量還是很有限的,所以沒必要緩存整個文件,只需要當文件的某部分內容真正被訪問到時,再將這部分內容調入內存緩存起來就可以了,這種方式叫做demand paging(按需調頁),把對需求的滿足延遲到最后一刻,很懶很實用。
page cache中那么多的page frames,怎么管理和查找呢?這就要說到之前的文章提到的address_space結構體,一個address_space管理了一個文件在內存中緩存的所有pages。這個address_space可不是進程虛擬地址空間的address space,但是兩者之間也是由很多聯系的。
上文講到,mmap映射可以將文件的一部分區域映射到虛擬地址空間的一個VMA,如果有5個進程,每個進程mmap同一個文件兩次(文件的兩個不同部分),那么就有10個VMA,但address_space只有一個。每個進程打開一個文件的時候,都會生成一個表示這個文件的strut file,但是文件的struct inode只有一個,inode才是文件的唯一標識,指向address_space的指針就是內嵌在inode結構體中的。在page cache中,每個page都有對應的文件,這個文件就是這個page的owner,address_space將屬于同一owner的pages聯系起來,將這些pages的操作方法與文件所屬的文件系統聯系起來。
來看下address_space結構體具體是怎樣構成的:
struct address_space {
struct inode *host; /* Owner, either the inode or the block_device */
struct radix_tree_root page_tree; /* Cached pages */
spinlock_t tree_lock; /* page_tree lock */
struct prio_tree_root i_mmap; /* Tree of private and shared mappings */
struct spinlock_t i_mmap_lock; /* Protects @i_mmap */
unsigned long nrpages; /* total number of pages */
struct address_space_operations *a_ops; /* operations table */
...
}- host指向address_space對應文件的inode。
- address_space中的page cache之前一直是用radix tree的數據結構組織的,tree_lock是訪問這個radix tree的spinlcok(現在已換成xarray)。
- i_mmap是管理address_space所屬文件的多個VMA映射的,用priority search tree的數據結構組織,i_mmap_lock是訪問這個priority search tree的spinlcok。
- nr_pages是address_space中含有的page frames的總數。
- a_ops是關于page cache如何與磁盤(backing store)交互的一系列operations。
(2)從Radix Tree到XArray
radix tree的每個節點可以存放64個slots(由RADIX_TREE_MAP_SHIFT設定,小型系統為了節省內存可以配置為16),每個slot的指針指向下一層節點,最后一層slot的指針指向struct page(關于struct page請參考這篇文章),因此一個高度為2的radix tree可以容納64個pages,高度為3則可以容納4096個pages。
如何在radix tree中找到一個指定的page呢?那就要回顧下struct page中的mapping和index了,mapping指向page所屬文件對應的address_space,進而可以找到address_space的radix tree,index既是page在文件內的offset,也可作為查找這個radix tree的索引,因為radix tree就是按page的index來組織struct page的。這里是用page index中的一部分bit位作為radix tree第一層的索引,另一部分bit位作為第二層的索引,以此類推。因為一個radix tree節點存放64個slots,因此一層索引需要6個bits,如果radix tree高度為2,則需要12個bits。
內核中具體的查找函數是find_get_page(mapping, offset),如果在page cache中沒有找到,就會觸發page fault,調用__page_cache_alloc()在內存中分配若干物理頁面,然后將數據從磁盤對應位置copy過來,通過add_to_page_cache()-->radix_tree_insert()放入radix tree中。在將一個page添加到page cache和從page cache移除時,需要將page和對應的radix tree都上鎖。
linux中radix tree的每個slot除了存放指針,還存放著標志page和磁盤文件同步狀態的tag。如果page cache中一個page在內存中被修改后沒有同步到磁盤,就說這個page是dirty的,此時tag就是PAGE_CACHE_DIRTY。如果正在同步,tag就是PAGE_CACHE_WRITEBACK。只要下一層中有一個slot指向的page是dirty的,那么上一層的這個slot的tag就是PAGE_CACHE_DIRTY的,就像一滴墨水一樣,放入清水后,清水也就不再完全清澈了。
前面介紹struct page中的flags時提到,flags可以是PG_dirty或PG_writeback,既然struct page中已經有了標識同步狀態的信息,為什么這里radix tree還要再加上tag來標記呢?這是為了管理的方便,內核可以據此快速判斷某個區域中是否有dirty page或正在write back的page,而無須掃描該區域中的所有pages。
(3)Reverse Mapping
要回收一個page,可不僅僅是釋放掉那么簡單,別忘了linux中進程和內核都是使用虛擬地址的,多少個PTE頁表項還指向這個page呢,回收之前,需要將這些PTE中P標志位設為0(not present),同時將page的物理頁面號PFN也全部設成0,要不然下次PTE指向的位置存放的就是無效的數據了。可是struct page中好像并沒有一個維護所有指向這個page的PTE組成的鏈表。
前面的文章說過,struct page數量極其龐大,如果每個page都有這樣一個鏈表,那將顯著增加內存占用,而且PTE中的內容是在不斷變化的,維護這一鏈表的開銷也是不小的。那如何找到這些PTE呢?從虛擬地址映射到物理地址是正向映射,而通過物理頁面尋址映射它的虛擬地址,叫reverse mapping(逆向映射)。page的確沒有直接指向PTE的反向指針,但是page所屬的文件是和VMA有mmap線性映射關系的啊,通過page在文件中的offset/index,就可以知道VMA中的哪個虛擬地址映射了這個page。
在代碼中的實現是這樣的:
__vma_address(struct page *page, struct vm_area_struct *vma)
{
pgoff_t pgoff = page_to_pgoff(page);
return vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT);
}映射了某個address_space中至少一個page的所有進程的所有VMA,就共同構成了這個address_space的priority search tree(PST)。PST是一種糅合了radix tree和heap的數據結構,其實現較為復雜,現在已經被基于augmented rbtree的interval tree所取代。
對比一下,一個進程所含有的所有VMA是通過鏈表和紅黑樹組織起來的,一個文件所對應的所有VMA是通過基于紅黑樹的interval tree組織起來的。因此,一個VMA被創建之后,需要通過vma_link()插入到這3種數據結構中。
三、Linux內存回收機制
2.1回收對象:匿名頁與文件頁
在 Linux 系統中,內存回收主要針對匿名頁和文件頁展開。匿名頁是一種比較特殊的內存頁,它不像文件頁那樣與磁盤上的文件存在直接映射關系,通常用于存儲進程的堆、棧數據等 。當系統需要回收匿名頁時,會篩選出那些訪問頻率較低、不經常使用的匿名頁,將它們寫入到 swap 分區中。swap 分區就像是內存的 “臨時倉庫”,當內存空間緊張時,把暫時不用的數據存放到這里,等需要時再取回來。寫入 swap 分區后,這些匿名頁就可以作為空閑頁框釋放到伙伴系統,供其他進程申請使用,從而有效緩解內存壓力。
文件頁則涵蓋了內核緩存的磁盤數據(Buffer)以及內核緩存的文件數據(Cache)。在回收文件頁時,系統會先判斷文件頁的狀態。如果文件頁保存的內容與磁盤中文件對應內容一致,即該文件頁是干凈的,那么無需進行回寫操作,可直接將其作為空閑頁框釋放到伙伴系統;反之,如果文件頁保存的數據和磁盤中文件對應的數據不一致,這樣的文件頁被稱為臟頁,就需要先將其回寫到磁盤中對應數據所在的位置,確保數據的一致性,然后才能作為空閑頁框釋放 。
例如,當我們編輯一個文本文件時,在保存之前,文件在內存中的對應頁就是臟頁,只有保存后,數據寫入磁盤,相應的文件頁才會變成干凈頁。通過這種有針對性的回收策略,系統能夠合理地管理內存資源,提高內存的使用效率。
2.2zone:內存回收的基本單位
在 Linux 系統中,內存回收是以 zone 為基本單位進行的。zone 是對內存的一種邏輯劃分,它將物理內存按照不同的特性和用途進行分類管理,主要包括 DMA zone、Normal zone 和 HighMem zone 等 。不同的 zone 適用于不同類型的內存訪問需求,例如,DMA zone 主要用于直接內存訪問設備,Normal zone 用于常規的內存分配,而 HighMem zone 用于高端內存的管理。
在每個 zone 中,都有三條重要的閾值線,即 watermark [WMARK_MIN](最小閾值)、watermark [WMARK_LOW](低閾值)和 watermark [WMARK_HIGH](高閾值),它們在內存分配和回收過程中起著關鍵的判斷和觸發作用。當系統進行內存分配時,如果是快速分配,默認會以 watermark [WMARK_LOW] 作為閾值進行判斷。
如果某個 zone 的空閑頁數量低于這個低閾值,說明該 zone 的內存資源較為緊張,系統會立即對該 zone 執行快速內存回收操作,以獲取更多的空閑內存,滿足當前的內存分配請求 。比如,當一個新的進程啟動需要申請內存時,如果發現所在 zone 的空閑頁數量低于低閾值,系統就會迅速啟動快速內存回收,優先保障新進程的內存需求。
若快速內存分配失敗,系統會進入慢速分配階段,此時會使用 watermark [WMARK_MIN] 這個最小閾值進行內存分配。如果即使使用最小閾值也無法完成內存分配,那就意味著系統內存極度緊張,會觸發直接內存回收以及快速內存回收機制,盡力從各個方面回收內存,避免因內存不足導致系統出現異常。
而 watermark [WMARK_HIGH] 代表著 zone 對于空閑頁數量比較滿意的一個數值狀態 。當 zone 的空閑頁數量高于這個高閾值時,說明該 zone 的內存資源充足,系統處于比較良好的運行狀態;當對 zone 進行內存回收時,通常會將目標設定為把 zone 的空閑頁數量提高到此高閾值以上,使內存資源達到一個較為理想的平衡狀態 。在系統運行過程中,通過不斷地根據這三條閾值線對內存進行監控和調整,Linux 系統能夠有效地管理內存資源,保障系統的穩定運行和高效性能。我們可以通過/proc/zoneinfo文件查看各個 zone 的這三個閾值的具體數值,以便更好地了解系統內存狀態。
四、Linux內存回收的方式
4.1zone的閥值
內存回收是以zone為單位進行的(也會以memcg為單位,這里不討論這種情況),而系統判斷一個zone需不需要進行內存回收,如上面所說,為zone設置一條線,當此zone的空閑頁框不足以到達這條線時,就會對此zone進行內存回收,實際上一個zone有三條線,這三條線分別是最小閥值(WMARK_MIN),低閥值(WMARK_LOW),高閥值(WMARK_HIGH),它們都保存在zone的watermark[NR_WMARK]數組中,這個數組中保存的是各個閥值要求的頁框數量,而每個閥值都會對內存回收造成影響。而它們的描述如下:
- watermark[WMARK_MIN](min閥值):在快速分配失敗后的慢速分配中會使用此閥值進行分配,如果慢速分配過程中使用此值還是無法進行分配,那就會執行直接內存回收和快速內存回收
- watermark[WMARK_LOW](low閥值):也叫低閥值,是快速分配的默認閥值,在分配內存過程中,如果zone的空閑頁框數量低于此閥值,系統會對zone執行快速內存回收
- watermark[WMARK_HIGH](high閥值):也叫高閥值,是zone對于空閑頁框數量比較滿意的一個值,當zone的空閑頁框數量高于這個值時,表示zone的空閑頁框較多。所以對zone進行內存回收時,目標也是希望將zone的空閑頁框數量提高到此值以上,系統會使用此閥值用于oomkill進行內存回收。
這三個閥值的關系是:min閥值 < low閥值 < high閥值。在系統初始化期間,根據系統中整個內存的數量與每個zone管理的頁框數量,計算出每個zone的min閥值,然后low閥值 = min閥值 + (min閥值 / 4),high閥值 = min閥值 + (min閥值 / 2)。這樣就得出了這三個閥值的數值,我們可以通過/proc/zoneinfo中查看這三個閥值的數值:
可以很明顯看出來,相對于整個zone管理的總頁框數量(managed),這三個值是非常非常小的,連managed的1%都不到,這些都是在系統初始化期間進行設置的,具體設置函數是__setup_per_zone_wmarks()。有興趣的可以去看看。這個閥值對內存回收的進行具有很重要的意義,后面會詳細進行說明。
對于zone的內存回收,它針對三樣東西進程回收:slab、lru鏈表中的頁、buffer_head。這里只討論內存回收針對lru鏈表中的頁是如何進行回收的。lru鏈表主要用于管理進程空間中使用的內存頁,它主要管理三種類型的頁:匿名頁、文件頁以及shmem使用的頁。在內存回收過程中,說簡單些,就是將lru鏈表中的一些頁數據放到磁盤中,然后將這些頁釋放,當然實際上可沒有那么簡單,這個后面會詳細說明。
在說內存回收前,要先補充一些知識,因為內存回收并不是一個孤立的功能,它內部會涉及到其他很多東西,比如內存分配、lru鏈表、反向映射、swapcache、pagecache等。
(1)頁描述符頁描述符中對內存回收來說非常必要的標志:
- PG_lru:表示頁在lru鏈表中
- PG_referenced: 表示頁最近被訪問(只有文件頁使用)
- PG_dirty:頁為臟頁,文件頁被修改,以及非文件頁加入到swap cache后,就會被標記為臟頁。在此頁回寫前會被清除,但是回寫失敗時又會被置位
- PG_active:頁為活動頁,配合PG_lru就可以得出頁是處于非活動頁lru鏈表還是活動頁lru鏈表
- PG_private:頁描述符中的page->private保存有數據
- PG_writeback:頁正在進行回寫
- PG_swapbacked:此頁可寫入swap分區,一般用于表示此頁是非文件頁
- PG_swapcache:頁已經加入到了swap cache中(只有非文件頁使用)
- PG_reclaim:頁正在進行回收,只有在內存回收時才會對需要回收的頁進行此標記
- PG_mlocked:頁被鎖在內存中
在內核中,只有一種頁能夠進行回收,就是頁描述符中的_count為0的頁,每個頁都有自己唯一的頁描述符,而每個頁描述符中都有一個_count,這個_count代表的是此頁的引用計數,當_count為-1時,說明此頁是空閑的,存放在伙伴系統中,每當有一個進程映射了此頁時,此頁的_count就會++,也就是當某個頁被10個進程映射了,它的page->_count肯定大于10(不等于10是因為可能還有其他模塊引用了此頁,比如塊層、驅動等),所以也可以反過來說,如果某個頁的page->_count == 0,那就說明此頁可以直接釋放回收了。
也就是說,內核實際上回收的是那些page->_count == 0的頁,但是如果真的是這樣,內存回收這就沒有任何意義了,因為當最后一個引用此頁的模塊釋放掉此頁的引用時,如果page->_count為0,肯定會釋放回收此頁的。實際上內存回收做的事情,就是想辦法將一些page->_count不為0的頁,嘗試將它們的page->_count降到0,這樣系統就可以回收這些頁了。下面是我總結出來在內存回收過程中會對頁的page->_count產生影響的操作:
- 一個進程映射此頁,page->_count++
- 一個進程取消映射此頁,page->_count--
- 此頁加入到lru緩存中,page->_count++
- 此頁從lru緩存加入到lru鏈表中,page->_count--
- 此頁被加入到一個address_space中,page->_count++
- 此頁從address_space中移除時,page->_count--
- 文件頁添加了buffer_heads,page->_count++
- 文件頁刪除了buffer_heads,page->_count--
- swap分區
4.2lru鏈表
lru鏈表主要作用就是將頁排序,將最應該回收的頁放到最后面,最不應該回收的頁放到最前面,,然后進行內存回收時,就會從后面向前面進行掃描,將掃描到的頁嘗試進行回收。這里只需要記住一點,回收的頁都是非活動匿名頁lru鏈表或者非活動文件頁lru鏈表上的頁。這些頁包括:進程堆、棧、匿名mmap共享內存映射、shmem共享內存映射使用的頁、映射磁盤文件的頁。
(1)頁的換入換出
首先先說明一下頁描述符中對內存回收來說非常必要的標志:
- PG_lru:表示頁在lru鏈表中
- PG_referenced: 表示頁最近被訪問(只有文件頁使用)
- PG_dirty:頁為臟頁,文件頁被修改,以及非文件頁加入到swap cache后,就會被標記為臟頁。在此頁回寫前會被清除,但是回寫失敗時又會被置位
- PG_active:頁為活動頁,配合PG_lru就可以得出頁是處于非活動頁lru鏈表還是活動頁lru鏈表
- PG_private:頁描述符中的page->private保存有數據
- PG_writeback:頁正在進行回寫
- PG_swapbacked:此頁可寫入swap分區,一般用于表示此頁是非文件頁
- PG_swapcache:頁已經加入到了swap cache中(只有非文件頁使用)
- PG_reclaim:頁正在進行回收,只有在內存回收時才會對需要回收的頁進行此標記
- PG_mlocked:頁被鎖在內存中(此標志可以保證不被換出,但是無法保證不被被做內存遷移)
內存回收做的事情就是想辦法將目標頁的page->_count降到0,對于那些沒有進程映射了頁,釋放起來就很簡單,如果頁映射了磁盤文件,并且頁為臟頁(被寫過),那就就把頁中的數據回寫到磁盤中映射的文件中,而如果頁沒有映射磁盤文件,那么直接釋放即可。但是對于有進程映射的頁,如果此頁映射了磁盤文件,并且頁為臟頁,那么和之前一樣,將此頁進行回寫,然后釋放回收即可,但是此頁沒有映射磁盤文件,情況就會稍微復雜,會將頁數據寫入到swap分區中,然后將此頁釋放回收。總結如下:
- 干凈頁,并且映射了磁盤文件的頁,直接回收
- 臟頁(PG_dirty置位),回寫到對應磁盤文件中,然后回收
- 沒有進程映射,并且沒有映射磁盤文件的頁,直接回收
- 有進程映射,并且沒有映射磁盤文件的頁,回寫到swap分區中,然后回收
接下來會分為非活動匿名頁lru鏈表的頁的換入換出,非活動文件頁lru鏈表的頁的換入換出進行描述。
匿名頁lru鏈表上保存的頁為:進程堆、棧、數據段,匿名mmap共享內存映射,shmem映射。這些類型的頁都有個特點,在磁盤上沒有映射對應的文件(shmem有對應的文件,是/dev/zero,但它不是映射此設備文件)。而在內存回收時,會從非活動匿名頁lru鏈表末尾向前掃描一定數量的頁框,然后嘗試將這些頁框進行回收,而如果這些頁框沒有進程映射它們,那么它們可以直接釋放,而如果有進程映射了它們,那么系統就必須將這些頁框回寫到磁盤上。在linux系統中,你可以給系統掛載一個swap分區,這個分區就是專門用于保存這些類型的頁的。
當這些頁需要回收,并且有進程映射了它們時,系統就會將這些頁寫入swap分區,需要注意,它們需要回收只有在內存不足進行內存回收時才會發生,也就是當系統內存充足時,是不會將這些類型的頁寫入到swap分區中的(使用memcg除外),在磁盤上,一個swap分區是一組連續的物理扇區,比如一個1G大小的swap分區,那么它在磁盤上會占有1G大小磁盤塊,然后這塊磁盤塊的第一個4K,專門用于存swap分區描述結構的,而之后的磁盤塊,會被劃分為一個一個4K大小的頁槽(正好與普通頁大小一致),然后將它們標以ID,如下:
每個頁槽可以保存一個頁的數據,這樣,一個被換出的頁就可以寫入到磁盤中,系統也能夠將這些頁組織起來了。雖然是叫swap分區,但是內核似乎并不將swap分區當做一個磁盤分區來看待,更像的是將其當做一個文件來看待,因為這個,每個swap分區都有一個address_space結構,這個結構是每個磁盤文件都會有一個的,這個address_space結構中最重要的是有一個基樹和一個address_space操作集。而這里swap分區有一個,swap分區的address_space叫做swap cache,它的作用是從非文件頁在回寫到swap分區到此非文件頁被回收前的這段時間里,起到一個將swap類型的頁表項與此頁關聯的作用和同步的作用。在這個swap cache的基樹中,將此swap分區的所有頁槽組織在了一起。當非活動匿名頁lru鏈表中的一個頁需要寫入到swap分區時,步驟如下:
- swap分配一個空閑的頁槽
- 根據這個空閑頁槽的ID,從swap分區的swap cache的基樹中找到此頁槽ID對應的結點,將此頁的頁描述符存入當中
- 內核以頁槽ID作為偏移量生成一個swap頁表項,并將這個swap頁表項保存到頁描述符中的private中
- 對頁進行反向映射,將所有映射了此頁的進程頁表項改為此swap頁表項
- 將此頁的mapping改為指向此swap分區的address_space,并將此頁設置為臟頁
- 通過swap cache中的address_space操作集將此頁回寫到swap分區中
- 回寫完成
- 此頁要被回收,將此頁從swap cache中拿出來
當一個進程需要訪問此頁時,系統則會將此頁從swap分區換入內存中,具體步驟如下:
- 一個進行訪問了此頁,會先訪問到之前設置的swap頁表項
- 產生缺頁異常,在缺頁異常中判斷此頁在swap分區中,而不在內存中
- 分配一個新頁
- 根據進程的頁表項中的swap頁表項找到對應的頁槽和swap cache
- 如果以頁槽ID在swap cache中沒有找到此頁,說明此頁已被回收,從分區中將此頁讀取進來
- 如果以頁槽ID在swap cache中找到了此頁,說明此頁還在內存中,還沒有被回收,則直接映射此頁
這樣再此頁沒有被換出或者正在換出的情況下,所有映射了此頁的進程又可以重新訪問此頁了,而當此頁被完全換出到swap分區然后被回收后,此頁就會從swap cache中移除,之后如果進程想要訪問此頁,就需要等此頁被完全換入之后才行了。也就是這個swap cache完全為了提高效率,在頁沒有被回收前,即使此頁已經回寫到swap分區了,只要有進映射此頁,就可以直接映射內存中的頁,而不需要將頁從磁盤讀進來。對于非活動匿名頁lru鏈表上的頁進行換入換出這里就算是說完了。記住對于非活動匿名頁lru鏈表上的頁來說,當此頁加入到swap cache中時,那么就意味著這個頁已經被要求換出,然后進行回收了。
但是相反文件頁則不是這樣,接下來簡單說說映射了磁盤文件的文件頁的換入換出,實際上與非活動匿名頁lru鏈表上的頁進行換入換出是一模一樣的,因為每個磁盤文件都有一個自己的address_space,這個address_space就是swap分區的address_space,磁盤文件的address_space稱為page cache,接下來的處理就是差不多的,區別為以下三點:
- 對于磁盤文件來說,它的數據并不像swap分區這樣是連續的。
- 當文件數據讀入到一個頁時,此文件頁就需要在文件的page cache中做關聯,這樣當其他進程也需要訪問文件的這塊數據時,通過page cache就可以知道此頁在不在內存中了。
- 并不會為映射了此文件頁的進程頁表項生成一個新的頁表項,會將所有映射了此頁的頁表項清空,因為在缺頁異常中通過vma就可以判斷發生缺頁的頁是映射了文件的哪一部分,然后通過文件系統可以查到此頁在不在內存中。而對于匿名頁的vma來說,則無法做到這一點。
4.3內存分配過程
要說清楚內存回收,就必須要先理清楚內存分配過程,在調用alloc_page()或者alloc_pages()等接口進行一次內存分配時,最后都會調用到__alloc_pages_nodemask()函數,這個函數是內存分配的心臟,對內存分配流程做了一個整體的組織。主要需要注意的,就是在__alloc_pages_nodemask()中會進行一次使用low閥值的快速內存分配和一次使用min閥值的慢速內存分配,快速內存分配使用的函數是get_page_from_freelist(),這個函數是分配頁框的基本函數,也就是說,在慢速內存分配過程中,收集到和足夠數量的頁框后,也需要調用這個函數進行分配。先簡單說明快速內存分配和慢速內存分配:
- 快速內存分配:是get_page_from_freelist()函數,通過low閥值從zonelist中獲取合適的zone進行分配,如果zone沒有達到low閥值,則會進行快速內存回收,快速內存回收后再嘗試分配。
- 慢速內存分配:當快速分配失敗后,也就是zonelist中所有zone在快速分配中都沒有獲取到內存,則會使用min閥值進行慢速分配,在慢速分配過程中主要做三件事,異步內存壓縮、直接內存回收以及輕同步內存壓縮,最后視情況進行oom分配。并且在這些操作完成后,都會調用一次快速內存分配嘗試獲取頁框。
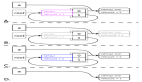
通過以下這幅圖,來說明流程:
說到內存分配過程,就必須要說說中的preferred_zone和zonelist,preferred_zone可以理解為內存分配時,最希望從這個zone進行分配,而zonelist理解為,當沒辦法從preferred_zone分配內存時,則根據zonelist中zone的順序嘗試進行分配,為什么會有這兩個參數,是因為numa架構導致的,我們知道,當有多個node結點時,CPU跨結點訪問內存是效率比較低的工作,所以CPU會優先在本node上的zone進行內存分配工作,如果本node上實在分配不出內存,那就嘗試在離本node最近的node上分配,如果還是無法分配到,那就找再下一個node。這樣每個node會將其他node的距離進行一個排序形成了其他node的一個鏈表,這個鏈表越前面的node就表示里本node越近,越后面的node就離本node越遠。
而在32位系統中,每個node有3個zone,分別是ZONE_HIGHMEM、ZONE_NORMAL、ZONE_DMA。每個區管理的內存數量不一樣,導致每個區的優先級不同,優先級為ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA,對于進程使用的頁,系統優先分配ZONE_HIGHMEM的頁框,如果ZONE_HIGHMEM無法分配頁框,則從ZONE_NORMAL進行分配,當然,對于內核使用的頁來說,大部分只會從ZONE_NORMAL和ZONE_DMA進行分配,這樣,將這個zone優先級與node鏈表結合,就得到zonelist鏈表了,比如對于node0,它完整的zonelist鏈表就可能如下:
node0的管理區 node1的管理區
ZONE_HIGHMEM(0) -> ZONE_NORMAL(0) -> ZONE_DMA(0) -> ZONE_HIGHMEM(1) -> ZONE_NORMAL(1) -> ZONE_DMA(1)
因為每個node都有自己完整的zonelist鏈表,所以對于node1,它的鏈表時這樣的
node1的管理區 node0的管理區
ZONE_HIGHMEM(1) -> ZONE_NORMAL(1) -> ZONE_DMA(1) -> ZONE_HIGHMEM(0) -> ZONE_NORMAL(0) -> ZONE_DMA(0)
這樣得到了兩個node自己的zonelist,但是在內存分配中,還不一定會使用node自己的zonelist,因為有些內存只希望從ZONE_NORMAL和ZONE_DMA中進行分配,所以,在每次進行內存分配時,都會此次內存分配形成一個滿足的zonelist,比如:某次內存分配在node0的CPU上執行了,希望從ZONE_NORMAL和ZONEDMA區中進行分配,那么就會形成下面這個鏈表
node0的管理區 node1的管理區
ZONE_NORMAL(0) -> ZONE_DMA(0) -> ZONE_NORMAL(1) -> ZONE_DMA(1)
這樣就是preferred_zone和zonelist,preferred_zone一般都是指向zonelist中的第一個zone,當然這個還會跟nodemask有關,這個就不細說了。4.4掃描控制結構
之前說內存壓縮的文章也有涉及這個結構,現在詳細說明一下,掃描控制結構用于內存回收和內存壓縮,它的主要作用時保存對一次內存回收或者內存壓縮的變量和參數,一些處理結果也會保存在里面,結構如下:
/* 掃描控制結構,用于內存回收和內存壓縮 */
struct scan_control {
/* 需要回收的頁框數量 */
unsigned long nr_to_reclaim;
/* 申請內存時使用的分配標志 */
gfp_t gfp_mask;
/* 申請內存時使用的order值,因為只有申請內存,然后內存不足時才會進行掃描 */
int order;
/* 允許執行掃描的node結點掩碼 */
nodemask_t *nodemask;
/* 目標memcg,如果是針對整個zone進行的,則此為NULL */
struct mem_cgroup *target_mem_cgroup;
/* 掃描優先級,代表一次掃描(total_size >> priority)個頁框
* 優先級越低,一次掃描的頁框數量就越多
* 優先級越高,一次掃描的數量就越少
* 默認優先級為12
*/
int priority;
/* 是否能夠進行回寫操作(與分配標志的__GFP_IO和__GFP_FS有關) */
unsigned int may_writepage:1;
/* 能否進行unmap操作,就是將所有映射了此頁的頁表項清空 */
unsigned int may_unmap:1;
/* 是否能夠進行swap交換,如果不能,在內存回收時則不掃描匿名頁lru鏈表 */
unsigned int may_swap:1;
unsigned int hibernation_mode:1;
/* 掃描結束后會標記,用于內存回收判斷是否需要進行內存壓縮 */
unsigned int compaction_ready:1;
/* 已經掃描的頁框數量 */
unsigned long nr_scanned;
/* 已經回收的頁框數量 */
unsigned long nr_reclaimed;
};結構很簡單,主要就是保存一些參數,在內存回收和內存壓縮時就會根據這個結構中的這些參數,做不同的處理,后面代碼會詳細說明。這里我們只說說會幾個特別的參數:
- priority:優先級,這個參數主要會影響內存回收時一次掃描的頁框數量、在shrink_lruvec()中回收到足夠頁框后是否繼續回收、內存回收時的回寫、是否取消對zone進行回收判斷而直接開始回收,一共四個地方。
- may_unmap:是否能夠進行unmap操作,如果不能進行unmap操作,就只能對沒有進程映射的頁進行回收。
- may_writepage:是否能夠進行將頁回寫到磁盤的操作,這個值會影響臟的文件頁與匿名頁lru鏈表中的頁的回收,如果不能進行回寫操作,臟頁和匿名頁lru鏈表中的頁都不能進行回收(已經回寫完成的頁除外,后面解釋)
- may_swap:能否進行swap交換,同樣影響匿名頁lru鏈表中的頁的回收,如果不能進行swap交換,就不會對匿名頁lru鏈表進行掃描,也就是在本次內存回收中,完全不會回收匿名頁lru鏈表中的頁(進程堆、棧、shmem共享內存、匿名mmap共享內存使用的頁)
在快速內存回收、直接內存回收、kswapd內存回收中,這幾個值的設置不一定會一致,也導致了它們對不同類型的頁處理方式也不同。除了sc->may_writepage會影響頁的回寫外,還有進行內存分配時使用的分配標志gfp_mask中的__GFP_IO和__GFP_FS會影響頁的回寫,具體如下:
- 掃描到的非活動匿名頁lru鏈表中的頁如果還沒有加入到swapcache中,需要有__GFP_IO標記才允許加入swapcache和回寫。
- 掃描到的非活動匿名頁lru鏈表中的頁如果已經加入到了swapcache中,需要有__GFP_FS才允許進行回寫。
- 掃描到的非活動文件頁lru鏈表中的頁需要有__GFP_FS才允許進行回寫。
這里還需要說說三個重要的內核配置:
/proc/sys/vm/zone_reclaim_mode這個參數只會影響快速內存回收,其值有三種,
- 0x1:開啟zone的內存回收
- 0x2:開啟zone的內存回收,并且允許回寫
- 0x4:開啟zone的內存回收,允許進行unmap操作
當此參數為0時,會導致快速內存回收只會對最優zone附近的幾個需要進行內存回收的zone進行內存回收(說快速內存會解釋),而只要不為0,就會對zonelist中所有應該進行內存回收的zone進行內存回收。
當此參數為0x1(001)時,就如上面一行所說,允許快速內存回收對zonelist中所有應該進行內存回收的zone進行內存回收。
當此參數為0x2(010)時,在0x1的基礎上,允許快速內存回收進行匿名頁lru鏈表中的頁的回寫操作。
當此參數0x4(100)時,在0x1的基礎上,允許快速內存回收進行頁的unmap操作。
/proc/sys/vm/laptop_mode此參數只會影響直接內存回收,只有兩個值:
- 0:允許直接內存回收對匿名頁lru鏈表中的頁進行回寫操作,并且允許直接內存回收喚醒flush內核線程
- 非0:直接內存回收不會對匿名頁lru鏈表中的頁進行回寫操作
/proc/sys/vm/swapiness此參數影響進行內存回收時,掃描匿名頁lru鏈表和掃描文件頁lru鏈表的比例,范圍是0~200,系統默認是30:
- 接近0:進行內存回收時,更多地去掃描文件頁lru鏈表,如果為0,那么就不會去掃描匿名頁lru鏈表。
- 接近200:進行內存回收時,更多地去掃描匿名頁lru鏈表。
五、內存回收實現方式
5.1頁面回收與LRU算法
頁面回收是 Linux 內存回收機制的基礎環節,其核心在于精準地識別并釋放那些不再被頻繁使用的內存頁面,而 LRU(Least Recently Used)算法則在這一過程中扮演著 “篩選器” 的關鍵角色 。LRU 算法基于一個簡單而有效的假設:如果一個頁面在過去很長一段時間內都未被訪問,那么在未來的短時間內,它被訪問的概率也相對較低。這就好比圖書館里的書籍,如果某本書籍長時間無人借閱,那么在接下來的一段時間里,它被借閱的可能性也不大,就可以考慮將其從常用書架上移除,為其他更受歡迎的書籍騰出空間。
在 Linux 系統中,內核通過維護一個雙向鏈表來實現 LRU 算法。鏈表中的每個節點都代表一個內存頁面,每當一個頁面被訪問時,它就會被移動到鏈表的頭部,表示它是最近被使用的頁面;而鏈表尾部的頁面則是最近最少使用的,當系統需要回收內存時,就會優先從鏈表尾部選擇頁面進行回收 。以瀏覽器的頁面緩存為例,當我們頻繁瀏覽不同的網頁時,瀏覽器會將最近訪問的網頁頁面緩存到內存中,采用 LRU 算法管理這些緩存頁面。
如果內存不足,瀏覽器就會將鏈表尾部,也就是那些長時間未被訪問的網頁頁面緩存回收,釋放出內存空間,以便緩存新的網頁頁面,確保瀏覽器能夠高效運行。通過這種方式,LRU 算法能夠有效地管理內存頁面,使得系統能夠及時回收不再使用的頁面,將釋放的內存重新分配給其他急需內存的進程,從而提高內存的使用效率,保障系統的穩定運行。
5.2頁面交換:內存與磁盤的 “互動”
頁面交換是 Linux 內存回收機制應對內存不足的重要手段,它建立在虛擬內存技術的基礎之上,實現了內存與磁盤之間的數據交換,就像在倉庫與臨時存儲點之間搬運貨物,以解決倉庫空間不足的問題。當系統內存緊張時,那些不活躍的頁面,也就是長時間未被訪問的頁面,會被操作系統視為 “暫時不需要的貨物”,從物理內存中移出,交換到磁盤上的交換分區(Swap Partition)中,這個過程被稱為 “換出”(Swap Out) 。交換分區就像是內存的 “備份倉庫”,專門用于存儲這些被換出的頁面。
當這些被換出的頁面在未來某個時刻又需要被訪問時,操作系統會將其從交換分區重新調入內存,這個過程被稱為 “換入”(Swap In) 。在 Linux 系統中,頁面交換由內核的頁替換算法自動執行,常見的算法如 LRU 算法在這一過程中發揮著重要作用,它幫助系統確定哪些頁面是最不活躍的,應該被優先換出 。例如,當我們在使用 Linux 系統進行多任務處理時,同時運行多個大型程序,隨著內存逐漸被占用,系統會將一些暫時不使用的程序頁面換出到交換分區,如后臺運行的數據庫程序中一些不常用的數據頁面。
當這些程序再次需要這些頁面時,系統又會及時將它們從交換分區換入內存,確保程序能夠正常運行。雖然頁面交換機制有效地增加了系統的可用內存,但頻繁的頁面交換會導致系統的磁盤 I/O 負載過高,因為磁盤的讀寫速度遠遠低于內存,這就好比頻繁地在倉庫與臨時存儲點之間搬運貨物,會耗費大量的時間和精力,進而影響系統的響應速度。因此,在實際應用中,需要合理地設置交換分區的大小和內核的頁面交換算法,以及優化系統的內存使用方式,以避免過度使用交換分區,保障系統的性能。
5.3內存壓縮:向空間要效率
內存壓縮是 Linux 內存回收機制中一項旨在提高內存使用效率、減少磁盤 I/O 的創新技術,它通過運用高效的壓縮算法,對那些不活躍的頁面進行壓縮處理,從而在有限的內存空間中存儲更多的數據,就像將蓬松的物品壓縮成緊湊的狀態,以節省存儲空間。當系統內存不足時,傳統的頁面交換機制會將不活躍頁面寫入磁盤交換分區,這一過程伴隨著大量的磁盤 I/O 操作,嚴重影響系統性能。而內存壓縮機制則另辟蹊徑,它將不活躍頁面在內存中直接進行壓縮,然后存儲在內存的特定區域,避免了頻繁的磁盤 I/O 。
在 Linux 系統中,內存壓縮機制通常借助 zRAM 等技術來實現。zRAM 虛擬出一個塊設備,當系統觸發內存回收時,會先從系統中查找不活躍的內存頁面,然后將這些頁面發送到 zRAM 設備。zRAM 設備接收到頁面后,會使用特定的壓縮算法,如 lzo、lz4 等對頁面進行壓縮,將壓縮后的數據存儲在內存中 。當進程需要訪問這些被壓縮的頁面時,系統會先從 zRAM 設備中讀取壓縮數據,然后進行解壓縮,將解壓縮后的頁面重新放置在內存中供進程使用 。
以手機系統為例,在運行多個應用程序時,內存資源容易緊張。采用內存壓縮機制后,系統可以將后臺應用程序中不活躍的頁面進行壓縮,如壓縮圖片處理應用在后臺時占用的大量圖像數據頁面,將其壓縮后存儲在內存中,為前臺運行的應用程序騰出更多內存空間,同時避免了將這些頁面交換到磁盤,減少了磁盤 I/O 操作,提高了系統的整體性能,使得手機在多任務處理時更加流暢。內存壓縮機制在一定程度上緩解了內存壓力,提高了系統性能,是 Linux 內存回收機制中一項重要的優化技術。
5.4匿名頁面丟棄:特殊情況下的內存釋放
匿名頁面丟棄是 Linux 內存回收機制在特定情況下采取的一種內存釋放策略,主要針對那些不屬于文件系統緩存的匿名頁面,這些頁面通常由進程的堆棧和堆分配產生,就像臨時搭建的帳篷,在不需要時可以拆除以騰出空間。當系統內存極度緊張,且其他內存回收機制無法滿足內存需求時,匿名頁面丟棄機制就會啟動 。
在這種情況下,操作系統會對匿名頁面進行評估,選擇那些可以安全丟棄的頁面。對于進程堆棧和堆分配的匿名頁面,如果這些頁面中的數據在后續操作中可以重新生成,或者對進程的正常運行沒有直接影響,那么它們就有可能被丟棄 。例如,在一些計算密集型的進程中,堆棧中可能會臨時存儲一些中間計算結果,這些結果在計算完成后可以通過重新計算得到,當系統內存不足時,這些匿名頁面就可以被丟棄,釋放出內存空間 。
不過,匿名頁面丟棄機制的實施需要謹慎,因為錯誤地丟棄關鍵的匿名頁面可能會導致進程崩潰或數據丟失。因此,Linux 系統在執行匿名頁面丟棄操作時,會嚴格遵循一定的規則和條件,確保丟棄的頁面不會對系統和進程的正常運行造成損害 。匿名頁面丟棄機制為 Linux 系統在極端內存壓力下提供了一種有效的內存釋放手段,保障了系統的基本運行和關鍵進程的正常執行 。