高效處理文本:grep、sed、awk
前言
在Linux系統中,文本處理是日常運維和開發工作中的常見任務。grep、sed和awk這三個工具堪稱文本處理領域的三劍客,它們功能強大且各有所長,熟練掌握它們能顯著提升工作效率。
grep:文本搜索利器
概述
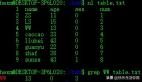
grep是用于在文本文件中搜索指定模式的命令行工具,它支持使用正則表達式進行匹配,并默認輸出匹配的整行內容。在日志分析和文本信息提取場景中,grep應用廣泛,比如從大量日志文件里精準找出錯誤信息或特定事件記錄。
原理
grep工作時,首先從指定文件或標準輸入逐行讀取數據,接著采用正則表達式對每行數據進行模式匹配,一旦匹配成功就將該行輸出。
語法與選項
基本語法為:grep [options] pattern [file...] ,其中options是可選參數,pattern是必填的搜索模式,file是要搜索的文件或目錄(可多個)。常見選項如下:
 圖片
圖片
示例
- 忽略大小寫搜索:查找系統日志中包含
warning(不區分大小寫)的行,命令為grep -i warning /var/log/syslog - 遞歸查詢:在項目代碼目錄中遞歸查找包含
database的文件行,命令為grep -ir database /home/user/project/src - 擴展正則表達式搜索:查找文件中符合特定日期格式(如
YYYY-MM-DD)的行,命令為grep -E '[0-9]{4}-[0-9]{2}-[0-9]{2}' data.txt - 反向匹配:過濾掉配置文件中的注釋和空行,命令為
grep -Ev '^#|^$' /etc/httpd/conf/httpd.conf - 顯示行號:找出用戶配置文件中包含
username或password的行號,命令為grep -En 'username|password' ~/.config/user.conf - 查找文件名:查找當前目錄下包含
error的文件名,命令為grep -l error * - 輸出匹配行前后內容:查找郵件日志中包含
spam的行及其前后2行,命令為grep -iC 2 spam /var/log/mail.log
sed:文本編輯大師
概述
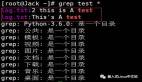
sed是一款流編輯器,支持在文件中進行文本替換、刪除、添加等操作,并且支持基礎和擴展正則表達式,提供豐富文本處理功能,如替換命令、地址定界等。在批量替換文本、修改配置文件以及結合其他命令實現復雜文本處理任務方面,sed表現出色。
原理
sed從輸入流讀取一行內容并存入臨時緩沖區(模式空間),然后依據設定的命令在模式空間執行編輯操作,最后將處理后的內容輸出到標準輸出。
語法與選項
基本語法為:sed [option] 'sed command' file 。常用選項包括:


示例
先復制/etc/hosts文件到/tmp下作為測試文件:cp /etc/hosts /tmp/hosts。
增加操作
a是追加內容到指定行后面,i是插入內容到指定行前面
# 在第一行前面插入# This is a comment并修改文件
sed -i '1i # This is a comment' /tmp/hosts
# 在最后一行后面追加::1 localhost ipv6 - localhost ipv6 - loopback
sed -i '$a ::1 localhost ipv6 - localhost ipv6 - loopback' /tmp/hosts刪除操作
# 刪除第一行
sed -i '1d' /tmp/hosts
# 刪除4 - 6行
sed -i '4,6d' /tmp/hosts
# 刪除匹配127.0.0.1
sed -i '/127.0.0.1/d' /tmp/hosts
# 刪除以#開頭的注釋行
sed -i '/^#/d' /tmp/hosts
# 刪除文件中的空行
sed -i '/^$/d' /tmp/hosts更改操作
替換操作常用模板為sed -i 's#目標內容#替換內容#g' file
#將文件中的example.com替換為new-example.com
sed -i 's#example.com#new-example.com#g' /tmp/hosts
sed -i 's/new-example.com/new-example.com/g' /tmp/hosts
# 該行所有192.168替換為10.0
sed -i '/^192.168./{s#192.168.#10.0.#g}' /tmp/hosts查找操作
# 打印`/tmp/hosts`文件第五行內容
sed -n '5p' /tmp/hostsawk:數據處理專家
概述
awk是編程語言工具,擅長處理數據和生成報告,可按行和列分析文本文件,并對符合條件的數據執行操作。其數據來源廣泛,包括標準輸入、管道或文件,尤其適用于處理結構化文本數據,如日志文件、CSV文件等。
原理
awk工作分為三個主要部分:BEGIN塊、主循環體和END塊。
BEGIN塊代碼在處理輸入行前執行且僅執行一次,常用于初始化變量或打印表頭;- 主循環體逐行讀取輸入文件,按指定分隔符(默認為空格或制表符)將每行分割成字段并存入內建變量;
END塊代碼在所有輸入行處理完畢后執行且僅執行一次,常用于輸出最終結果或總結信息。實
際使用時,可根據需求選擇使用相應部分。具體工作流程為讀入一行數據存入內存,按命令對每行數據執行操作,不斷重復直至文件結束。
語法與選項
基本語法為:awk [options] 'pattern {action}' file 。可選項如下:
 圖片
圖片
 圖片
圖片
示例
以/tmp/employee.csv文件(格式為姓名,年齡,部門,薪資)為例:
# 輸出全文并附帶行號
awk '{print NR,$0}' /tmp/employee.csv
# 只打印第三行
awk 'NR==3{print}' /tmp/employee.csv
# 以 “,” 為分隔符,打印姓名列
awk -F ","'{print $1}' /tmp/employee.csv
# 打印年齡列和薪資列
awk -F ","'{print $2,$3}' /tmp/employee.csv
# 打印薪資大于 5000 的員工姓名和薪資
awk -F ","'$3 > 5000{print $1,$3}' /tmp/employee.csv
# 打印薪資等于5000的員工信息
awk -F ","'$3 == 5000{print $0}' /tmp/employee.csv
# 按特定格式輸出員工信息
awk -F ","'{print "員工 " $1 ",年齡 " $2 ",薪資 " $3 }' /tmp/employee.csv最后
grep、sed和awk在Linux文本處理工作中作用巨大,它們既可以單獨使用,解決各類簡單或復雜的文本處理需求,也能相互配合形成更強大的文本處理 “組合拳”。建議大家在日常工作中多實踐,熟練掌握這些工具,提升工作效率。