Python中的垃圾回收機制
GC作為現代編程語言的自動內存管理機制,專注于兩件事:1. 找到內存中無用的垃圾資源 2. 清除這些垃圾并把內存讓出來給其他對象使用。GC徹底把程序員從資源管理的重擔中解放出來,讓他們有更多的時間放在業務邏輯上。但這并不意味著碼農就可以不去了解GC,畢竟多了解GC知識還是有利于我們寫出更健壯的代碼。

引用計數
Python語言默認采用的垃圾收集機制是『引用計數法 Reference Counting』,該算法最早George E. Collins在1960的時候***提出,50年后的今天,該算法依然被很多編程語言使用,『引用計數法』的原理是:每個對象維護一個 ob_ref 字段,用來記錄該對象當前被引用的次數,每當新的引用指向該對象時,它的引用計數ob_ref加1,每當該對象的引用失效時計數ob_ref減1,一旦對象的引用計數為0,該對象立即被回收,對象占用的內存空間將被釋放。它的缺點是需要額外的空間維護引用計數,這個問題是其次的,不過最主要的問題是它不能解決對象的“循環引用”,因此,也有很多語言比如Java并沒有采用該算法做來垃圾的收集機制。
什么是循環引用?A和B相互引用而再沒有外部引用A與B中的任何一個,它們的引用計數雖然都為1,但顯然應該被回收,例子:
- a = { } #對象A的引用計數為 1
- b = { } #對象B的引用計數為 1
- a['b'] = b #B的引用計數增1
- b['a'] = a #A的引用計數增1
- del a #A的引用減 1,***A對象的引用為 1
- del b #B的引用減 1, ***B對象的引用為 1

在這個例子中程序執行完 del 語句后,A、B對象已經沒有任何引用指向這兩個對象,但是這兩個對象各包含一個對方對象的引用,雖然***兩個對象都無法通過其它變量來引用這兩個對象了,這對GC來說就是兩個非活動對象或者說是垃圾對象,但是他們的引用計數并沒有減少到零。因此如果是使用引用計數法來管理這兩對象的話,他們并不會被回收,它會一直駐留在內存中,就會造成了內存泄漏(內存空間在使用完畢后未釋放)。為了解決對象的循環引用問題,Python引入了標記-清除和分代回收兩種GC機制。
標記清除
『標記清除(Mark—Sweep)』算法是一種基于追蹤回收(tracing GC)技術實現的垃圾回收算法。它分為兩個階段:***階段是標記階段,GC會把所有的『活動對象』打上標記,第二階段是把那些沒有標記的對象『非活動對象』進行回收。那么GC又是如何判斷哪些是活動對象哪些是非活動對象的呢?
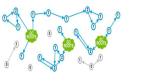
對象之間通過引用(指針)連在一起,構成一個有向圖,對象構成這個有向圖的節點,而引用關系構成這個有向圖的邊。從根對象(root object)出發,沿著有向邊遍歷對象,可達的(reachable)對象標記為活動對象,不可達的對象就是要被清除的非活動對象。根對象就是全局變量、調用棧、寄存器。

在上圖中,我們把小黑圈視為全局變量,也就是把它作為root object,從小黑圈出發,對象1可直達,那么它將被標記,對象2、3可間接到達也會被標記,而4和5不可達,那么1、2、3就是活動對象,4和5是非活動對象會被GC回收。
標記清除算法作為Python的輔助垃圾收集技術主要處理的是一些容器對象,比如list、dict、tuple,instance等,因為對于字符串、數值對象是不可能造成循環引用問題。Python使用一個雙向鏈表將這些容器對象組織起來。不過,這種簡單粗暴的標記清除算法也有明顯的缺點:清除非活動的對象前它必須順序掃描整個堆內存,哪怕只剩下小部分活動對象也要掃描所有對象。
分代回收
分代回收是一種以空間換時間的操作方式,Python將內存根據對象的存活時間劃分為不同的集合,每個集合稱為一個代,Python將內存分為了3“代”,分別為年輕代(第0代)、中年代(第1代)、老年代(第2代),他們對應的是3個鏈表,它們的垃圾收集頻率與對象的存活時間的增大而減小。新創建的對象都會分配在年輕代,年輕代鏈表的總數達到上限時,Python垃圾收集機制就會被觸發,把那些可以被回收的對象回收掉,而那些不會回收的對象就會被移到中年代去,依此類推,老年代中的對象是存活時間最久的對象,甚至是存活于整個系統的生命周期內。同時,分代回收是建立在標記清除技術基礎之上。分代回收同樣作為Python的輔助垃圾收集技術處理那些容器對象。