深入剖析 CPU、內存與 I/O 瓶頸

今天我們開始學習《性能優化》專欄的第02章:深入剖析 CPU、內存與 I/O 瓶頸。
在計算機系統里,各個組件的運行速度參差不齊,當計算機系統的短板存在時,往往會導致性能瓶頸。例如,CPU 負載過高時,任務就會排隊,進而延遲執行。而在大多數情況下,CPU、內存和 I/O 這三大組件是系統最容易成為瓶頸的部分。接下來,我們就一起從CPU、內存與IO角度深入分析系統的性能瓶頸。
CPU 性能
作為計算機最重要的計算單元,中央處理器(CPU)在系統中的作用是非常重要的。評估 CPU 性能時,通常通過以下幾種方法:
Top命令查看CPU性能
通過 top 命令可以實時查看 CPU 的使用情況,按 1 鍵后,我們可以看到每個 CPU 核心的運行情況。

核心指標包括:
us:用戶態所占的 CPU 百分比,表示應用程序占用的 CPU 時間。sy:內核態所占的 CPU 百分比,表示操作系統內核執行的任務所占的 CPU 時間。ni:高優先級應用所占的 CPU 百分比。wa:等待 I/O 設備所占的 CPU 百分比,過高的wa值通常意味著 I/O 設備存在瓶頸。hi:硬中斷占用的 CPU 百分比。si:軟中斷占用的 CPU 百分比。st:表示虛擬機對宿主機的影響。id:空閑 CPU 百分比,反映了 CPU 的使用情況。
負載分析任務排隊
通過 uptime 命令可以查看系統的負載情況,負載反映了系統任務的排隊情況,例如,使用uptime命令可以顯示最近1min、5min和15min的數據。

通過反復測試,可以得出如下結論:
- 單核負載為 1 表示 CPU 剛好達到極限。
- 雙核負載為 2 表示每個核心的負載都接近極限。
- 在多核系統中,負載值達到核數時,系統仍能正常工作,但如果超出核數,任務開始排隊,系統性能就會下降。
vmstat 命令查看CPU繁忙程度
vmstat 命令可以幫助我們了解 CPU 的繁忙程度。

需要特別注意以下幾個關鍵指標:
b:表示阻塞的進程,如果系統有負載問題,可以關注下這個指標,通常意味著有大量的 I/O 操作。si/so:表示交換區(Swap)的使用情況,過多的交換操作會嚴重影響性能。cs:表示每分鐘上下文切換次數,頻繁的上下文切換會降低系統性能,需要考慮進程或者線程是否開啟的過多。
內存性能
內存對于系統性能的影響同樣不可忽視,尤其是在程序運行過程中,內存的管理和分配直接影響著系統的響應速度和穩定性。

操作系統通常會將邏輯內存映射到物理內存和虛擬內存中,系統可用的內存是物理內存與虛擬內存之和。
top 命令內存監控

在 top 命令的輸出中,我們通常關注以下幾個字段:
VIRT:虛擬內存總量,通常較大,但不需要過多關注。RES:實際占用的內存,反映了進程真正使用的內存量。SHR:共享內存,通常為可以被多個進程共享的內存區域。
CPU 緩存
CPU 與內存之間存在巨大的速度差異,因此設計了多級緩存來加速數據的訪問。不同的 CPU 核心通常會有不同層次的緩存(如 L1、L2、L3 緩存)。

在并發編程中,涉及 CPU 緩存的常見問題之一是“偽共享”。偽共享指的是在這些高速緩存中,以緩存行為單位進行存儲,即使修改緩存行中一個非常小的數據,都會刷新整個緩存行。所以,當多線程修改一些變量的值時,如果這些變量都在同一個緩存行里,就會造成頻繁刷新,影響彼此的性能。
HugePage
在CPU與內存的整體架構上,存在一個TLB組件。

這個TLB組件速度很快,但容量非常有限,在普通機器上沒有性能瓶頸。如果機器配置比較高,物理內存比較大,就會產生非常多的映射表,降低CPU的檢索性能。
在大內存機器上,為了提高 CPU 對大內存的訪問效率,通常會采用較大的頁(HugePage),這有助于減少映射表的數量,提高內存管理的效率。
需要注意的是:開啟 HugePage 可能會導致內存競爭的加劇,因此需要根據實際情況進行調整。
提前分配內存
對于Java來說,可以在程序啟動的時候就將內存分配好。例如,配置了JVM的Xms、Xmx和Xmn等參數,指定堆的初始化大小、最大大小等,但是默認是在程序真正使用時,才會分配內存。如果在啟動時加上-XX:+AlwaysPreTouch參數,JVM在啟動時就會分配好內存。程序雖然啟動變慢,但會提高運行時的性能。
I/O 性能
I/O 設備是計算機中最慢的部分,尤其是硬盤,其讀寫速度遠低于 CPU 和內存的速度。為了提高 I/O 性能,我們通常需要采取一些手段進行優化。
iostat 命監控磁盤 I/O
最能體現 I/O 繁忙程度的,就是 top 命令和 vmstat 命令中的 wa%。如果程序正在輸出大量的日志,I/O wait 就可能非常高。
top命令執行結果如下:

iostat命令一般可以通過sysstat包進行安裝,在命令行執行iostat -x 1 3執行結果如下:

關鍵指標包括:
%util:表示磁盤的使用率,通常超過 80% 表示磁盤負載很高。avgqu-sz:表示平均請求隊列長度,越小越好。await:表示磁盤請求的平均響應時間,通常應小于 5ms。svctm:表示每次 I/O 操作的平均服務時間,與await密切相關。
零拷貝技術
硬盤上的數據,在發往網絡之前,需要經過多次緩沖區的拷貝,以及用戶空間和內核空間的多次切換。如果能減少一些拷貝的過程,效率就能提升,所以零拷貝應運而生。
零拷貝是一種非常重要的性能優化手段,比如常見的 Kafka、Nginx 等,就使用了這種技術。
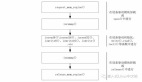
無零拷貝流程
如果沒有零拷貝技術,想要將一個文件通過Socket發送出去,整體流程如下圖所示。

整體流程如下:
(1)將文件內容拷貝到內核緩沖區。
(2)將內核緩沖區的數據拷貝到用戶空間內存。
(3)將用戶空間內存中的數據寫入到內核緩沖區。
(4)Socket讀取內核緩沖區的數據并發送。
零拷貝流程
這里以sendfile為例,零拷貝流程如下圖所示。

采用零拷貝技術后,少了一個步驟,那就是內核緩存不再向用戶空間拷貝數據,不僅節省了內存空間,也節省了CPU的調度時間,讓整體效率更加高效。
本章總結
本章主要深入探討了影響計算機性能的三個關鍵組件:CPU、內存和 I/O。通過命令行工具(如 top、vmstat、iostat 等),可以監控這些組件的性能,從而發現潛在的瓶頸。然而,單純的監控只能幫助我們大致判斷性能問題的位置,若要精確定位性能瓶頸,還需進行更深入的分析與排查。
希望本章的內容能夠讓大家真正學到有用的知識,我們一起努力徹底吃透性能優化技術。