譯者 | 劉汪洋
審校 | 重樓
當 LLM 第一次給出的結果不滿意時,你會怎么辦?重新生成一次,對嗎?如果把這個過程自動化,大概就是這樣:
success = false
// 判斷是否成功
while not success:
// 重新生成結果
response = prompt.invoke()
// 評估結果質量
success = evaluate(response)這種做法已在代碼領域得到應用,只要 evaluate() 函數設計得當,同樣的方法也能用于非代碼內容。現在你不僅可以用 LLM 來生成內容,也可以用它來評估內容質量。不過,僅僅使用簡單的 while 循環來等待隨機產生的最佳結果往往是不夠的。有時候你需要調整提示詞,嘗試不同方法,甚至需要進行組合。你得跟蹤什么有用、什么沒用,探索各種創意路徑,以便保持思路的開放性...
本文將要介紹的是 OpenEvolve[1]——Google AlphaEvolve 論文[2]的開源實現,重點展示如何將其應用于內容創作。它在后臺運用"嘗試組合,探索不同路徑"的方法來優化 LLM 提示。
AlphaEvolve 論文把進化系統應用到了用 LLM 生成代碼上。想了解更多關于這篇論文的精彩成果,可以參考我的另一篇文章 。本質上,在“適者生存”機制下,程序得以混合并持續改進。作者認為這些進化編碼代理能實現研究突破,并展示了幾個結果。
鑒于內容形式的極度多樣性,我認為除了代碼,這種長期、持續的進化過程在高價值內容創作方面也具有巨大潛力。本文會探索如何把同樣的技術應用到非代碼場景,讓 LLM 而不是算法來判斷 LLM 生成方案的效果。我們還會討論如何對結果進行分析。
準備工作
先來搭建一個基礎環境。
LLM 服務器
要使用 OpenEvolve,你需要訪問支持 OpenAI 兼容 API 的 LLM 服務器。你可以注冊 Cerebras(有免費額度)、OpenAI、Google Gemini 或類似服務。如果你有高性能的 GPU,也可以自己搭建服務器,比如用 ollama。你需要選擇至少兩個不同的 LLM 模型:一個參數量較小(例如 40 億參數)和一個參數量較大(例如 170 億參數)的模型。
Python 環境 & Git
我假設你在使用 Linux 系統,并已配置好 Python 環境,你可以在其中創建虛擬環境并從 Python 包索引安裝軟件包。
OpenEvolve 設置
安裝 OpenEvolve,然后準備你自己的項目和提示文件夾:
git clone https://github.com/codelion/openevolve.git
cd openevolve
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
mkdir -p examples/my_project/prompts小提醒:OpenEvolve 目前還是研究項目,代碼庫更新很快。建議密切關注所有更新。
配置設置
創建文件 examples/my_project/config.yaml :
checkpoint_interval: 1
# LLM 配置
llm:
models:
- name: "llama3.1-8b"
weight: 0.8
temperature: 1.5
- name: "llama-4-scout-17b-16e-instruct"
weight: 0.2
temperature: 0.9
evaluator_models:
- name: "llama-4-scout-17b-16e-instruct"
weight: 1.0
temperature: 0.9
api_base: "https://api.cerebras.ai/v1/" # 你的 LLM 服務器 API 基礎 URL
# 提示配置
prompt:
template_dir: "examples/my_project/prompts"
num_top_programs: 0
num_diverse_programs: 0
# 數據庫配置
database:
num_islands: 3
# 評估器配置
evaluator:
timeout: 60
cascade_evaluation: false
use_llm_feedback: true
llm_feedback_weight: 1.0 # (非 LLM 指標以 1 的因子加權)
diff_based_evolution: true
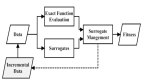
allow_full_rewrites: false為了幫助你理解此處配置的各項參數,我們先來看一下 OpenEvolve 如何生成和評估新解決方案。解決方案包含對應的文本內容,并與評估指標一起存儲在數據庫中。數據庫還會保存"邊信道(side channel)"文本結果,如執行過程中的錯誤信息或文本改進建議。數據庫還存儲精英程序列表以及在不同指標上表現優異的程序(MAP-Elites),從而為新解決方案的生成提供啟發。LLM 基于單個父代生成這些新的、經過變異的解決方案。然后程序化和/或 LLM 評估器判斷新方案,再把結果反饋到數據庫中。
配置選項說明:
- llm: models, evaluator_models 對于生成和評估,你可以配置任意數量的模型。使用多個模型是為了利用快速(弱)模型來探索多種選項,同時借助慢速(強)模型來提升質量。生成時,權重參數控制每個模型在迭代中被選中的概率——在每次迭代中,只會選擇一個模型,而非同時使用多個。評估時,所有模型都會執行,其輸出指標按指定參數加權。 溫度設置影響這些模型的隨機性。1.5 很高,0.9 仍然是高溫度值。對于創意用例,這些設置比較合適。對于商業內容或代碼,建議使用較低的值。OpenEvolve 默認設置是 0.7。
- prompt: template_dir emplate_dir 選項指定了包含用于覆蓋默認值的提示模板的目錄。
- database: num_top_programs, num_diverse_programs 生成新方案的提示可以包括來自數據庫中其他程序的靈感。值為 0 時,此功能被關閉,因為在創意內容進化中,這種靈感(只包括指標和變更摘要,不包括內容本身)作用有限。
- database: num_islands 控制數據庫中維護多少個獨立的子群體。島嶼越多,產生的解決方案路徑越分歧,而在同一島嶼內,你會觀察到較少的實質性變化。對于創意用例,如果你有足夠時間和資源運行很多迭代,增加島嶼數量可能有益。
a.evaluator: llm_feedback_weight 評估 LLM 生成的組合指標乘以此參數。與算法生成的指標一起,用數值平均值找到最佳程序。假設生成的指標是 length: 1.0 llm_correctness: 0.5 llm_style: 0.7,在 llm_feedback_weight 為 1.0 的情況下,總分將是 (1.0+0.51.0+0.71.0)/3
- diff_based_evolution / allow_full_rewrites: 支持生成器 LLM 的兩種不同提示方法。diff 模式下,LLM 用搜索和替換響應格式來替換當前方案中的特定元素。full_rewrite 模式下,LLM 直接輸出完整重寫。后一種模式對能力較弱的 LLM 負擔較輕,但也不太適合處理長內容。根據我的測試,diff 模式質量也更好。
更多選項請參考 configs/default_config.yaml。
提示設置
OpenEvolve 的默認提示是為代碼進化寫的。所以默認情況下,它們不適用于非代碼生成。好在我們可以覆蓋它們。默認提示編碼在文件 openevolve/prompt/templates.py 中。
創建以下文件并調整提示來匹配你的用例。我們試試創作詩歌這個簡單例子。
初始占位符內容: examples/my_project/initial_content.txt
沒有初始詩歌,發明你自己的。初始提示代表"第一代"父代,它影響后代,也就是第二代解決方案。對于初始內容,你可以提供現有版本或空占位符文本。你也可以提供具體指令,比如"確保提到貓",來引導初始生成朝著想要的方向發展。如果你需要為所有生成提供更一般的上下文,把它包含在系統提示中。
系統提示: examples/my_project/prompts/system_message.txt
你是莎士比亞級別的詩歌作家,將內容轉化為美麗的詩歌并進一步改進。系統提示只是為你的生成器模型設置一般上下文,讓它知道你的用例是什么。在這個例子中,我們不是在創建代碼,我們在寫詩。
內容生成的用戶提示: examples/my_project/prompts/diff_user.txt
# 當前解決方案信息
- 當前性能指標:{metrics}
- 識別出的改進項:{improvement_areas}
{artifacts}
# 進化歷史
{evolution_history}
# 當前解決方案
``
{current_program}
``
# 任務
建議對答案的改進,這將在指定指標上帶來更好的性能。你必須使用下面顯示的確切 SEARCH/REPLACE 差異格式來指示更改:
<<<<<<< SEARCH
# 要查找和替換的原始文本(必須完全匹配)
=======
# 新的替換文本
>>>>>>> REPLACE
有效差異格式的示例:
<<<<<<< SEARCH
poem stub
=======
Tyger Tyger, burning bright,
In the forests of the night;
What immortal hand or eye
>>>>>>> REPLACE
你可以建議多個更改。每個 SEARCH 部分必須與當前解決方案中的文本完全匹配。如果解決方案是空白占位符,請確保只響應一個差異替換——搜索現有占位符字符串,將其替換為你的初始解決方案。內容生成用戶提示很通用。它包含幾個占位符,這些占位符會被來自解決方案數據庫的內容替換,包括父程序的評估結果。這個提示說明了進化過程如何影響新解決方案的生成。
不使用 diff 方法的內容生成用戶提示: examples/my_project/prompts/full_rewrite.txt
# 當前解決方案信息
- 當前指標:{metrics}
- 識別出的改進領域:{improvement_areas}
{artifacts}
# 進化歷史
{evolution_history}
# 當前解決方案
``
{current_program}
``
# 任務
重寫答案以提高其在指定指標上的性能。提供完整的新答案。不要在答案后添加推理、更改日志或評論!
# 你的重寫答案在這里進化歷史的提示片段: examples/my_project/prompts/_evolution_history.txt
## 之前的嘗試
{previous_attempts}
## 表現最佳的解決方案
{top_programs}頂級程序的提示片段: examples/my_project/prompts/_top_programs.txt
### 解決方案 {program_number} (分數: {score})
``
{program_snippet}
``
關鍵特征:{key_features}評估器的系統提示: examples/my_project/prompts/evaluator_system_message.txt
你是莎士比亞級別的詩歌作家,正在被要求評審他人的作品。評估器模型的這個系統提示本質上與生成器 LLM 的系統提示相同。
評估器的用戶提示: examples/my_project/prompts/evaluation.txt
評估以下詩歌:
1. 美感:它美麗嗎?
2. 啟發性:它的信息是否富有啟發性和意義?
3. 情感:詩歌是否觸發情感響應?
4. 創造性:它是否具有創造性?
5. 語法:它的語法好嗎?它是否只是詩歌,還是也包含非詩歌內容(如果是,評分為0)?它的行是否過長(如果是,評分低)?
6. 總體分數:給出總體評分。如果詩歌、語法或長度評估不好,給出差的總體反饋。
對于每個指標,提供 0.0 到 1.0 之間的分數,其中 1.0 是最好的。
要評估的答案:
``
{current_program}
``
將你的評估使用 JSON 對象返回,格式如下:
{{
"beauty": score1,
"inspiring": score2,
"emotion": score3,
"creativity": score4,
"syntax": score5,
"overall_score": score6,
"improvement_suggestion": "..",
}}
即使對于無效輸入,也只返回 JSON 對象。這正是關鍵所在。在這個提示中,你必須考慮代表你正在優化的內容質量的指標。考慮決定內容好壞的因素?正確性?幽默?寫作技巧?你需要知道什么更重要,并將其編碼到指標中。在看到進化按你預期的方式收斂之前,可能需要一些實驗。在觀察內容進化的過程中進行嘗試和調整(下文將詳細說明)。
請注意,每個指標的權重是相等的。它們在你的 config.yaml 中乘以 llm_feedback_weight 因子。保持一個 overall_score 指標也是好主意,它提供大局評估的摘要。然后,你可以按它對生成的解決方案進行排序。
improvement_suggestion 是來自評估器 LLM 的文本建議。它會與指標一同存儲在數據庫中,并在該解決方案被用作父代時,作為您之前看到的 {artifacts} 占位符內容的一部分,提供給生成器 LLM。(注意:截至撰寫本文時,文本 LLM 反饋仍然是 OpenEvolve 代碼庫中正在審查的拉取請求,請確保使用支持它的版本。)
評估器程序
OpenEvolve 設計用于使用算法評估器的代碼生成。雖然很難編寫一個判斷詩歌美感的算法,然而,我們仍然可以為內容生成用例設計出有用的算法評估函數。比如,我們可以定義一個針對特定行數或字數的指標。
創建文件 examples/my_project/evaluation.txt:
from openevolve.evaluation_result import EvaluationResult
def linear_feedback(actual, target):
deviation = abs(actual - target) / target
return 1 - min(1.0, deviation)
def evaluate_stage1(file_path):
# 讀取 file_path
with open(file_path, 'r') as file:
content = file.read()
# 計算行數和字數
lines = content.splitlines()
num_lines = len(lines)
num_words = sum(len(line.split()) for line in lines)
# 目標長度
line_target = 5
word_target = line_target*7
# 0(最差)到 1(最好)之間的線性反饋
line_rating = linear_feedback(num_lines, line_target)
word_rating = linear_feedback(num_words, word_target)
combined_rating = (line_rating + word_rating) / 2
# 創建文本反饋
length_comment_parts = []
# 行數反饋
line_ratio = num_lines / line_target
if line_ratio > 1.2:
length_comment_parts.append("減少行數。")
elif line_ratio < 0.8:
length_comment_parts.append("增加行數。")
else:
length_comment_parts.append("行數剛好合適。")
# 每行字數反饋
words_per_line = num_words / num_lines if num_lines else 0
target_words_per_line = word_target / line_target
words_per_line_ratio = words_per_line / target_words_per_line
if words_per_line_ratio > 1.2:
length_comment_parts.append("減少每行的字數。")
elif words_per_line_ratio < 0.8:
length_comment_parts.append("增加每行的字數。")
length_comment = " ".join(length_comment_parts)
return EvaluationResult(
metrics={
"length_good": combined_rating,
},
artifacts={
"length_recommendation": length_comment,
},
)
def evaluate(file_path):
return evaluate_stage1(file_path)這段代碼有兩個方面:首先,它創建一個指標值,用于量化響應長度的質量。如果響應過短或過長,分數會降低。若響應長度恰到好處,分數則達到 1。其次,這段代碼會準備文本反饋,LLM 能夠直觀地理解這些反饋,從而明確需要進行的修改,避免在長度不符合要求時被預設的修改思路所限制。例如,它不會錯誤地認為:"我需要寫更多...和更多..."。
實際操作:進化過程
運行進化過程:
source .venv/bin/activate
export OPENAI_API_KEY="sk-.."
python3 openevolve-run.py \
examples/my_project/initial_program.py \
examples/my_project/evaluator.py \
--config examples/my_project/config.yaml \
--iterations 9最好從少數幾次迭代開始,仔細分析結果以確保一切運行正常。為此,啟動可視化 Web 服務器并實時觀察:
python3 scripts/visualizer.py或者,如果你有要分析的特定過去檢查點,請打開它:
python3 scripts/visualizer.py --path examples/content_writing/openevolve_output/checkpoints/checkpoint_2在改進后重新運行測試時,確保在重新開始之前將當前檢查點文件夾移開:
mkdir -p examples/my_project/archive
mv examples/my_project/openevolve_output/ examples/my_project/archive/如果一切配置正確,你應該看到改進結果的進化。
在可視化前端中,點擊節點查看相關的當前解決方案文本,以及它們的所有指標、提示和 LLM 響應。你也可以在側邊欄中輕松點擊瀏覽子節點。如果你在圖中迷路看不到節點,請使用黃色定位器按鈕。通過觀察提示,您可以追蹤父代的評估響應是如何影響子代的生成用戶提示的。(注意:截至撰寫本文時,提示和響應日志記錄仍然是 OpenEvolve 代碼庫中正在審查的拉取請求,請確保使用支持它的版本。)
如果您希望根據特定指標來比較所有解決方案,請從頂部欄中進行選擇:

指標選擇框顯示你的 evaluation.py 邏輯和 evaluation.txt 提示生成的所有指標。用它可以更改用于確定圖中節點半徑的指標。
- 節點顏色代表著不同的島嶼,在這些島嶼中,進化過程(尤其在長時間運行的情況下)大體上獨立進行并朝著不同的方向發展。偶爾,根據配置中的遷移參數,一個島嶼中的個體可能會被復制到另一個島嶼。
- 每個節點的大小表示其在當前選定指標上的表現。
- 可視化中的邊顯示修改了哪個父代來產生子代。這對其后代的影響最為顯著。
實際上,AlphaEvolve 算法在其提示中融合了來自幾個先前程序的學習(可配置的 top-n 程序)。生成提示會通過包含先前更改及其對結果指標影響的摘要而得到增強。這種"提示交叉"沒有可視化。圖中也未顯示“克隆”關系:當一個解決方案遷移到另一個島嶼時,它會連同所有數據(包括其 ID)一并被復制。這些副本在圖中會顯示為未連接的元素。
無論如何,最佳解決方案會保存到 examples/my_project/openevolve_output/best/best_program.txt:
原始輸出:
In silken moonlight, where night’s veil is lifted, A constellation of dreams is gently shifted, The heart, a canvas, painted with vibrant hues, A symphony of feelings, in tender Muse.
中文譯文: 在絲綢般的月光中,夜幕被輕撫,夢想的星座輕柔地移動,心靈,一塊畫布,用鮮艷的色彩繪制,情感的交響樂,在溫柔的繆斯中。
常見問題
- 能使用我自己的起始提示嗎? 能!只需將你已有的解決方案放入 initial_content.txt 中。
- 可以不創建自己的起始提示嗎? 可以!只需在你的 initial_content.txt 中放入占位符,如"沒有初始詩歌,發明你自己的。確保提到貓。"
- 可以不編寫任何代碼嗎? 可以!如果你不想要算法評估器,請在你的 evaluator.py 中放入這樣的存根:
def evaluate_stage1(file_path):
return {}
def evaluate(file_path):
return evaluate_stage1(file_path)- 可以使用本地或非 OpenAI LLM 嗎? 只要它與 OpenAI API 兼容,都可以!在你的
config.yaml中,將llm: api_base: 更改為類似 "http://localhost:11434/v1/" 的值,用于默認 ollama 配置。在命令行上,在調用 Python 程序之前設置你的 API 密鑰:
export OPENAI_API_KEY="ollama"總結思考
本文描述了一個關于在進化算法中使用 LLM 反饋的實驗,因為 AlphaEvolve 論文本身對此有所提及,并指出他們尚未針對此進行優化。這僅僅是一個開始。這種內容生成方式的投入相對較高,其適用的高價值場景以及后續更多實驗仍有待探索。希望未來這些技術能夠變得更易于使用。
實際結果方面:在實踐中,我發現各項指標的改進只能觀察到某個程度為止。然而,由于LLM的評分不夠細致,很難從中獲取精確的數值指標,因此評分很快就會趨于平穩。更優的提示詞設計,尤其是針對評估器的提示詞,有望改善這一狀況。無論如何,算法評估與LLM評估相結合,配合強大的進化算法和豐富的配置選項,使得這種整體方法極為高效。
為了生成更具說服力的 LLM 指標以證明長期進化過程的價值,可以納入多階段 LLM 評估器管道。這些管道可以總結內容、確保特定事實的存在等。通過從 evaluator.py 文件調用這些管道,OpenEvolve 當前已能實現此功能。
有了知識庫和工具,融合 LLM 反饋的這種進化系統的能力可以進一步擴展。未來,OpenEvolve 若能支持 MCP 服務器將是一個令人期待的擴展。即便如此,目前用戶也已能在 evaluator.py 文件中利用這些功能生成反饋。
該方法也可以應用于多模態 LLM 或單獨的后端 LLM,它在不同模態中生成實際內容,并接受進化系統的提示指令。現有的 MCP 服務器可以生成圖像、音頻等多模態內容。只要我們擁有能夠有效評估結果的 LLM,便可以持續優化提示詞,從而生成新的、更優的后代內容。
綜上所述,在這個令人興奮的框架中,仍有大量實驗等待我們去開展。我期待你的反饋,并熱切希望看到這些實驗的成果。
參考文獻
- Asankhaya Sharma, OpenEvolve: Open-source implementation of AlphaEvolve (2025), Github
- Novikov et al., AlphaEvolve: A Gemini-Powered Coding Agent for Designing Advanced Algorithms (2025), Google DeepMind
譯者介紹
劉汪洋,51CTO社區編輯,昵稱:明明如月,一個擁有 5 年開發經驗的某大廠高級 Java 工程師。
原文標題:Beyond Code Generation: Continuously Evolve Text with LLMs,作者:Julian Mendel